

Con questo Post riprendo la mia "campagna di sensibilizzazione" sulla velocità di convergenza del BGP, sempre con lo scopo di sfatare l'atavico mito "che il BGP converge in tre minuti".
Nei due Post precedenti ho trattato due argomenti: il primo riguarda la velocità con cui viene rilevata la perdita di una sessione BGP, mentre il secondo consente di verificare velocemente la raggiungibilità del Next-Hop.
Questa volta tratterò altri due argomenti, uno sostanzialmente invisibile, ossia che non ha (quasi) impatto alcuno sulle configurazioni, mentre l'altro riguarda una funzionalità che invece va attivata su base configurazione.
Prima di trattare questi due ulteriori argomenti è però necessaria una premessa. Con quali criteri il piano di controllo BGP consente di convergere su un nuovo best-path ?
CONVERGENZA SUL PIANO DI CONTROLLO
In un classico backbone che utilizza una architettura di routing IGP+BGP (non importa se BGP core-free o meno, ossia con l'ulteriore aggiunta di MPLS o no), come quello rappresentato nella figura seguente:
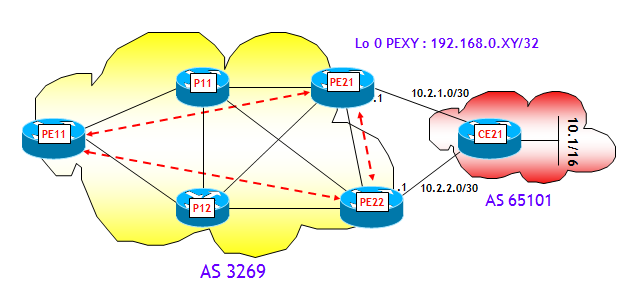
si possono individuare tre scenari di fuori servizio, che comportano la convergenza del BGP su un nuovo best-path:
- Fuori servizio di elementi interni al backbone (router e/o collegamenti).
- Fuori servizio di Edge Router, che da qui in poi, con un piccolo abuso di notazione chiameremo router PE (Provider Edge).
- Fuori servizio di collegamenti PE-CE, dove i router CE (Customer Edge, anche qui stiamo forzando un po' la notazione) sono router esterni al backbone, che scambiano nel nostro esempio informazioni di routing con il backbone via eBGP.
Il primo scenario è rappresentato nella figura seguente:
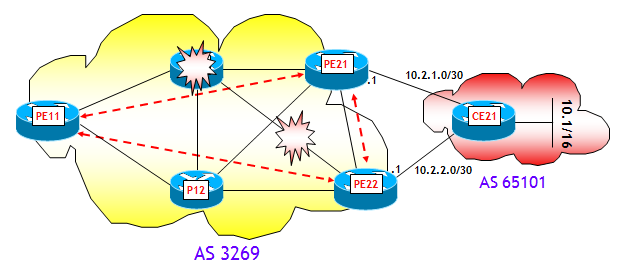
Come avviene la convergenza verso un nuovo best-path ? Ho fatto una piccola prova di laboratorio per mostrare tutti i passi che portano il router PE11 a convergere verso un nuovo best-path, a fronte del fuori servizio del router P11. La rete è costituita da router Cisco con IOS 12.4(11)T. Tra i tre router PE, come mostrato nella figura, vi è una maglia completa di sessioni iBGP, mentre il router CE21 ha due sessioni eBGP verso i due router PE21 e PE22, ai quali annuncia il prefisso 10.1/16. Sui due router PE21 e PE22, ho inoltre attivato la funzione "next-hop self" sulle sessioni iBGP verso PE11. Per rendere la prova più interessante, infine, ho posto la metrica IGP dell'interfaccia del router P12 sul collegamento verso il router PE21, al valore 1.000. Tutte le altre metriche hanno valore 10.
Vediamo dapprima la tabella BGP di PE11:
PE11# show bgp ipv4 unicast 10.1.0.0
BGP routing table entry for 10.1.0.0/16, version 2
Paths: (2 available, best #2, table Default-IP-Routing-Table)
Not advertised to any peer
65101
192.168.0.22 (metric 21) from 192.168.0.22 (192.168.0.22)
Origin IGP, metric 0, localpref 100, valid, internal
65101
192.168.0.21 (metric 21) from 192.168.0.21 (192.168.0.21)
Origin IGP, metric 0, localpref 100, valid, internal, best
Come si può notare, PE11 sceglie come best-path il Next-Hop 192.168.0.21, a causa del più basso valore del BGP router-ID (lascio i dettagli al lettore come utile esercizio).
A questo punto, dopo aver attivato sul router PE11 i comandi "debug ip routing" e "debug ip bgp updates", ho spento completamente il router P11. Come c'era da aspettarsi, il BGP Next-Hop cambia (anche qui, lascio i dettagli al lettore come utile esercizio):
PE11# show bgp ipv4 unicast 10.1.0.0
BGP routing table entry for 10.1.0.0/16, version 3
Paths: (2 available, best #1, table Default-IP-Routing-Table)
Flag: 0x800
Not advertised to any peer
65101
192.168.0.22 (metric 21) from 192.168.0.22 (192.168.0.22)
Origin IGP, metric 0, localpref 100, valid, internal, best
65101
192.168.0.21 (metric 31) from 192.168.0.21 (192.168.0.21)
Origin IGP, metric 0, localpref 100, valid, internal
Questa è la parte interessante dei debug attivati su PE11:
*Nov 16 16:59:06.263: RT: del 192.168.0.21/32 via 172.20.11.11, ospf metric [110/21]
*Nov 16 16:59:06.267: RT: SET_LAST_RDB for 192.168.0.21/32
OLD rdb: via 11.13.11.13,
NEW rdb: via 172.20.13.12
*Nov 16 16:59:06.279: RT: add 192.168.0.21/32 via 172.20.13.12, ospf metric [110/31]
*Nov 16 16:59:06.283: RT: NET-RED 192.168.0.21/32
*Nov 16 16:59:06.299: RT: del 192.168.0.22/32 via 172.20.11.11, ospf metric [110/21]
*Nov 16 16:59:06.303: RT: SET_LAST_RDB for 192.168.0.22/32
OLD rdb: via 11.13.11.13,
NEW rdb: via 172.20.13.12, Serial1/2
*Nov 16 16:59:06.311: RT: NET-RED 192.168.0.22/32
*Nov 16 16:59:11.331: BGP(0): Revise route installing 1 of 1 routes for 10.1.0.0/16 -> 192.168.0.22(main) to main IP table
*Nov 16 16:59:11.335: RT: 10.1.0.0/16 gateway changed from 192.168.0.21 to 192.168.0.22
*Nov 16 16:59:11.339: RT: NET-RED 10.1.0.0/16
Come si può notare, il tempo di convergenza del BGP verso il nuovo BGP Next-Hop 192.168.0.22 (interfaccia Loopback 0 di PE22) è di poco più di 5 sec (di cui 5 sec imputabili al BGP Next-Hop Tracking (NHT) Trigger Delay). Faccio notare che se non avessi cambiato al valore 1.000 la metrica IGP dell'interfaccia del router P12 sul collegamento verso il router PE21, il BGP Next-Hop non sarebbe nemmeno cambiato.
Riassumendo, la sequenza delle operazioni sul router PE11 è la seguente:
- Il protocollo IGP rileva il fuori servizio delle adiacenze stabilite dal router P11 e determina, attraverso una nuova esecuzione dell'algoritmo SPF, i nuovi percorsi ottimi verso i due possibili BGP Next-Hop PE21 e PE22.
- Se il percorso verso il BGP Next-Hop ottimo cambia, il protocollo IGP lo notifica al processo BGP, viceversa non accade niente.
- PE11 identifica tutti gli annunci BGP con il BGP Next-Hop di cui è variato il percorso, e quindi esegue immediatamente un nuovo processo per la selezione del best-path. Questo tempo è proporzionale al numero di prefissi IP annunciati via BGP e potrebbe essere abbastanza lungo.
- Determinato il nuovo best-path, PE11 aggiorna sia RIB che FIB e il traffico continua a fluire, ma su un percorso diverso.
Il secondo scenario prevede il fuori servizio di un router PE, come mostrato nella figura seguente:
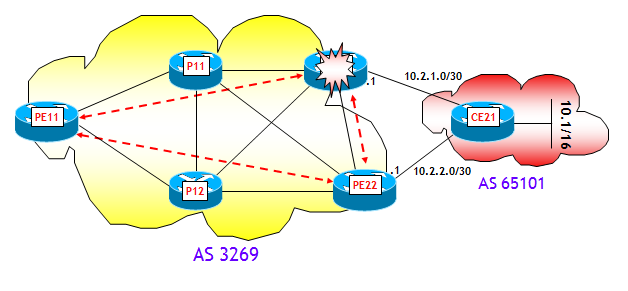
Anche qui ho fatto un test di laboratorio, con la stessa identica configurazione di rete, e dopo aver riportato al valore iniziale 10 la metrica IGP del collegamento P12-->PE21. Inizialmente il best-path per il prefisso 10.1/16 è il router PE21 (per la stessa identica ragione dello scenario precedente; faccio notare che la variazione della metrica del collegamento P12-->PE21 non ha alcuna influenza nella determinazione del best-path, (il perché lo lascio ancora al lettore, che alla fine del Post forse mi odierà per tutto ciò !)):
PE11# show bgp ipv4 unicast 10.1.0.0
BGP routing table entry for 10.1.0.0/16, version 2
Paths: (2 available, best #2, table Default-IP-Routing-Table)
Not advertised to any peer
65101
192.168.0.22 (metric 21) from 192.168.0.22 (192.168.0.22)
Origin IGP, metric 0, localpref 100, valid, internal
65101
192.168.0.21 (metric 21) from 192.168.0.21 (192.168.0.21)
Origin IGP, metric 0, localpref 100, valid, internal, best
A questo punto, dopo aver attivato sul router PE11 gli stessi debug dello scenario precedente, ho spento completamente il router PE21, ossia il BGP Next-Hop ottimo (se avessi spento il router PE22 in luogo del router PE21, non sarebbe accaduto niente in termini di convergenza del BGP). Come c'era da aspettarsi, su PE11 il BGP Next-Hop cambia e il piano di controllo del BGP converge al nuovo (e unico rimasto) BGP Next-Hop 192.168.0.22:
PE11# show bgp ipv4 unicast 10.1.0.0
BGP routing table entry for 10.1.0.0/16, version 7
Paths: (2 available, best #1, table Default-IP-Routing-Table)
Not advertised to any peer
65101
192.168.0.22 (metric 21) from 192.168.0.22 (192.168.0.22)
Origin IGP, metric 0, localpref 100, valid, internal, best
65101
192.168.0.21 (inaccessible) from 192.168.0.21 (192.168.0.21)
Origin IGP, metric 0, localpref 100, valid, internal
Per vedere il tempo impiegato, analizziamo la parte interessante dei debug attivati su PE11:
*Nov 16 17:49:37.023: RT: del 192.168.0.21/32 via 172.20.11.11, ospf metric [110/21]
*Nov 16 17:49:37.027: RT: NET-RED 192.168.0.21/32
*Nov 16 17:49:37.031: RT: del 192.168.0.21/32 via 172.20.13.12, ospf metric [110/21]
*Nov 16 17:49:37.035: RT: delete subnet route to 192.168.0.21/32
*Nov 16 17:49:37.039: RT: NET-RED 192.168.0.21/32
*Nov 16 17:49:42.059: BGP(0): Revise route installing 1 of 1 routes for 10.1.0.0/16 -> 192.168.0.22(main) to main IP table
*Nov 16 17:49:42.063: RT: 10.1.0.0/16 gateway changed from 192.168.0.21 to 192.168.0.22
*Nov 16 17:49:42.067: RT: NET-RED 10.1.0.0/16
Come si può notare, anche in questo caso, il tempo di convergenza del BGP verso il nuovo BGP Next-Hop 192.168.0.22 (interfaccia Loopback 0 di PE22) è di poco più di 5 sec (di cui 5 sec imputabili al BGP NHT Trigger Delay).
Riassumendo, la sequenza delle operazioni sul router PE11 è la seguente:
- Il protocollo IGP rileva la non raggiungibilità del router PE21, che è il BGP Next-Hop ottimo.
- Il protocollo IGP notifica al processo BGP che il percorso verso il router PE21 non è più valido (funzionalità BGP NHT).
- PE11 identifica tutti gli annunci BGP con il BGP Next-Hop non più raggiungibile, e quindi esegue immediatamente un nuovo processo per la selezione del best-path.
- Determinato il nuovo best-path, PE11 aggiorna sia RIB che FIB e il traffico continua a fluire, ma su un percorso diverso.
Prima di passare al terzo scenario, vorrei far notare un aspetto chiave: il tempo di convergenza verso il nuovo BGP Next-Hop, in entrambi gli scenari finora descritti, dipende esclusivamente dalla velocità di convergenza del protocollo IGP. Il piano di controllo BGP interviene solo con il BGP NHT Trigger Delay, che se azzerato non ha alcuna influenza, come visto nel Post precedente sul BGP NHT. Quindi in questi scenari, la velocità di convergenza del BGP è praticamente identica alla velocità di convergenza del protocollo IGP (che se opportunamente configurato, non converge in tre minuti, ma in tempi dell'ordine delle decine o poche centinaia di msec !!!).
Il terzo e ultimo scenario prevede il fuori servizio di un collegamento PE-CE, come mostrato nella figura seguente:
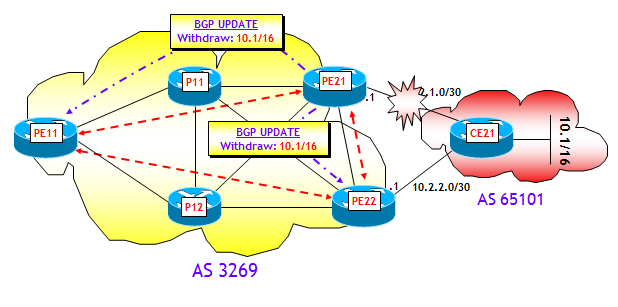
Anche qui ho fatto un test di laboratorio, con la stessa identica configurazione di rete degli scenari precedenti.
Ricordo che sui router PE21 e PE22 è attivo il comando "neighbor <PE11> next-hop-self". Inizialmente il best-path per il prefisso 10.1/16, come visto nella prova dello scenario precedente, è il router PE21.
A questo punto, dopo aver attivato sul router PE11 i soliti debug, ho messo in shutdown l'interfaccia lato PE21 del collegamento PE21-CE21 (si noti che se avessi messo invece in shutdown l'interfaccia lato PE22 del collegamento PE22-CE21, non sarebbe accaduto niente in termini di convergenza del BGP). Come c'era da aspettarsi, su PE11 il BGP Next-Hop cambia e il piano di controllo del BGP converge al nuovo BGP Next-Hop 192.168.0.22:
PE11# show bgp ipv4 unicast 10.1.0.0
BGP table version is 3, local router ID is 192.168.0.11
Status codes: s suppressed, d damped, h history, * valid, > best, i - internal, r RIB-failure, S Stale
Origin codes: i - IGP, e - EGP, ? - incomplete
Network Next Hop Metric LocPrf Weight Path
*>i10.1.0.0/16 192.168.0.22 0 100 0 65101 i
Per vedere il tempo impiegato, analizziamo la parte interessante dei debug attivati su PE11:
*Nov 16 19:08:12.355: BGP(0): 192.168.0.21 rcv UPDATE about 10.1.0.0/16 -- withdrawn
*Nov 16 19:08:12.367: BGP(0): Revise route installing 1 of 1 routes for 10.1.0.0/16 -> 192.168.0.22(main) to main IP table
*Nov 16 19:08:12.371: RT: 10.1.0.0/16 gateway changed from 192.168.0.21 to 192.168.0.22
*Nov 16 19:08:12.375: RT: NET-RED 10.1.0.0/16
L'analisi dei debug consente una prima osservazione molto importante: la velocità di convergenza, a differenza dei due scenari precedenti, non dipende dalla convergenza del protocollo IGP, ma esclusivamente dal piano di controllo BGP. Questo accade a causa della presenza del comando "neighbor <PE11> next-hop-self" sui router PE21 e PE22. Infatti, questo comporta che il router PE11 vede come BGP Next-Hop gli indirizzi 192.168.0.21 (PE21) e 192.168.0.22 (PE22), e non gli indirizzi lato CE dei collegamenti punto-punto PE-CE, per cui il fuori servizio dei collegamenti PE-CE non ha alcun impatto sui BGP Next-Hop visti da PE11. La convergenza avviene quindi solo grazie allo scambio di messaggi BGP. In particolare ciò che avviene è che a fronte dello shutdown dell'interfaccia lato PE21 del collegamento PE21-CE21, grazie alla funzionalità "bgp fast external fall-over" vista nel primo Post sulla convergenza del BGP, la sessione BGP PE21-CE21 viene immediatamente disattivata e quindi PE21 invia ai suoi BGP peer PE11 e PE22, un messaggio BGP UPDATE per ritirare il prefisso 10.1/16 (in generale, tutti i prefissi appresi da CE21). A fronte di ciò, PE11 ricalcola il nuovo best-path (si noti che per PE22 il best-path non cambia !), che come visto sopra, è il Next-Hop 192.168.0.22 (PE22). Anche PE21 ricalcola il nuovo best-path, che anche in questo caso diventa il Next-Hop 192.168.0.22 (PE22). Su PE11 tutto ciò avviene in 20 msec ! (NOTA: in realtà a questo tempo bisognerebbe aggiungere il tempo di generazione del messaggio BGP UPDATE da parte di PE21, e il tempo di propagazione dello stesso da PE21 a PE11, ma sono tempi molto piccoli). Questo tempo di convergenza così piccolo è però ingannevole, perché in generale dipende dal numero di prefissi che CE21 annuncia all'AS 3269. Se CE21 annunciasse l'intera Full Internet Routing Table il discorso sarebbe ben diverso, perché PE21 dovrebbe rieseguire il processo di selezione per centinaia di migliaia di prefissi !
Ribadisco però il punto chiave, la convergenza avviene esclusivamente a livello BGP, la funzionalità BGP NHT in questo caso non aiuta poiché per PE11 il BGP Next-Hop rimane regolarmente nella Tabella di Routing.
Cosa avverrebbe se noi togliessimo il comando "neighbor <PE11> next-hop-self" sui router PE21 e PE22 ? Innanzitutto è necessario redistribuire nel protocollo IGP le subnet IP utilizzate nella numerazione dei collegamenti punto-punto PE-CE, oppure in alternativa farle partecipare al processo IGP (possibilmente con un passive-interface sull'interfaccia lato PE !), altrimenti PE11, vedrebbe i BGP Next-Hop irraggiungibili. Fatto ciò, i BGP Next-Hop diventano gli indirizzi IP lato CE dei collegamenti punto-punto PE-CE. Il fuori servizio del collegamento PE21-CE21 comporta in questo caso che il protocollo IGP ritiri dalla Tabella di Routing di PE11 la subnet IP con cui è numerato il collegamento PE21-CE21, e quindi entra in funzione il BGP NHT. In generale, in topologie con un grande numero di annunci BGP questo comporta indubbiamente un notevole vantaggio in termini di convergenza. Quando invece il numero di annunci BGP è basso, i vantaggi in termini di velocità di convergenza sono compensati dagli svantaggi della redistribuzione della subnet dei collegamenti PE-CE nel protocollo IGP (incremento della memoria necessaria per i LSDB, della dimensione delle Tabelle di Routing, possibili problemi di sicurezza, ecc.).
Riassumendo quanto visto finora, in due dei tre scenari descritti (nel primo e secondo), la velocità di convergenza del BGP dipende essenzialmente dalla velocità di convergenza del protocollo IGP (e questo già sfata il mito che il BGP è molto più lento a convergere dei protocolli IGP), mentre nel terzo dipende dal piano di controllo BGP. In tutti gli scenari comunque, il processo BGP viene avvisato di un cambiamento, e deve effettuare uno scanning della Tabella BGP per individuare tutti i prefissi affetti dal cambiamento. Questo processo di scanning, benché event-driven, comporta un tempo proporzionale al numero di prefissi IP. Il processo potrebbe essere ottimizzato (vedi ad esempio gli scoped walks nell'IOS XR), ma il tempo rimane comunque dipendente dal numero di prefissi annunciati. L'ideale sarebbe avere un processo indipendente dal numero di prefissi, ed è questo che tratteremo nelle prossime sezioni.
FIB FLAT E FIB GERARCHICHE
Un aspetto molto importante per la convergenza, ma invisibile dall'esterno, è come è organizzata la FIB (Forwarding Information Base), ossia la tabella (tipicamente hardware) che il router utilizza per la commutazione dei pacchetti. La costruzione della FIB a partire dalle informazioni contenute nella RIB (Routing Information Base, meglio nota come Tabella di Routing) utilizza algoritmi vendor-dependent (CEF Cisco, PFE Juniper, ecc.) (NOTA: sentito mai parlare di Openflow ? E' un nuovo protocollo che nella mente dei suoi ideatori dovrebbe rendere standard il protocollo di comunicazione RIB-FIB, ossia di rendere standard il colloquio "piano di controllo - piano dati").
La FIB può avere una architettura flat oppure gerarchica. Nell'architettura flat, ogni prefisso presente nella FIB (sia esso appreso via BGP o IGP) ha associate le informazioni per il forwarding (interfaccia di uscita, MAC rewrite, etichette MPLS, ed eventualmente altro, se necessario, vedi figura seguente). Le informazioni per il forwarding vengono spesso anche dette Direct Next-Hop.
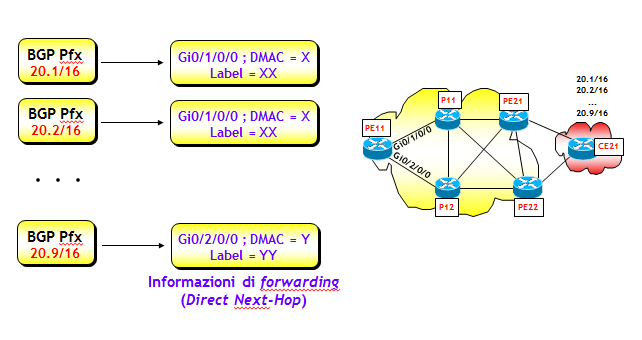
Una architettura flat non è però molto efficiente, poiché un qualsiasi cambio che riguarda il Direct Next-Hop, richiede l'aggiornamento di tutti i prefissi associati a quel Direct Next-Hop. Ovviamente, con questo tipo di architettura, il tempo di aggiornamento della FIB dipende dal numero di prefissi presenti nella stessa, e può diventare molto elevato. Se la FIB ha solo un centinaio di prefissi, anche una architettura flat va bene, ma se il numero di prefissi fosse dell'ordine delle centinaia di migliaia, l'aggiornamento potrebbe richiedere anche più di un minuto ! Le FIB con architettura flat potevano andar bene 20 anni fa, quando la Full Internet Routing Table aveva meno di 10k prefissi. Nelle reti IP del 21-esimo secolo, dove la Full Internet Routing Table supera le 500k righe, è necessario adottare un approccio diverso. L'architettura della FIB è stata così riprogettata per rendere il suo aggiornamento più veloce. L'idea è organizzarla su tre livelli gerarchici:
Prefisso --> Puntatore --> Informazioni di forwarding
dove il puntatore, spesso anche detto Indirect Next-Hop, altro non è nel nostro caso che un BGP Next-Hop, come mostrato anche nella figura seguente (in realtà alcuni costruttori utilizzano come Indirect Next-Hop un numero scelto internamente dal router, ma per capire meglio i concetti che stò esponendo, è più semplice considerarlo come fosse un BGP Next-Hop). Uno (o più, nel caso di BGP multipath) di questi puntatori (puntatore attivo) è quello effettivamente utilizzato per determinare le informzioni di forwarding. L'associazione "Puntatore --> Informazioni di forwarding" viene determinata (tipicamente) da un protocollo IGP.
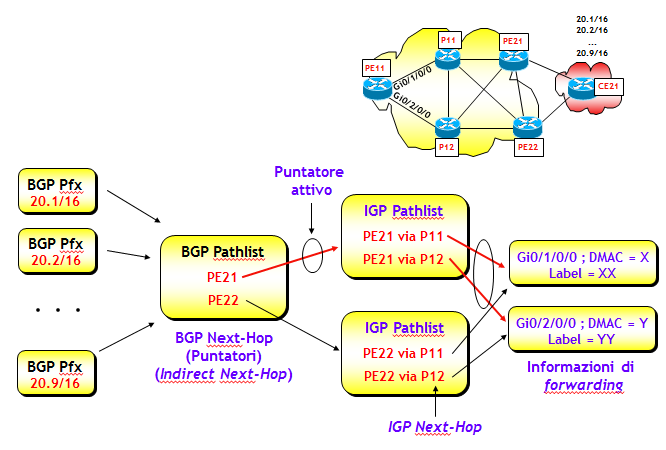
Per capire perché questa semplice idea migliori di molto le proprietà di convergenza della FIB, mostrerò cosa accade nel caso dei tre scenari descritti nella sezione precedente. Per tutti gli scenari ipotizzerò che CE21 annunci i prefissi 20.X/16, X=1, ..., 9, e senza perdita di generalità supporrò che tutti i prefissi 20.X/16 siano raggiungibili da PE11, attraverso lo stesso BGP Next-Hop PE21 (che è quindi il puntatore inizialmente attivo).
Consideriamo il primo scenario, ipotizzando come prima, il fuori servizio del router P11.
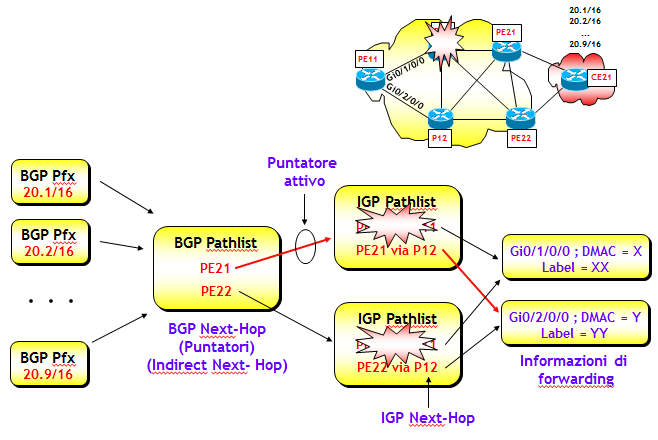
Sul router di edge in ingresso PE11, il protocollo IGP determina velocemente i nuovi percorsi ottimi verso i router PE21 e PE22, e quindi la FIB aggiorna l'IGP Pathlist. I puntatori (BGP Next-Hop) non cambiano, l'unica cosa che potrebbe cambiare a livello di puntatori è il loro utilizzo, che dipende dai nuovi costi IGP verso i BGP Next-Hop. Ma l'eventuale cambio del puntatore può avvenire solo a valle di un nuovo processo di selezione BGP, che è compito del piano di controllo BGP.
Se prima del fuori servizio del router P11 veniva utilizzato come puntatore attivo PE21, dopo la convergenza del piano di controllo BGP la FIB potrebbe utilizzare come puntatore attivo PE22, se il nuovo costo IGP verso PE22 risultasse inferiore rispetto a quello verso PE21. Ma durante la convergenza del piano di controllo BGP, la FIB continua a utilizzare lo stesso puntatore precedente (ossia PE21).
La convergenza è immediata e, si badi bene, non dipende in alcun modo dal piano di controllo BGP, né quindi dal numero di prefissi BGP, ma solo dalla velocità di convergenza del protocollo IGP, ma su questo aspetto tornerò ampiamente nella prossima sezione. Faccio notare inoltre che in questo scenario, la presenza di un puntatore alternativo non è in realtà necessaria. Infatti, qualora non vi sia, il traffico continuerebbe a fluire sempre verso l'unico BGP Next-Hop, solo che utilizzerebbe un percorso interno diverso.
Consideriamo ora il secondo scenario, ipotizzando il fuori servizio del router di edge PE21.
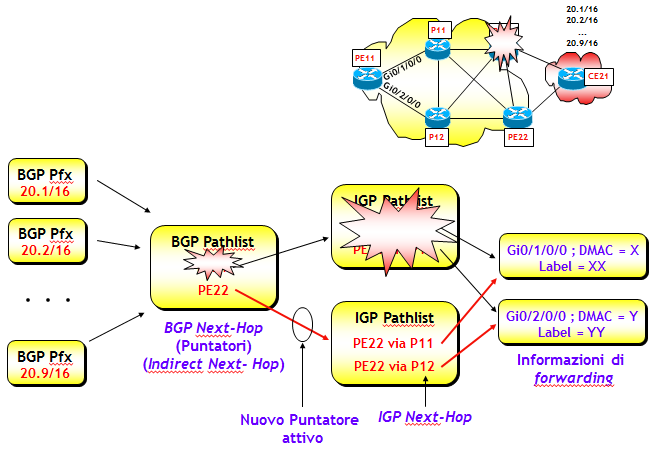
Anche qui, il protocollo IGP, secondo i suoi tempi di convergenza, informa velocemente i router di edge PE11 e PE22 che PE21 non è più raggiungibile. A fronte di questa nuova situazione, la FIB elimina il puntatore verso PE21 e redirige il traffico immediatamente, utilizzando il secondo puntatore disponibile, che diventa così attivo. In questo caso, a differenza del precedente, entra in funzione anche il BGP NHT, che attiva la convergenza sul piano di controllo BGP. Ma se anche questa fosse lunga, il traffico comunque continuerebbe nel frattempo a fluire regolarmente grazie alla disponibilità del secondo puntatore, che come detto sopra, entra in funzione immediatamente. In questo scenario, la convergenza al nuovo puntatore attivo è immediata e avviene direttamente sul piano dati, senza l'intervento del piano di controllo BGP. Inoltre, i tempi di convergenza non dipenderebbero dal numero di prefissi, ma solo dalla velocità di convergenza del protocollo IGP.
Infine, consideriamo il terzo scenario, ipotizzando il fuori servizio del collegamento PE21-CE21. In questo scenario ipotizzerò che i due router di edge PE21 e PE22 utilizzino il comando "neighbor <PE11> next-hop-self" e che l'indirizzo utilizzato per le sessioni iBGP sia un proprio indirizzo dell'interfaccia Loopback 0. Come già visto sopra, questo è un caso diverso dai due precedenti poiché il fuori servizio del collegamento PE21-CE21 non ha alcun impatto sui puntatori né sulle IGP Pathlist. Però il router di edge PE21 può sfruttare la sua FIB gerarchica e cambiare immediatamente il suo puntatore da CE21 a PE22. Il traffico da PE11 verso i prefissi annunciati da CE21 seguirà quindi il percorso PE11-->PE21-->PE22-->CE21, come mostrato nella figura seguente.
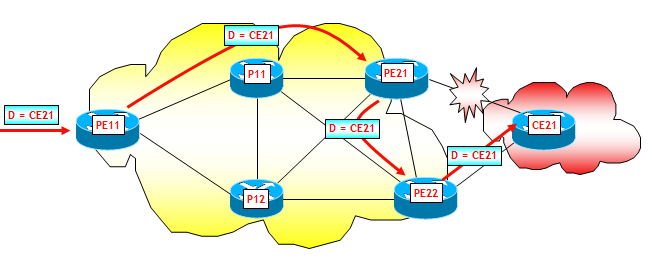
Attenzione che questo passaggio potrebbe però generare dei forwarding loop, seppur temporanei (anche detti micro-loop, vedi sezione "ALCUNI ASPETTI PROGETTUALI") ! Anche qui, su PE21 però e non su PE11, entra in funzione il BGP NHT, che attiva il piano di controllo BGP e la riconvergenza di PE11 sul secondo BGP Next-Hop disponibile. Anche qui, se pure questa convergenza fosse lunga, il traffico comunque continuerebbe nel frattempo a fluire regolarmente grazie alla disponibilità del secondo puntatore sul router PE21, che come appena detto entra in funzione immediatamente. Terminata la convergenza del piano di controllo BGP, il traffico continuerà a fluire, ma seguendo il percorso più "naturale" PE11-->PE22-->CE21.
In tutti i tre scenari, l'utilizzo di una FIB gerarchica consente di ridurre a livelli dell'ordine delle poche decine di msec il tempo di convergenza, o meglio, il tempo di perdità della connettività (LoC, Loss of Connettivity).
Nelle moderne piattaforme di routing, l'utilizzo delle FIB con architetture gerarchiche è pervasivo e spesso non richiede speciali comandi di configurazione. Per questo ho scritto sopra, che questo è un aspetto molto spesso invisibile dall'esterno.
Ora però viene il bello, perché il lettore attento avrà notato che la storia non finisce qui, infatti manca un tassello fondamentale. A meno di non abilitare il BGP multipath (se possibile !) nel secondo e terzo scenario, come fa l'algoritmo di gestione della FIB a conoscere il BGP Next-Hop alternativo ? E poi, ma questo BGP Next-hop alternativo siamo sicuri che sia sempre disponibile ? Senza la presenza di un BGP Next-Hop alternativo, la FIB deve necessariamente ricorrere al piano di controllo BGP per averne un altro. E questo allungherebbe di molto la convergenza, rendendo l'utilizzo delle FIB gerarchiche praticamente inutile.
BGP PREFIX INDEPENDENT CONVERGENCE (BGP PIC)
Supponiamo per il momento di trascurare il problema, e di partire dall'ipotesi che il BGP Next-Hop alternativo sia disponibile. Su questo problema però dovrò necessariamente ritornare, perché l'ipotesi che sto facendo in molti casi non corrisponde al vero (il lettore può intanto pensare in quali casi), per cui è necessario inventarsi qualcosa di nuovo (o qualche diabolico trucco sfruttando funzionalità "classiche") affinché ciò avvenga, e questo sarà l'oggetto principale di vari Post successivi, perché i metodi proposti sono molteplici.
Già sappiamo che il BGP NHT è in grado di rilevare velocemente la perdita di un BGP Next-Hop, e che questa informazione attiva un switchover locale al nuovo BGP Next-Hop. Questo switchover, qualora si utilizzi una architettura gerarchica della FIB, non richiede alcuno scanning della Tabella BGP e nessuna rielezione del best-path, ma semplicemente un cambio di puntatore.
Il processo di switchover non dipende quindi dal numero di prefissi presenti nella FIB, ma è piuttosto una semplice operazione che avviene a livello di FIB, ossia di piano dati. Per questa ragione, questa funzionalità viene indicata come Prefix Independent Convergence (PIC).
Nel primo scenario descritto nella sezione precedente si parla di funzionalità BGP PIC Core, e in questo scenario avere un BGP Next-Hop alternativo non è strettamente necessario (anche se spesso si ha comunque per motivi di fault-tolerance). Questo perché, in ogni caso, il BGP Next-Hop attualmente in uso è sempre disponibile, non avendo il fuori servizio di un elemento interno alla rete alcun impatto sulla sua raggiungibilità, ma ha impatto solo sul percorso interno per raggiungerlo (ovviamente, sempre che il backbone sia stato progettato correttamente, con magliatura sufficiente a garantire una buona disponibilità di cammini interni multipli che evitino partizioni del backbone stesso). Successivamente, il piano di controllo BGP potrebbe anche scegliere un nuovo BGP Next-Hop, se ritenuto più conveniente, ma questo è un problema del piano di controllo BGP, senza alcun impatto sulla convergenza sul piano dati.
Negli altri due scenari, la disponibilità di un BGP Next-Hop alternativo è vitale, perché se il BGP Next-Hop attivo diviene irraggiungibile, è necessario averne uno di riserva "pronto all'uso", altrimenti bisogna ricorrere al piano di controllo BGP per trovarne uno alternativo, allungando i tempi di convergenza. In questi due scenari si parla di funzionalità BGP PIC Edge.
Questa idea del BGP PIC non è nuova ed è già stata applicata in passato per la prima volta nel noto protocollo di routing proprietario Cisco EIGRP, dove insieme al Next-Hop primario (Successor) nella FIB viene inserito anche un Next-Hop alternativo loop-free (Feasible Successor). Per i più aggiornati, questa funzionalità è oggi presente anche nei protocolli di routing di tipo Link-State (OSPF e IS-IS), con il nome di LFA (Loop Free Alternate).
Si noti comunque che questo non significa che la normale convergenza sul piano di controllo BGP non avvenga, ma solo che è possibile utilizzare immediatamente un Next-Hop alternativo, già preinstallato nella FIB, riducendo così drasticamente la perdita di traffico durante la convergenza del piano di controllo.
Per chi fosse a conoscenza del funzionamento del servizio MPLS-TE Fast-ReRoute, questo è analogo a quanto avviene durante il fuori servizio di un nodo o collegamento parte di un tunnel MPLS-TE principale: il traffico ritenuto importante, ossia quello da proteggere, scorre momentaneamente su un tunnel MPLS-TE di backup preinstallato, che evita il nodo o collegamento fuori servizio. Il tunnel di backup viene però utilizzato fino a quando l'Edge-LSR che origina il tunnel principale non determina un percorso alternativo, lo segnala (via RSVP-TE) e quindi ci inoltra il traffico.
In una vecchia presentazione di Clarence Filsfils di Cisco, potete trovare una prova interessante che mostra come in uno scenario in cui un AS che ha due sessioni BGP con un altro AS, e riceve da questo la Full Internet Routing Table (a quel tempo di circa 350k prefissi, oggi di più di 530k prefissi), grazie alla funzionalità PIC, un router (Cisco 12k) connesso con due sessioni iBGP ai due router di edge con l'altro AS, impiegava solo 180 msec a convergere sul Next-Hop alternativo,mentre senza la funzionalità PIC, il tempo di convergenza diventava dell'ordine delle decine di secondi.
ALCUNI ASPETTI PROGETTUALI
Quando si parla di BGP PIC, sostanzialmente si parla di convergenza sul piano dati, invece che sul piano di controllo. Quindi uno potrebbe pensare che non vi sia da prendere alcun accorgimento progettuale. Non è proprio così, perché per raggiungere tempi convergenza dell'ordine delle decine di msec, qualcosa da fare c'è:
- Poiché nei vari scenari descritti sopra, in particolare nei primi due, il tempo di convergenza del BGP è strettamente legato al tempo di convergenza del protocollo IGP, è necessario eseguire un opportuno tuning del protocollo IGP, mettendo in campo tutte le funzionalità disponibili che consentono di ottenere una convergenza veloce.
- E' necessario fare attenzione a possibili forwarding (micro-)loop, che possono verificarsi in scenari non BGP core-free.
- Nello scenario BGP PIC Edge, è necessario assicurarsi la presenza di un BGP Next-Hop di backup (alternativo).
Quest'ultimo aspetto l'ho citato sopra e sarà l'oggetto di Post futuri. Per quanto riguarda il primo, in realtà per questo Post è fuori tema. Per completezza voglio solo dare qualche suggerimento, ma tenete conto che in seguito tratterò diffusamente su questo blog gli aspetti di convergenza di OSPF e IS-IS:
- Utilizzate sempre meccanismi che consentano di rilevare il più velocemente possibile la perdita di una adiacenza (BFD, Carrier-delay). Evitate di fare affidamento su meccanismi tipo fast-hello, che potrebbero sovraccaricare troppo la CPU dei router.
- Eseguite un tuning efficiente dei timer di generazione dei LSA/LSP e di ricalcolo via SPF dei percorsi ottimi. Già da solo questo accorgimento, insieme a quello del punto precedente, consente di portare il tempo di convergenza al di sotto del secondo.
- Partendo dalla considerazione che non tutti i prefissi hanno la stessa importanza (es. un prefisso /32 di un router PE utilizzato per stabilire sessioni iBGP, è più importante di una subnet con cui si numera un collegamento punto-punto), configurate meccanismi tipo "spf per-prefix prioritization", in modo tale che i prefissi più importanti vengano trattati con precedenza rispetto a quelli meno importanti (e quindi finiscono per primi nelle RIB e FIB !).
- Mantenete il vostro protocollo snello e pulito, evitando di redistribuire all'interno subnet IP non necessarie ed evitando funzionalità che non danno alcun valore aggiunto.
- Valutate, se la topologia della rete lo consente, l'introduzione in rete di funzionalità tipo LFA (Loop Free Alternate).
Per quanto riguarda il secondo aspetto, voglio solo farvi vedere come potrebbero formarsi dei forwarding micro-loop e quali sono le contromisure da adottare. Considerate la rete che ho utilizzato sopra per le prove di laboratorio, ma a differenza di quanto visto finora, supponiamo di attivare anche sessioni iBGP (con "next-hop-self" attivo) tra ogni router PE e i router interni di transito P, ad esempio, tra PE21 e i due router P11 e P12 (vedi figura seguente, dove per evitare di pasticciarla ho solo disegnato le sessioni iBGP che hanno come estremo comune PE21). Ora, con questo progetto di rete, anche il router P12 riceverà gli annunci iBGP da PE21 e PE22 per i prefissi originati da CE21. Supponiamo che P12 scelga come best-path PE21 e che il collegamento PE21-CE21 vada fuori servizio. Come già visto sopra, il router PE21 redirige il traffico diretto a CE21 utilizzando come Next-Hop (remoto) il router PE22, supponiamo passando per P12 (possibile, a causa delle metriche IGP). Se P12 non avesse ancora ricevuto dal piano di controllo BGP il ritiro del prefisso originato da CE21, e quindi non avesse ancora determinato il nuovo best-path, cosa tra l'altro molto probabile poiché PE21 può sfruttare la funzionalità PIC ma P12 no, e tra l'altro P12 non può nemmeno sfruttare la funzionalità BGP NHT (perché ?), P12 rimanderebbe il traffico indietro a PE21, generando così un micro-loop.
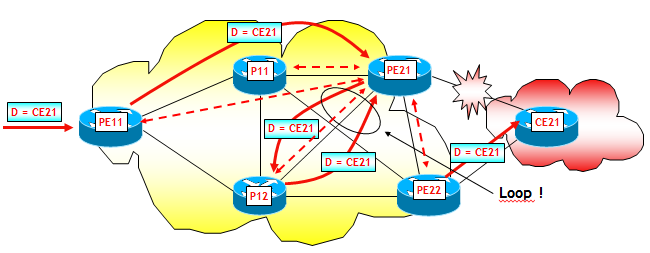
Il micro-loop cessa non appena anche P12 riceve dal piano di controllo BGP il ritiro del prefisso originato da CE21.
Come è possibile evitare questi micro-loop ? Io consiglio sempre di progettare un backbone BGP core-free, utilizzando MPLS all'interno (ricordo che BGP core-free significa che i router interni non hanno bisogno del BGP !). Così facendo, i router P agiscono solo come strumenti di collegamento tra i router PE e non hanno accesso al contenuto del payload MPLS, e quindi non possono rimandare i pacchetti indietro. Altri artifici come i tunnel GRE li sconsiglio, anche se possono, teoricamente, essere utilizzati.
CONFIGURAZIONE DELLA FUNZIONALITA' PIC NELLE PIATTAFORME CISCO
Per abilitare l'installazione nella FIB di un Next-Hop di backup, sempre che questo sia disponibile (ma io sto ipotizzando che sia disponibile !), è necessaria una opportuna configurazione.
Vediamo dapprima l'ambiente Cisco. Innanzitutto è necessario accertarsi che la piattaforma che si sta configurando abbia o no abilitata una FIB gerarchica (la funzionalità PIC senza una FIB gerarchica non ha molto senso !).
Come spesso accade nell'ambiente Cisco, è necessario fare attenzione al tipo di piattaforma. La FIB gerarchica in alcune piattaforme è abilitata di default (es. CRS, XR12k ASR9k, NX-OS), e quindi per queste non vi è bisogno di alcun comando particolare di configurazione, mentre in piattaforme tipo serie 7600, ASR1k, la FIB gerarchica va abilitata con il (terribile) comando globale "cef table output-chain build favor convergence-speed".
Per la funzionalità BGP PIC core non vi è bisogno d'altro, mentre per la funzionalità BGP PIC Edge è necessario abilitare l'installazione nella FIB di un Next-Hop di backup. Nell'IOS vi sono due modalità di BGP PIC Edge, multipath e unipath. La modalità multipath, che si ha in uno scenario active/active (ossia, quando entrambi i BGP Next-Hop disponibili sono utilizzati per inoltrare il traffico) non richiede alcuna configurazione particolare, se non la classica abilitazione del BGP multipath attraverso il comando "maximum-paths ..." a livello di processo BGP. La modalità unipath, tipica di uno scenario active/standby, richiede invece il comando (NOTA: in qualche caso la modalità unipath viene abilitata automaticamente previa abilitazione di un'altra funzionalità, come ad esempio nel caso della funzionalità BGP best-external, che sarà trattata in uno dei prossimi Post):
router bgp AS
address-family {ipv4 [vrf ...] | vpnv4 | ipv6}
bgp additional-paths install
Nell'IOS-XR la configurazione è un po' più articolata e richiede una routing policy (forse aperta a futuri sviluppi):
route-policy NOME-RP
set path-selection backup 1 install [... opzioni omesse...]
end-policy
!
router bgp AS
address-family {ipv4 [vrf ...] | vpnv4 | ipv6 [vrf ...] | vpnv6} unicast
additional-paths selection route-policy NOME-RP
Utilizzando il solito nostro glorioso GSR 12416 con IOS-XR 4.2.4, l'unica piattaforma del nostro Lab in grado di supportare la funzionalità PIC, ho eseguito un piccolo test. Ho fatto in modo che questo router, che ho chiamato PE2-3,ricevesse due annunci di due diversi percorsi verso il prefisso 10.1.99.12/32, il primo con BGP Next-Hop (remoto) 192.168.0.11 (risultato best-path) il secondo con BGP Next-Hop (sempre remoto) 192.168.0.12. Ho quindi abilitato la funzionalità PIC con i seguenti comandi:
route-policy REISS-BACKUP
set path-selection backup 1 install
end-policy
!
router bgp 3269
address-family ipv4 unicast
additional-paths selection route-policy REISS-BACKUP
!
neighbor 192.168.0.1
remote-as 3269
update-source Loopback0
address-family ipv4 unicast
!
!
neighbor 192.168.0.2
remote-as 3269
update-source Loopback0
address-family ipv4 unicast
!
!
!
Faccio notare che gli indirizzi 192.168.0.1 e 192.168.0.2 sono quelli di due Route Reflector, ma ho "magheggiato" con operazioni elementari in modo che PE2-3 ricevesse due annunci distinti del prefisso 10.1.99.12/32.
Riporto di seguito delle visualizzazioni ottenute con comandi classici, che consentono di verificare l'abilitazione della funzionalità BGP PIC Edge.
La prima visualizzazione riguarda il dettaglio degli annunci BGP del prefisso 10.1.99.12/32, presenti nella Tabella BGP di PE3-2:
RP/0/1/CPU0:PE2-3# show bgp 10.1.99.12/32
Thu Nov 20 18:01:19.445 UTC
BGP routing table entry for 10.1.99.12/32
Versions:
Process bRIB/RIB SendTblVer
Speaker 8 8
Last Modified: Nov 20 18:00:26.003 for 00:00:53
Paths: (2 available, best #1)
Not advertised to any peer
Path #1: Received by speaker 0
Not advertised to any peer
65012
192.168.0.11 (metric 32) from 192.168.0.1 (192.168.0.11)
Origin IGP, metric 0, localpref 100, valid, internal, best, group-best
Received Path ID 0, Local Path ID 1, version 7
Originator: 192.168.0.11, Cluster list: 192.168.0.1
Path #2: Received by speaker 0
Not advertised to any peer
65012
192.168.0.12 (metric 32) from 192.168.0.2 (192.168.0.12)
Origin IGP, metric 0, localpref 100, valid, internal, backup, add-path
Received Path ID 0, Local Path ID 2, version 8
Originator: 192.168.0.12, Cluster list: 192.168.0.2
Il percorso di backup è (ovviamente) quello "non best". La presenza della parola "backup" nella terzultima riga della visualizzazione mostra che l'abilitazione della funzionalità BGP PIC Edge è andata a buon fine.
La seconda visualizzazione riguarda il dettaglio delle informazioni nella RIB (Tabella di Routing), relative al prefisso 10.1.99.12/32:
RP/0/1/CPU0:PE2-3# show route 10.1.99.12/32
Thu Nov 20 18:03:13.641 UTC
Routing entry for 10.1.99.12/32
Known via "bgp 3269", distance 200, metric 0
Tag 65012
Number of pic paths 1 , type internal
Installed Nov 20 18:00:26.433 for 00:02:47
Routing Descriptor Blocks
192.168.0.11, from 192.168.0.1
Route metric is 0
192.168.0.12, from 192.168.0.2, BGP backup path
Route metric is 0
No advertising protos.
Dalla visualizzazione si deduce che esistono due percorsi verso il prefisso 10.1.99.12/32, di cui quello di backup (evidenziato con "BGP backup path") è quello che ha BGP Next-Hop 192.168.0.12.
Infine, la terza visualizzazione (la più importante) riguarda la Tabella CEF:
RP/0/1/CPU0:PE2-3# show cef 10.1.99.12/32
Thu Nov 20 18:11:17.971 UTC
10.1.99.12/32, version 43, internal 0x14000001 (ptr 0xae3523d0) [1], 0x0 (0x0), 0x0 (0x0)
Updated Nov 20 18:00:26.436
local adjacency 172.16.2.21
Prefix Len 32, traffic index 0, precedence routine (0), priority 4
via 192.168.0.11, 2 dependencies, recursive [flags 0x6000]
path-idx 0 [0xae352010 0x0]
next hop 192.168.0.11 via 192.168.0.11/32
via 192.168.0.12, 2 dependencies, recursive, backup [flags 0x6100]
path-idx 1 [0xae352088 0x0]
next hop 192.168.0.12 via 192.168.0.12/32
Dalla visualizzazione si deduce che nella FIB esistono due percorsi verso il prefisso 10.1.99.12/32, di cui quello di backup (evidenziato con "backup") è quello che ha BGP Next-Hop 192.168.0.12.
CONFIGURAZIONE DELLA FUNZIONALITA' PIC NELLE PIATTAFORME JUNIPER
Per quanto riguarda il JUNOS, l'architettura gerarchica della FIB va abilitata con il comando seguente:
tt@router# show routing-options
forwarding-table {
indirect-next-hop;
}
Per verificare se il comando ha avuto effetto, l'unico modo è utilizzare il comando (nascosto) "show krt indirect-next-hop". Con una piccola prova che ho effettuato, questo è il risultato che ho ottenuto:
tt@PE2-2> show krt indirect-next-hop
Indirect Nexthop:
Index: 262142 Protocol next-hop address: 192.168.1.12
RIB Table: inet.0
Policy Version: 0 References: 1
Locks: 2 0x165c0e8
Flags: 0x1
Ref RIB Table: unknown
Next hop: 172.30.2.1 via ge-0/0/0.0
L'abilitazione dell'architettura gerarchica della FIB è segnalata dalla flag 0x1 (Flags: 0x1). Quando il comando "indirect-next-hop" viene eliminato, o disattivato tramite il comando seguente (ma non si capisce perché uno dovrebbe farlo):
tt@router# show routing-options
forwarding-table {
no-indirect-next-hop;
}
il valore della flag cambia da 0x1 a 0x0.
Faccio notare che il comando "show krt indirect-next-hop" non è documentato, ma è l'unico (almeno secondo alcuni documenti JUNOS) che consente di verificare se il comando "indirect-next-hop" è stato eseguito. Un'altra prova (anche migliore) ovviamente è il monitoraggio delle prestazioni di convergenza a seguito del fuori servizio di un elemento di rete, prima e dopo l'esecuzione del comando "indirect-next-hop".
Per la funzionalità BGP PIC Core non vi è bisogno d'altro, mentre per la funzionalità BGP PIC Edge è necessaria una opportuna configurazione. Il JUNOS supporta il BGP PIC Edge solo con per il servizio L3VPN. Vi sono due comandi diversi in funzione del tipo di protezione. Il primo tipo riguarda la protezione da fuori servizio di un altro router PE. L'abilitazione della funzionalità BGP PIC Edge avviene in questo caso attraverso il semplice comando:
[edit routing-instances NOME-RI]
tt@router# show
routing-options {
protect core;
}
Non avendo a disposizione piattaforme Juniper in grado di supportare questo comando, vi rimando a questo esempio, disponibile nella documentazione Juniper. Vi avverto però che per poter capire bene l'esempio, è necessaria una buona conoscenza dell'implementazione dei servizi L3VPN nel JUNOS.
Il secondo tipo di protezione riguarda il fuori servizio di un collegamento PE-CE. L'abilitazione della funzionalità BGP PIC Edge avviene in questo caso attraverso il semplice comando:
[edit routing-instances NOME-RI protocols bgp group NOME-GRUPPO]
tt@router# show
family ( inet | inet6 ) {
unicast {
protection;
}
}
Anche qui, non avendo a disposizione piattaforme Juniper in grado di supportare questo comando, vi rimando a questo esempio, disponibile nella documentazione Juniper.
CONCLUSIONI
Con questo Post, spero di aver dato il colpo finale alla "credenza popolare" che il BGP sia lento a convergere. La realtà, come risulta dalla lettura, è ben diversa e oggi si può tranquillamente dire che il BGP converge con tempi dell'ordine delle decine di msec. Naturalmente questo comporta un tuning accurato del protocollo IGP, l'applicazione del BGP PIC Core/Edge e l'implementazione di FIB con struttura gerarchica. I principali costruttori di apparati come Cisco e Juniper mettono a disposizione tutti gli strumenti per fare questo, basta applicarli !
La storia comunque non finisce qui, ho detto più volte che manca un tassello fondamentale, ossia fare in modo che un router abbia a disposizione un secondo annuncio, oltre al best-path, da utilizzare come backup. A volte questo secondo annuncio si ha senza fare alcunché, ma in alcune situazioni importanti da un punto di vista pratico, questo non avviene. Ed è di questo che mi occuperò in futuro.
Siete nuovi al BGP, oppure avete bisogno di ulteriori approfondimenti ? Acquistate il mio libro "BGP: dalla teoria alla pratica" (al prezzo speciale di 30 Euro per gli utenti registrati al sito, spese di spedizione gratuite). Oppure seguite i nostro corsi IPN246 e IPN247.
