


Tiziano
Martedì, 16 Febbraio 2016 06:33
Blog : è tempo di migrare ...
Carissimi Amici,
il blog è migrato in una piattaforma diversa. Per raggiungerlo, utilizzate questa URL.
Ho portato tutti i post precedenti nella nuova piattaforma, ad esclusione di quelli che alla fine avevano un documento riassuntivo (BFD e Convergenza BGP). Per questi due argomenti troverete il solo documento riassuntivo.
Mi raccomando, leggete prima il post di servizio.
Spero continuerete a seguirmi con la stessa intensità. Tra l'altro avremo la possibilità di essere più interattivi, grazie alla possibilità di inserire i commenti, e di varie modalità di contatto.
Ciao a tutti.
Tiziano Tofoni (alias, Ammiraglio Tofonoto)
Venerdì, 05 Febbraio 2016 06:17
DALLE RETI DI CLOS ... ALLE RETI DI CLOS
A grandi linee, un Data Center è costituito da un insieme di server, interconnessi tra loro da una rete. I server possono essere stand-alone (bare-metal server), ossia macchine fisiche dove risiedono più applicazioni, senza però alcun tipo di virtualizzazione, o server dove è possibile creare macchine virtuali tramite un Hypervisor, che può essere di nuova o vecchia generazione.
La differenza tra un Hypervisor di nuova generazione e uno di vecchia, è che i primi sono in grado di svolgere la funzione NVE (Network Virtualization Endpoint, che nel caso di incapsulamento VXLAN coincide con la funzione VTEP), mentre i secondi no. Ricordo le che la funzione NVE è quella che consente di incapsulare in ingresso e decapsulare in uscita, pacchetti/trame provenienti e destinati alle macchine virtuali definite sui server; un esempio è la funzione VTEP ampiamente illustrata in questo post. Ogni Data Center ha poi almeno un router gateway che consente l’interconnessione con altri Data Center, con l’Internet, con la rete di un ISP, ecc. . Lo schema generale è riassunto nella figura seguente.
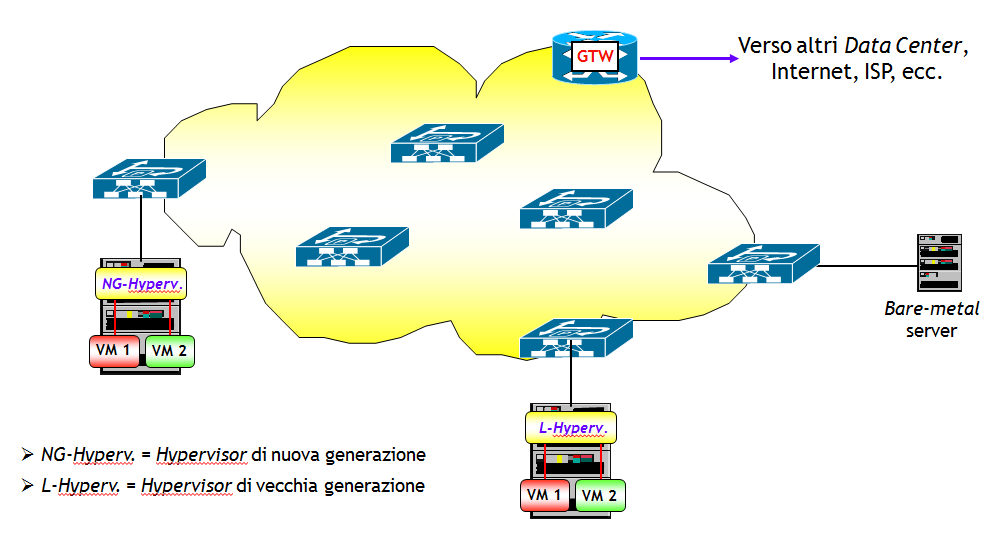
Questo post focalizza l’attenzione sulla rete di interconnessione tra i vari server e router gateway, che per analogia con le vecchie centrali di commutazione, viene chiamata Fabric (vedi sezione successiva). Niente di cui aver timore, la Fabric è una banale rete di cui ogni networker che si rispetti conosce vita morte e miracoli. Perché scriverci un post allora ? La ragione è semplice, nei Data Center di ultima generazione è importante che la Fabric abbia una topologia che sia scalabile, che abbia la possibilità di distribuire in modo efficiente il traffico, semplice da gestire, stabile e con tempi di convergenza possibilmente bassi.
Sembrerebbe un libro dei sogni, ma se ci riflettete bene, le moderne reti degli ISP (almeno di un certo tipo e con determinate topologie) soddisfano già questi requisiti. Per cui, bisogna solo adattare queste reti alla realtà dei Data Center.
Il primo quesito che ci si deve porre circa la Fabric è questo: realizzare una Fabric L2 (= switched Ethernet) o L3 (= IP o IP+MPLS) ? E qui la mia risposta la conoscete già, il routing di Livello 3 è un must, scordatevi di realizzare reti puramente L2, a meno non siate così masochisti da voler dimezzare la banda disponibile a causa dello Spanning Tree , da incorrere in broadcast storm, ecc. ecc. (d’altra parte, avete mai visto un ISP che utilizza una rete L2 a livello geografico ?) . E poi, lasciate perdere soluzioni ibride come l’utilizzo di TRILL o SPB, non sono sufficientemente testate sul campo, non sono utilizzate da tutti i costruttori e poi sono implementate in modo personalizzato (vedi CiscoFabricPath) impedendo l’interlavoro tra macchine di costruttori diversi (magari è proprio quello che i costruttori desiderano ...).
Semmai l’unico dubbio che rimane è se costruire Fabric di tipo solo IP o IP+MPLS. La tendenza è realizzare Fabric solo IP, anche se qualche costruttore (es. Juniper all’interno della sua QFabric) utilizza MPLS, ma in modo, per così dire, “nascosto”. Per questo da qui in poi farò riferimento alla Fabric chiamandola IP Fabric, per mettere in evidenza che tratterò Fabric solo IP.
Semmai l’unico dubbio che rimane è se costruire Fabric di tipo solo IP o IP+MPLS. La tendenza è realizzare Fabric solo IP, anche se qualche costruttore (es. Juniper all’interno della sua QFabric) utilizza MPLS, ma in modo, per così dire, “nascosto”. Per questo da qui in poi farò riferimento alla Fabric chiamandola IP Fabric, per mettere in evidenza che tratterò Fabric solo IP.
L’argomento di questo post riguarda la topologia della IP Fabric. E qui entra in gioco Charles Clos. Parafrasando una nota frase di Manzoniana memoria, qualcuno potrebbe chiedersi “Clos, chi era costui ?”. Nessun problema, i più anziani, o meglio quelli che lavorano in questo settore da molti, molti anni, almeno quelli sufficienti a ricordare le vecchie centrali (telefoniche) di commutazione elettromeccaniche, sanno bene chi era Charles Clos. Divenne famoso, nel settore, perché fu il primo a proporre le reti di commutazione multistadio. Sotto farò qualche richiamo storico, che potete saltare, ma ricordate sempre che “la storia è maestra di vita”.
Il concetto di reti multistadio è stato ripreso, solo a livello topologico, nelle moderne architetture delle IP Fabric, che in onore di Charles Clos, sono chiamate Reti di Clos. E questo spiega il titolo di questo post: dalle Reti di Clos (multistadio nella commutazione telefonica elettromeccanica) si è passati (nuovamente) alle Reti di Clos (sempre multistadio nelle moderne topologie delle IP Fabric). Della serie "Nulla si crea, nulla si distrugge, tutto si trasforma" (Legge di conservazione della massa, Antoine-Laurent de Lavoisier, 1787).
UN PO’ DI STORIA
Ai tempi della commutazione telefonica basata sulle centrali elettromeccaniche e sulla commutazione di circuito, uno dei problemi principali per una centrale telefonica era quello di creare un collegamento fisico tra un “filo” di ingresso e uno di uscita della centrale. Il problema veniva risolto attraverso una “matrice di commutazione”, ossia un accrocco presente all’interno della centrale, composto da un certo numero di relè elettromeccanici, che aveva il compito di creare il percorso fisico tra il filo di ingresso e il filo di uscita.
Per aumentare la scalabilità, Charles Clos propose in un celebre articolo, pubblicato sull’altrettanto celebre Bell System Technical Journal, di utilizzare invece che una singola grande matrice di commutazione, più matrici di commutazione di dimensione più piccola, interconnesse tra loro (vedi figura seguente, tratta da Wikipedia).
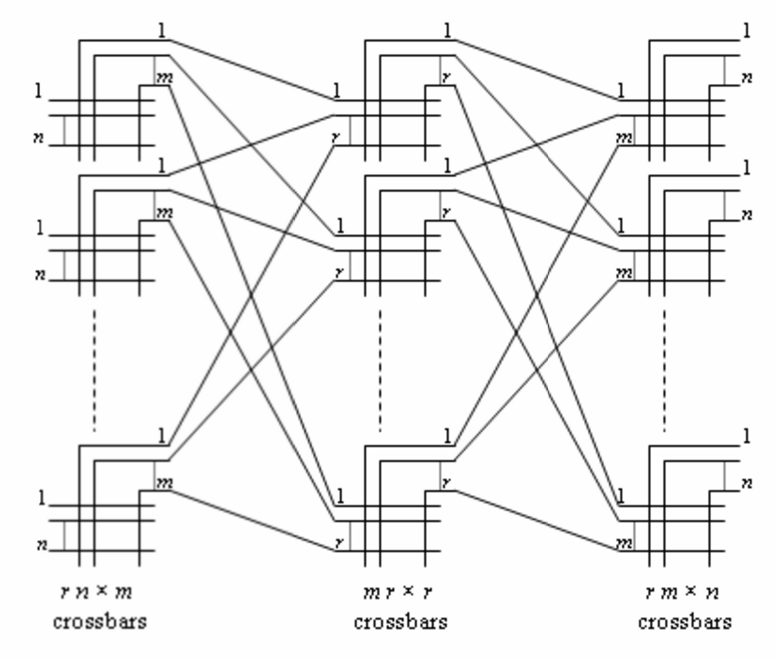
Il lavoro originale di Clos (per i più curiosi, lo trovate a questo link, ma vi avverto, non è di semplice lettura) non si limitava comunque a proporre una topologia multistadio, ma conteneva uno studio dettagliato sulle proprietà di blocco delle matrici stesse, ossia sulla probabilità che non fosse possibile trovare un percorso interno alla matrice, per collegare i fili di ingresso e uscita. Clos trovò anche una condizione che la topologia della matrice (rete) multistadio doveva soddisfare per divenire non bloccante, ossia la condizione affinché la probabilità di blocco interno della rete multistadio fosse nulla.
E qui mi fermo con la storia. Però vorrei farvi notare un’analogia. Prendete un router modulare con una scheda processore e tante linecard. Come avviene il collegamento tra un interfaccia (filo) di ingresso e una di uscita appartenenti a due diverse linecard ? Bene, il collegamento tra linecard viene realizzato attraverso quella che comunemente viene chiamata fabric, una componente del router che altro non è che una matrice di commutazione (di solito composta da pochi chip dedicati, poiché le linecard sono pochine). Vedete una qualche analogia tra questa Fabric e la IP Fabric dei Data Center ?
LE RETI DI CLOS NEI DATA CENTER
Considerate per un attimo la figura sopra della matrice di commutazione multistadio (in particolare nella figura la matrice è tristadio) e pensate di eseguire le seguenti due operazioni:
Sostituite a ciascuna di matrice di commutazione elementare un switch, con un numero di porte coincidente con il numero di “fili” di ingresso e di interconnessione. Ad esempio, la matrice di commutazione elementare in alto a sinistra della figura, sarà sostituita da un switch che avrà n fili in ingresso e m fili di interconnessione verso le m matrici di commutazione elementari al centro.
Ripiegate le uscite sugli ingressi (folded Clos network) e ruotate di 90° in senso antiorario il tutto (il senso di questa rotazione è solo formale, non servirebbe ma poiché c’è un linguaggio associato a questa modalità di rappresentazione, bisogna adeguarsi).
Il risultato è la figura seguente:
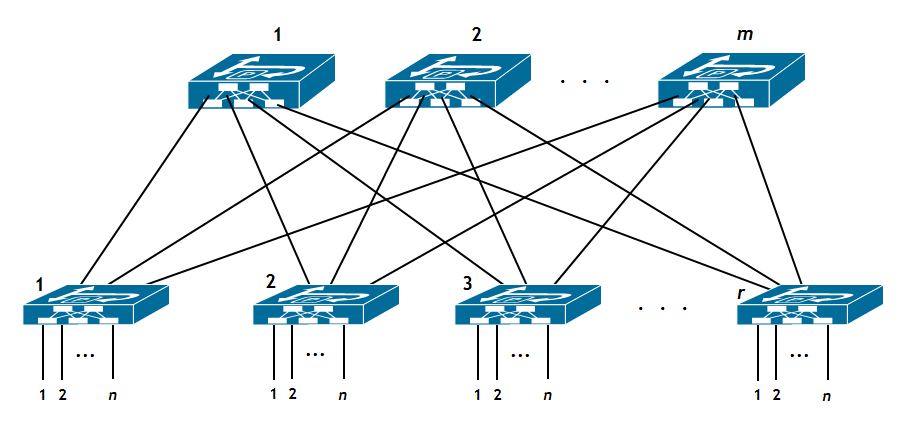
ossia, una topologia di rete molto semplice, comunemente nota come Leaf-and-Spine, o anche Rete di Clos a tre stadi. Gli switch in basso sono i Leaf e ciascuno di questi ha in totale n + m porte, di cui n lato accesso (dove normalmente sono attestati dei server) e m uplink verso gli switch in alto. Questi ultimi sono gli Spine e sono in numero di norma abbastanza inferiore ai Leaf.
Ciascuno Spine ha r porte downlink verso ciascuno degli r Leaf ed eventualmente un certo numero di (poche) porte uplink verso dei gateway che consentono il forwarding del traffico verso altri DataCenter, verso l’Internet, verso la rete di un ISP, ecc. .
NOTA: La rete di Clos della figura si chiama a tre stadi poiché a partire da un dispositivo collegato ad una porta di un Leaf, per raggiungere un qualsiasi altro dispositivo collegato ad una porta di un Leaf diverso, vengono attraversati tre apparati: Leaf di partenza, uno Spine e il Leaf di arrivo. In Data Center di grandi dimensioni, come ad esempio quelli realizzati da fornitori di servizi Cloud pubblici, è possibile estendere a 5 il numero di stadi, aggiungendo un terzo livello di apparati. Si noti che talvolta più che parlare di stadi si parla di Livelli. Ad esempio, la rete di Clos della figura è a due Livelli: i Leaf sono il Livello 2 e gli Spine il Livello 1. Parlare di Livelli o di stadi è equivalente, direi che è solo un questione cosmetica. Infatti è chiaro che al Livello 2 corrispondono gli stadi 1 e 3 e al Livello 1 lo stadio 2. Un discorso analogo vale per le reti di Clos a 5 stadi (dove i Livelli sono 3 !).
A questo punto sorge spontanea la domanda: ma quali sono i vantaggi di una topologia di tipo Leaf-and-Spine ? Eccone alcuni:
È semplice e altamente scalabile. Pensate ad esempio ad una crescita del vostro DataCenter, che richiede un numero maggiore di porte di accesso rispetto a quelle disponibili. In sintesi, è necessario aggiungere un nuovo Leaf(o più di uno). Se gli Spine hanno porte downlink a sufficienza, tutto si risolve nell’acquistare uno o più switch che avranno il ruolo di Leaf, e connetterli agli Spine. Tutti gli altri Leaf non subiranno alcun cambiamento, né fisico, né in termini di configurazioni aggiuntive (in molti casi). (NOTA: questo tipo di scalabilità viene detto nella letteratura anglo-sassone “scale out”, a differenza della scalabilità di tipo “scale up” che invece consente di ampliare la capacità della rete aumentando la banda disponibile e la potenza degli apparati (e non il loro numero). Scusatemi se vi faccio queste precisazioni, ma spesso nei documenti in inglese trovate questi termini e adesso sapete quale è la differenza)
Consente una più agevole distribuzione del traffico tra i vari link. Infatti, dal punto di vista del routing di Livello 3, a meno che non alteriate le metriche delle interfacce, avete sempre a disposizione da ciascun Leaf, mpercorsi a minimo costo disponibili, verso ciascun altro Leaf. Ciò consente di effettuare un ECMP (Equal Cost Multi-Path, meglio noto come Load Balancing) del traffico inter-Leaf (che per analogia geografica viene spesso indicato come Est-Ovest) tra tutti gli m percorsi disponibili.
Consente l’utilizzo di switch in configurazione (fisica) fissa, che sono molto meno costosi di switch basati suchassiscon slot Questo aspetto sarà più chiaro nella prossima sezione, quando illustrerò un po’ di “aritmetica” associata alle topologie Leaf-and-Spine.
Consente una sostanziale riduzione di CAPEX e OPEX. Infatti, la possibilità di utilizzare switch in configurazione fissa, preferibilmente utilizzando lo stesso Hardware, consente notevoli economie di scala, con conseguente riduzione dei costi di deployment(CAPEX). Tenete conto che la parte networking di un Data Center incide per il 10-15% del costo complessivo, non molto, ma non trascurabile. Poi, avere una topologia semplice, apparati uguali e con configurazioni praticamente identiche riduce di molto anche le spese di esercizio (OPEX) del Data Center.
Come sempre, non sono però solo rose. Una topologia Leaf-and-Spine richiede un cablaggio più complesso e costoso. Inoltre, la scalabilità ha un suo limite, legato al numero delle porte disponibili. Si rischia di arrivare al punto di non avere più porte disponibili. Anche questo si capirà meglio nella prossima sezione. La soluzione in questo caso è aumentare il numero degli stadi (o dei Livelli), passando ad esempio da reti a tre stadi (due livelli) a reti a 5 stadi (tre livelli).
UN PO’ DI CONTI
Vediamo ora di fare un po’ di conti, con degli esempi reali. Ma prima di fare “i compiti di aritmetica” (perché di aritmetica si tratta) è bene avere chiari alcuni aspetti di progettazione, che condizionano il risultato finale. Il punto è: quali sono i dati di partenza ? Bene, due sono i dati da cui partire (poi comunque ne servono anche altri):
Il fattore di sovraccarico (oversubscription ratio) : è il rapporto tra la banda totale lato accesso e la banda totale degli uplinkdi un Leaf. Ad esempio, supponiamo di avere un switch con 48 porte da 10 Gibt/s da utilizzare lato accesso e 4 porte da 40 Gbit/s da utilizzare come uplink. Il fattore di sovraccarico è (10*48)/(4*40) = 3, di solito espresso come 3:1. Non ho fatto questo esempio a caso perché nella pratica corrente, il fattore di sovraccarico 3:1 è considerato il giusto bilanciamento tra costo e prestazioni (perché è ovvio che un fattore di sovraccarico basso comporta migliori prestazioni ma un costo più elevato; viceversa per un fattore di sovraccarico alto).
Il numero totale di porte di accesso necessarie. Questo consente di determinare il numero di Leafnecessari, nota la disponibilità di porte di accesso di ciascun Leaf.
Farò ora un paio di esempi, il primo per un Data Center di medie dimensioni, il secondo per un Data Center di grandi dimensioni, che mi consentirà anche di introdurre il concetto di Virtual Spine (vSpine).
Per il primo esempio, partiamo da questi dati:
Fattore di sovraccarico = 3:1.
Numero di porte di accesso necessarie = 700.
Disponibilità di switch Leaf con 48 porte di accesso a 10 Gbit/s e 4 porte uplink a 40 Gbit/s (di switch di questo tipo in commercio ne trovate a iosa).
Disponibilità di switch Spine con 24 porte a 40 Gbit/s (anche di switch di questo tipo in commercio ne trovate a iosa).
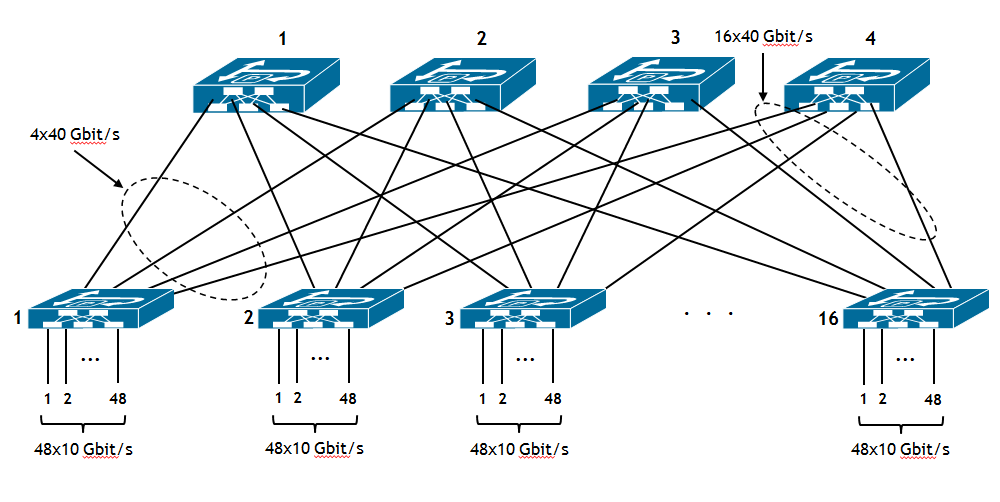
Il numero di Leaf necessari si calcola facendo il rapporto 700/48 e prendendo l’intero superiore. In questo caso viene fuori 15. Per avere un po’ di margine per future espansioni, supponiamo di “acquistare” 16 switch Leaf, per un totale di 48*16 = 768 porte di accesso.
Ora, per far si che il fattore di sovraccarico sia 3:1, utilizziamo le 4 porte uplink da 40 Gbit/s verso gli Spine. Ne consegue che abbiamo bisogno di 4 Spine. Poiché ciascun Spine è collegato a tutti i Leaf, delle 24 porte disponibili a 40 Gbit/s, se ne utilizzano 16, le altre sono a disposizione per eventuali collegamenti verso i gateway per l’interconnessione con altri Data Center, o per l’accesso a Internet, o per l’accesso ad altri servizi forniti da un ISP. Il risultato finale è riassunto nella figura seguente.
Vi lascio un piccolo esercizio. Supponendo di partire con questi dati:
Fattore di sovraccarico = 3:1.
Disponibilità di switch Leaf con 96 porte di accesso a 10 Gbit/s e 8 porte uplink a 40 Gbit/s (es. Juniper QFX5100-96S).
Disponibilità di switch Spine con 32 porte a 40 Gbit/s (es. Juniper QFX5100-24Q).
La domanda è la seguente: quale è il numero massimo di porte di accesso a 10 Gbit/s che è possibile realizzare ? (Risposta : 3,072 se utilizzate tutte le porte disponibili sugli Spine; se invece lasciate due porte libere sugli Spine per eventuali collegamenti verso una coppia di gateway, 2.880).
Ora voglio fare un esempio di un Data Center di grandi dimensioni. Invece di partire dal numero di porte necessarie, farò un calcolo simile all’esercizio che vi ho lasciato. L’obiettivo è costruire un Data Center che abbia disponibili almeno 40.000 porte di accesso a 10 Gbit/s.
Se utilizzassi una architettura a tre stadi (= due livelli) come quella dell’esempio precedente utilizzando la stessa tipologia di macchine, con 4 conti ci si rende conto che è mission impossible. Infatti, un rapido calcolo mostra che per avere più di 40.000 porte in accesso avrei bisogno di almeno 417 switch. Il problema però non è tanto questo (basta convincere il CFO a sganciare soldi a sufficienza !), ma è che ci vorrebbero Spine da almeno 417 porte, che in commercio non fa nessuno (o almeno, io non li ho mai visti). Come risolvere l’arcano ? Partiamo da una considerazione: quali proprietà deve avere uno Spine ? Bene, a grandi linee queste: deve avere un fattore di sovraccarico 1:1 e generalmente interfacce a 40 Gbit/s (in futuro magari a 100 Gbit/s).
Se utilizzassi una architettura a tre stadi (= due livelli) come quella dell’esempio precedente utilizzando la stessa tipologia di macchine, con 4 conti ci si rende conto che è mission impossible. Infatti, un rapido calcolo mostra che per avere più di 40.000 porte in accesso avrei bisogno di almeno 417 switch. Il problema però non è tanto questo (basta convincere il CFO a sganciare soldi a sufficienza !), ma è che ci vorrebbero Spine da almeno 417 porte, che in commercio non fa nessuno (o almeno, io non li ho mai visti). Come risolvere l’arcano ? Partiamo da una considerazione: quali proprietà deve avere uno Spine ? Bene, a grandi linee queste: deve avere un fattore di sovraccarico 1:1 e generalmente interfacce a 40 Gbit/s (in futuro magari a 100 Gbit/s).
Allora l’idea è questa: costruire degli Spine virtuali (vSpine) costituiti a loro volta da reti di Clos a tre stadi, ma con fattore di sovraccarico 1:1. Quindi utilizzare questi Spine virtuali come fossero a tutti gli effetti degli Spine fisici.
Facciamo un po’ di conti. Supponiamo di utilizzare per gli Spine virtuali, switch con 32 porte da 40 Gbt/s (es. Juniper QFX5100-24Q con due slot aggiuntivi da 4x40 Gbit/s ciascuno). Domanda: quale è la rete di Clos a tre stadi con il numero massimo di porte di accesso a 40 Gbit/s, ipotizzando un fattore di sovraccarico 1:1 ? Vi lascio i conticini come esercizio. Il risultato è 512x40 Gbit/s. Ora, considerando questa rete di Clos come un unico Spine (e ciò è lecito, il fattore di sovraccarico è 1:1 e le porte sono a 40 Gbit/s), per il nostro Data Center è come se avessimo Spine (virtuali) con 512 porte a 40 Gbit/s, e quindi possiamo creare una rete di Clos con un massimo di 512 Leaf. Ipotizzando che ciascuno di questi abbia 96 porte a 10 Gbit/s, ecco qua che abbiamo realizzato una IP Fabric con 96x512 = 49.152 porte di accesso a 10 Gbit/s (una roba mostruosa, ma si può fare di meglio, basta avere sufficiente budget !). Il risultato finale è una rete di Clos a 5 stadi (3 livelli) ed è riassunto nella figura seguente.
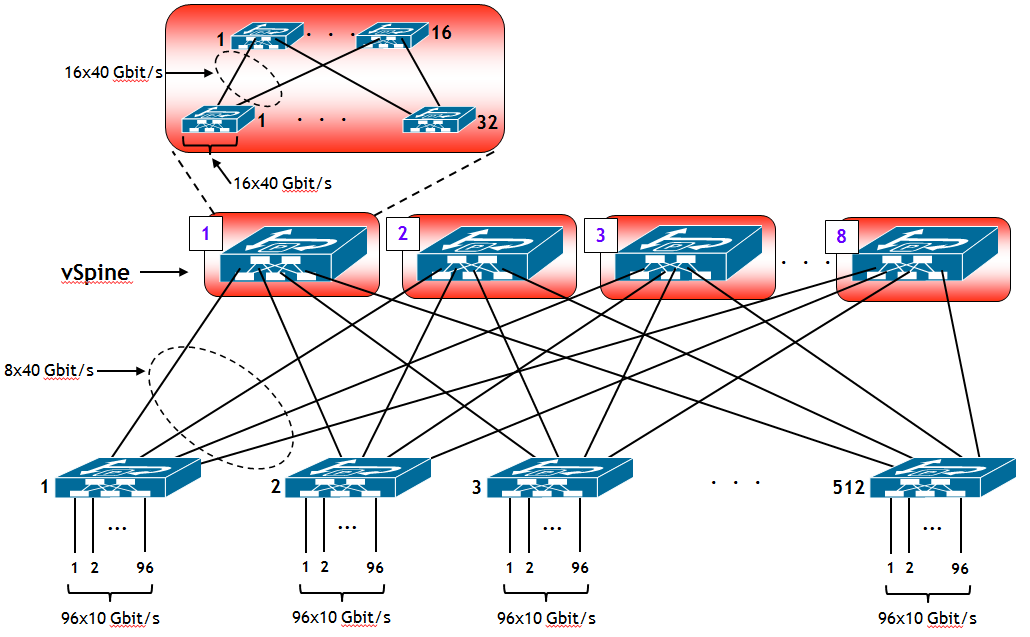
Sempre per avere un’idea di quali dimensioni stiamo parlando, facciamo un conto rapido di quante macchine virtuali possiamo gestire con un simile mostro. Faccio un’ipotesi conservativa, per ciascun server fisico è possibile attivare 50 macchine virtuali (con lo sviluppo attuale dei server questo numero è sicuramente basso, ma come ho detto voglio essere conservativo). Inoltre, suppongo che ciascun server fisico abbia un doppio collegamento a 10 Gbit/s verso la IP Fabric. In totale posso quindi attestare 49.152/2 = 24.576 server fisici, e quindi attivare 24.576*50 = 1.228.800 macchine virtuali ! Quanti sono i Data Center che hanno bisogno di gestire un così elevato numero di macchine virtuali? E tenete conto che sono stato molto conservativo !
E tenete anche conto che la stragrande maggioranza dei Data Center non supera i 1.000 server (virtuali). E che con questi numeri potete costruirvi un Data Center con un solo rack da 42RU ! (leggetevi questo post, estremamente interessante). E considerate anche, come dice il mio amico Ivan Pepelnjak, uno dei maggiori esperti al mondo dinetworking, che per la stragrande maggioranza dei Data Center sono sufficienti solo 2 switch Top-of-Rack (vedi questo post) !
QUALE IGP NELLE RETI DI CLOS ?
Questa potrebbe sembrare a prima vista una domanda sciocca. Ma come, con tutta l’esperienza che c’è sul campo del routing delle reti ISP, che sono molto più grandi di un Data Center anche di grandi dimensioni, perché dovremmo preoccuparci di quali protocolli di routing scegliere? Ebbene si, il problema potrebbe porsi nei Data Center di grandi dimensioni, dove i classici protocolli IGP (OSPF e IS-IS, gli altri nemmeno li considero) potrebbero portare a seri problemi di scalabilità. Che fare allora ?
Nei Data Center di dimensioni medio-piccole, dove la IP Fabric è costituita da poche decine di router, il problema non si pone, è possibile utilizzare un classico protocollo IGP come OSPF o IS-IS. Con qualche accorgimento progettuale, ben noto a chi lavora con i protocolli IGP (NOTA: la lista seguente è da considerarsi minimale, non certamente esaustiva):
Utilizzate OSPF in area singola o IS-IS a livello singolo. Se una IP Fabricha modeste dimensioni, ha poco senso partizionare il dominio di routing. Se da un lato la partizione aumenta la stabilità della IP Fabric, dall’altro aumenta la complessità dei LSDB e quindi di troubleshooting.
Utilizzate un piano di numerazione semplice e coerente. Ad esempio, utilizzate per tutti gli indirizzi IP dell’infrastruttura della IP Fabric, indirizzi (privati) della RFC 1918, possibilmente tratti da una unica grande subnet IP. Per le Loopback utilizzate maschere /32 nel caso IPv4 e /128 nel caso IPv6, per i collegamenti punto-punto maschere /30 o meglio /31 nel caso IPv4 e /64 o /127 nel caso IPv6 (su quest’ultima scelta i pareri non sono concordi, ma è una discussione di lana caprina !).
Annunciate solo ciò che serve, e cercate di evitare una grande quantità di redistribuzioni di subnetesterne nel dominio di routing. Potreste incorrere in seri problemi di scalabilità. Questo è il vero punto debole di OSPF e IS-IS.
Mantenete le configurazioni semplici, ma eleganti. Ad esempio, definite le interfacce di Loopback come passive, definite tutti i collegamenti Leaf-Spine come punto-punto (NOTA: questi collegamenti sono Ethernet, e se non comunicate al processo di routing di considerarli come punto-punto, di default su questi collegamenti vengono eletti DR e BDR nel caso di OSPF e DIS nel caso di IS-IS, cosa perfettamente inutile (a dire il vero anche un po’ dannosa) nei collegamenti punto-punto). Inoltre, non alterate le metriche di default, ne potrebbero risentire le proprietà di Load Balancing.
Per i Data Center di grandi dimensioni, dove la IP Fabric è costituita da centinaia di L3-switch (ossia, router con molte interfacce Ethernet), il discorso cambia. Ma prima di approfondirlo, dobbiamo chiederci: quali caratteristiche dovrebbe avere un protocollo di routing in una IP Fabric di grandi dimensioni ? Bene, questo è un elenco:
Essere scalabile in termini di gestione dei prefissi IP, ossia poter gestire senza problemi tabelle di decine di migliaia di prefissi IP.
Avere una implementazione semplice, stabile e supportata da tutti i principali costruttori, così da consentire l’interlavoro senza problemi.
Minimizzare l’ambito di propagazione di un fuori servizio di un nodo o di un link, in modo da avere una rete più stabile ed avere tempi di convergenza molto contenuti (dell’ordine delle decine di msec).
Consentire un minimo di gestione del traffico, preferibilmente attraverso un controllo diretto del Next-Hop, utilizzando metriche facilmente manipolabili.
Consentire in modo semplice il multipath (o ECMP o Load balancing, tutti sinonimi).
Infine, dovrebbe poter funzionare senza l’ausilio di altri protocolli di routing.
Bene, a questo punto la domanda sorge spontanea: quale è il protocollo che soddisfa tutti questi requisiti ? La risposta è semplice (e per qualche verso un po’ inaspettata): il caro vecchio BGP. Ebbene si, nei Data Center di grandi dimensioni si va facendo strada l’idea di utilizzare il BGP come (unico e solo) protocollo IGP, tanto che si parla di retiIGP-free. La proposta è partita da quel genio del Networking che è Petr Lapukhov che è co-autore di questo draft IETF in cui descrive vari aspetti motivazionali e decisionali legati all’utilizzo di BGP come unico e solo protocollo di routing di una IP Fabric. Ma su questo ritornerò in un prossimo post, questo termina qui.
CONCLUSIONI
Le IP Fabric dei moderni Data Center utilizzano topologie mutuate dalle matrici di commutazione multistadio delle vecchie centrali telefoniche elettromeccaniche (corsi e ricorsi della storia), proposte da Charles Clos nei primi anni 50 del secolo scorso. Le topologie multistadio hanno il vantaggio di essere semplici e molto scalabili e sono diventate ormai lo standard de facto delle IP Fabric nei Data Center. In funzione della grandezza del Data Center, vengono utilizzate topologie a tre stadi (due livelli) o a cinque stadi (tre livelli). Un aspetto interessante riguarda il protocollo IGP. Come ho scritto nell’ultima sezione di questo post, per le IP Fabric dei Data Center di grandi dimensioni è stato proposto l’utilizzo, in maniera un po’ atipica rispetto alle nostre (almeno alle mie) concezioni, del solo protocollo BGP. Approfondirò questo interessante argomento in un prossimo post.
Coming up next... il Capitolo 11 del libro su IS-IS (e il Capitolo 10 che fine ha fatto ?).
Pubblicato in
ReissBlog
Etichettato sotto
Domenica, 17 Gennaio 2016 17:11
VXLAN: EVOLUZIONE DEL PIANO DI CONTROLLO
In un post precedente, ho illustrato il nuovo standard VXLAN (RFC 7348), che consente di eliminare molti dei problemi introdotti dal classico concetto di VLAN, ampiamente utilizzato per segmentare logicamente le reti di Livello 2.
Ricordo che l’idea di base delle VXLAN è quella ben nota delle overlay virtual networks, ossia la possibilità di realizzare una rete logica (virtuale) di Livello 2 sopra una rete fisica esistente. La rete fisica esistente (la rete underlay !) è in questo caso una banale rete IP (v4 o v6, non fa differenza), ma potrebbe essere anche un altro tipo di rete.
Il problema più importante nell’implementazione delle VXLAN è la determinazione delle mappe MAC-to-VTEP. Nel post precedente introduttivo sulle VXLAN, ho illustrato come il MAC learning, sia locale che remoto, in accordo alle specifiche della RFC 7348, avviene utilizzando esclusivamente il piano dati. Ma questo costringe a introdurre sulla rete IP underlay un protocollo di routing multicast (PIM-SM/SSM o più spesso PIM-BiDir), e come spiegato ampiamente nel post precedente, questo ha i suoi problemi sia in termini di scalabilità che di gestione della rete underlay.
Per questa ragione sono state introdotte soluzioni alternative basate sull'utilizzo di un piano di controllo. È possibile individuare al momento tre fasi di sviluppo delle VXLAN (NOTA: questa storia di dividere l’evoluzione delle VXLAN in tre fasi è strettamente personale; non c’è niente di ufficiale o di standard in questa suddivisione):
Ricordo che l’idea di base delle VXLAN è quella ben nota delle overlay virtual networks, ossia la possibilità di realizzare una rete logica (virtuale) di Livello 2 sopra una rete fisica esistente. La rete fisica esistente (la rete underlay !) è in questo caso una banale rete IP (v4 o v6, non fa differenza), ma potrebbe essere anche un altro tipo di rete.
Il problema più importante nell’implementazione delle VXLAN è la determinazione delle mappe MAC-to-VTEP. Nel post precedente introduttivo sulle VXLAN, ho illustrato come il MAC learning, sia locale che remoto, in accordo alle specifiche della RFC 7348, avviene utilizzando esclusivamente il piano dati. Ma questo costringe a introdurre sulla rete IP underlay un protocollo di routing multicast (PIM-SM/SSM o più spesso PIM-BiDir), e come spiegato ampiamente nel post precedente, questo ha i suoi problemi sia in termini di scalabilità che di gestione della rete underlay.
Per questa ragione sono state introdotte soluzioni alternative basate sull'utilizzo di un piano di controllo. È possibile individuare al momento tre fasi di sviluppo delle VXLAN (NOTA: questa storia di dividere l’evoluzione delle VXLAN in tre fasi è strettamente personale; non c’è niente di ufficiale o di standard in questa suddivisione):
- Fase 1: MAC learning interamente sul piano dati con utilizzo di un protocollo di routing multicast sulla rete underlay. E questo lo abbiamo trattato ampiamente, da un punto di vista teorico, nel post precedente. In questo post mi limiterò solo a illustrare un piccolo test di laboratorio per mostrare un esempio reale di applicazione.
- Fase 2: sempre MAC learning sul piano dati, ma senza ricorrere a un protocollo di routing multicast. L’idea è di utilizzare un meccanismo di Head-end replication (Unicast-only VXLAN) per il traffico BUM.
- Fase 3: utilizzare un vero e proprio piano di controllo per annunciare gli indirizzi MAC degli Host (e se possibile anche gli indirizzi IP associati). Questo piano di controllo è in pratica costituito dal BGP, o meglio dalla sua estensione ampiamente vista nel modello EVPN. Utilizzare un piano di controllo riduce notevolmente il problema del flooding e se il piano di controllo è ben fatto, consente di affrontare in modo efficiente eventuali problemi legati al multi-homing e le problematiche di Load Balancing.
In ogni caso, qualsiasi sia la fase di evoluzione delle VXLAN, il MAC learning avviene sempre in due fasi. La prima è di tipo classico, ed è un MAC learning locale. Tramite questo processo l’interfaccia VTEP “impara” quali sono gli MAC locali, ossia degli host che sono “direttamente connessi” alla macchina (fisica o virtuale) dove è definita l’interfaccia VTEP. La seconda è quella che utilizza o routing multicast, o Head-end replication, o il piano di controllo BGP EVPN.
VXLAN FASE 1: TEST DI LABORATORIO
L’utilizzo del routing multicast per apprendere le mappe MAC-to-VTEP è stato ampiamente descritto nel post precedente, per cui rimando a quel post per la teoria. Mi limiterò qui a illustrare una piccola prova di laboratorio, eseguita utilizzando tre router (virtuali) Cisco CSR1kv e due router “ordinari” (sempre Cisco, ma avrei potuto utilizzare qualsiasi altra marca). La topologia utilizzata per il test è riportata nella figura seguente.
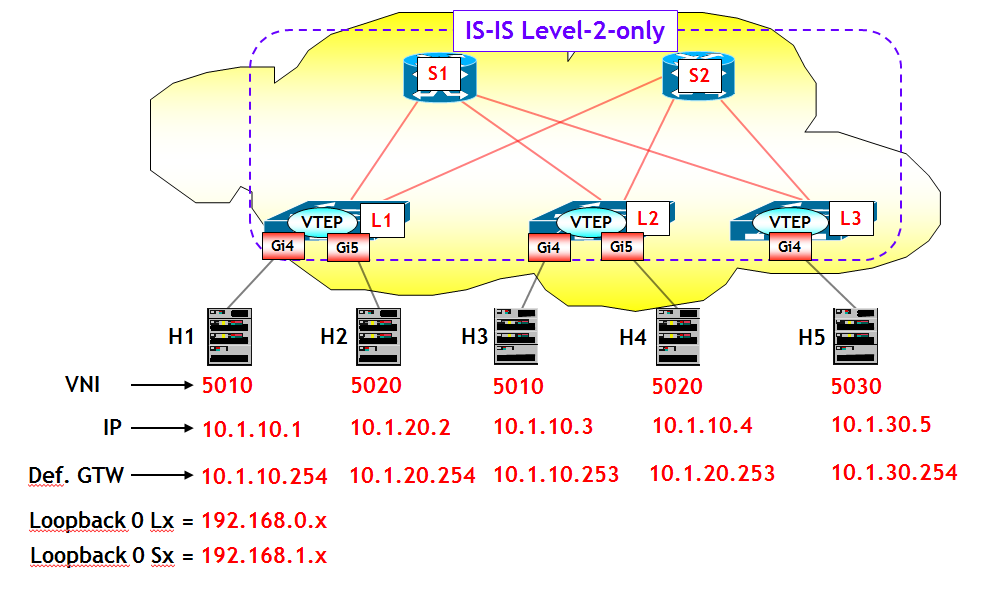
Per chi di voi avesse familiarità con le moderne tecnologie dei Data Center, la topologia utilizzata è un classica topologia di tipo Leaf-and-Spine, con due Spine (i router S1 e S2) e tre Leaf (L1, L2 e L3). I Leaf sono di solito switch multilayer fisici che svolgono il ruolo di ToR (Top of Rack). Gli Spine sono invece classici router, che di norma non hanno bisogno di alcunché, se non del routing IP classico e al massimo un po’ di MPLS (comunque non indispensabile). Su questo tipo di architettura e i suoi vantaggi, tornerò in seguito con un post ad hoc. La funzione VTEP è in questo esempio localizzata direttamente nei Leaf, ma potrebbe anche essere integrata negli Hypervisor dei server. In quest'ultimo caso, i Leaf svolgerebbero, al pari degli Spine, solo le semplici funzioni di Livello 3.
Nel test di laboratorio ho utilizzato come Leaf i tre CSR1kv (che utilizzano l’IOS XE) e come Spine due router con IOS classico. Come server ho utilizzato 5 server Linux. Tutto l’ambiente è stato realizzato tramite il software di emulazione Cisco VIRL di un mio studente (regolarmente acquistato !).
La rete underlay utilizza come protocollo di routing unicast IS-IS in area singola, e singolo livello 2 di routing. Sulla rete underlay è stato poi configurato il protocollo di routing multicast PIM-BiDir, utilizzando come metodo di selezione del Rendezvous-Point il Bootstrap Router (che ricordo, è standard). Una nota importante, è necessario implementare il PIM-BiDir, il semplice PIM-SM non è supportato.
Su questa rete sono state configurate tre VXLAN, aventi rispettivamente VNI 5010, 5020 e 5030. La VXLAN 5030 ha un solo Host (H5), connesso al Leaf L3. L’ho inserito solo per simulare un po’ di inter-VXLAN routing. In una ipotetica applicazione pratica, H5 potrebbe essere un Database a cui possono accedere sia gli Host della VXLAN 5010 che quelli della VXLAN 5020. Le tre VXLAN 5010, 5020 e 5030 utilizzano per il traffico BUM rispettivamente i tre gruppi multicast 228.1.1.10, 228.1.1.20 e 228.1.1.30.
Per brevità riporto di seguito le configurazioni rilevanti del Leaf L1, lato Host. Le altre configurazioni, tra cui anche quelle dei Leaf lato rete underlay e dei due Spine, sono nel file .txt allegato a questo post.
interface nve 1
no ip address
member vni 5010 mcast-group 228.1.1.10 ! Gruppo multicast associato a VNI 5010
member vni 5020 mcast-group 228.1.1.20 ! Gruppo multicast associato a VNI 5020
source-interface lo0 ! Indirizzo IP sorgente per interfaccia VTEP (= NVE)
no shutdown
exit
!
interface gi4
no ip address
no shutdown
service instance 10 ethernet
encapsulation untagged
exit
exit
!
interface gi5
no ip address
no shutdown
service instance 20 ethernet
encapsulation untagged
exit
exit
!
bridge-domain 10
member gi4 service-instance 10
member vni 5010
exit
!
bridge-domain 20
member gi5 service-instance 20
member vni 5020
exit
!
interface BDI10
ip address 10.1.10.254 255.255.255.0 ! Default-Gateway per VNI 5010
ip router isis
no shutdown
exit
!
interface BDI20
ip address 10.1.20.254 255.255.255.0 ! Default-Gateway per VNI 5020
ip router isis
no shutdown
exit
La configurazione è abbastanza auto-esplicativa per cui lascio gli ulteriori commenti al lettore. Voglio solo mostrare invece il risultato di alcuni comandi di tipo “show” eseguiti su L1.
L1# show nve interface nve1 detail
Interface: nve1, State: Admin Up, Oper Up Encapsulation: Vxlan
source-interface: Loopback0 (primary:192.168.0.1 vrf:0)
Pkts In Bytes In Pkts Out Bytes Out
15 1518 16 1610
L1# show nve vni
Interface VNI Multicast-group VNI state
nve1 5020 228.1.1.20 Up
nve1 5010 228.1.1.10 Up
L1# show nve peers
Interface Peer-IP VNI Peer state
nve1 192.168.0.2 5020 -
nve1 192.168.0.2 5010 -
Il primo comando consente di verificare lo stato dell’interfaccia VTEP, indicata nei router Cisco come “nve” (network virtualization end-point), il tipo di incapsulamento utilizzato, l’indirizzo IP dell’interfaccia VTEP (= 192.168.0.1, coincidente con l’indirizzo IP dell’interfaccia Loopback 0 di L1) e infine il traffico entrante/uscente dall’interfaccia, ossia la quantità di pacchetti che vengono incapsulati con una intestazione VXLAN (riportati nella visualizzazione come “Pkts Out”) e che vengono decapsulati (riportati nella visualizzazione come “Pkts In”).
Il secondo comando “show” mostra i VNI delle VXLAN associati all’interfaccia VTEP e il corrispondente gruppo multicast associato.
Infine, il terzo comando “show” mostra i VXLAN peers, ossia l’indirizzo IP delle interfacce VTEP e delle VNI presenti nel peer. Si noti che per apprendere i VXLAN peers, ci deve essere prima del traffico tra due Host della stessa VXLAN, appartenenti ai due VXLAN peers.
Con il comando “show” seguente invece è possibile vedere come avviene il MAC learning per il “bridge-domain 10”, che corrisponde al segmento VXLAN con VNI 5010. Inizialmente il comando non mostra alcun indirizzo MAC:
L1# show bridge-domain 10
Bridge-domain 10 (2 ports in all)
State: UP Mac learning: Enabled
Aging-Timer: 300 second(s)
GigabitEthernet4 service instance 10
vni 5010
AED MAC address Policy Tag Age Pseudoport
Dopo aver eseguito un “ping 10.1.10.3” verso l’Host H3 appartenente allo stesso segmento VXLAN 5010, si ottiene il seguente risultato:
L1# show bridge-domain 10
Bridge-domain 10 (2 ports in all)
State: UP Mac learning: Enabled
Aging-Timer: 300 second(s)
GigabitEthernet4 service instance 10
vni 5010
AED MAC address Policy Tag Age Pseudoport
0 FA16.3E1C.2D0C forward dynamic 273 nve1.VNI5010, VxLAN ! MAC remoto
src: 192.168.0.1 dst: 192.168.0.2
0 FA16.3EF6.DBCB forward dynamic 272 GigabitEthernet4.EFP10 ! MAC locale
dal quale si evince che L1 ha “imparato” due indirizzi MAC:
VXLAN FASE 1: TEST DI LABORATORIO
L’utilizzo del routing multicast per apprendere le mappe MAC-to-VTEP è stato ampiamente descritto nel post precedente, per cui rimando a quel post per la teoria. Mi limiterò qui a illustrare una piccola prova di laboratorio, eseguita utilizzando tre router (virtuali) Cisco CSR1kv e due router “ordinari” (sempre Cisco, ma avrei potuto utilizzare qualsiasi altra marca). La topologia utilizzata per il test è riportata nella figura seguente.
Per chi di voi avesse familiarità con le moderne tecnologie dei Data Center, la topologia utilizzata è un classica topologia di tipo Leaf-and-Spine, con due Spine (i router S1 e S2) e tre Leaf (L1, L2 e L3). I Leaf sono di solito switch multilayer fisici che svolgono il ruolo di ToR (Top of Rack). Gli Spine sono invece classici router, che di norma non hanno bisogno di alcunché, se non del routing IP classico e al massimo un po’ di MPLS (comunque non indispensabile). Su questo tipo di architettura e i suoi vantaggi, tornerò in seguito con un post ad hoc. La funzione VTEP è in questo esempio localizzata direttamente nei Leaf, ma potrebbe anche essere integrata negli Hypervisor dei server. In quest'ultimo caso, i Leaf svolgerebbero, al pari degli Spine, solo le semplici funzioni di Livello 3.
Nel test di laboratorio ho utilizzato come Leaf i tre CSR1kv (che utilizzano l’IOS XE) e come Spine due router con IOS classico. Come server ho utilizzato 5 server Linux. Tutto l’ambiente è stato realizzato tramite il software di emulazione Cisco VIRL di un mio studente (regolarmente acquistato !).
La rete underlay utilizza come protocollo di routing unicast IS-IS in area singola, e singolo livello 2 di routing. Sulla rete underlay è stato poi configurato il protocollo di routing multicast PIM-BiDir, utilizzando come metodo di selezione del Rendezvous-Point il Bootstrap Router (che ricordo, è standard). Una nota importante, è necessario implementare il PIM-BiDir, il semplice PIM-SM non è supportato.
Su questa rete sono state configurate tre VXLAN, aventi rispettivamente VNI 5010, 5020 e 5030. La VXLAN 5030 ha un solo Host (H5), connesso al Leaf L3. L’ho inserito solo per simulare un po’ di inter-VXLAN routing. In una ipotetica applicazione pratica, H5 potrebbe essere un Database a cui possono accedere sia gli Host della VXLAN 5010 che quelli della VXLAN 5020. Le tre VXLAN 5010, 5020 e 5030 utilizzano per il traffico BUM rispettivamente i tre gruppi multicast 228.1.1.10, 228.1.1.20 e 228.1.1.30.
Per brevità riporto di seguito le configurazioni rilevanti del Leaf L1, lato Host. Le altre configurazioni, tra cui anche quelle dei Leaf lato rete underlay e dei due Spine, sono nel file .txt allegato a questo post.
interface nve 1
no ip address
member vni 5010 mcast-group 228.1.1.10 ! Gruppo multicast associato a VNI 5010
member vni 5020 mcast-group 228.1.1.20 ! Gruppo multicast associato a VNI 5020
source-interface lo0 ! Indirizzo IP sorgente per interfaccia VTEP (= NVE)
no shutdown
exit
!
interface gi4
no ip address
no shutdown
service instance 10 ethernet
encapsulation untagged
exit
exit
!
interface gi5
no ip address
no shutdown
service instance 20 ethernet
encapsulation untagged
exit
exit
!
bridge-domain 10
member gi4 service-instance 10
member vni 5010
exit
!
bridge-domain 20
member gi5 service-instance 20
member vni 5020
exit
!
interface BDI10
ip address 10.1.10.254 255.255.255.0 ! Default-Gateway per VNI 5010
ip router isis
no shutdown
exit
!
interface BDI20
ip address 10.1.20.254 255.255.255.0 ! Default-Gateway per VNI 5020
ip router isis
no shutdown
exit
La configurazione è abbastanza auto-esplicativa per cui lascio gli ulteriori commenti al lettore. Voglio solo mostrare invece il risultato di alcuni comandi di tipo “show” eseguiti su L1.
L1# show nve interface nve1 detail
Interface: nve1, State: Admin Up, Oper Up Encapsulation: Vxlan
source-interface: Loopback0 (primary:192.168.0.1 vrf:0)
Pkts In Bytes In Pkts Out Bytes Out
15 1518 16 1610
L1# show nve vni
Interface VNI Multicast-group VNI state
nve1 5020 228.1.1.20 Up
nve1 5010 228.1.1.10 Up
L1# show nve peers
Interface Peer-IP VNI Peer state
nve1 192.168.0.2 5020 -
nve1 192.168.0.2 5010 -
Il primo comando consente di verificare lo stato dell’interfaccia VTEP, indicata nei router Cisco come “nve” (network virtualization end-point), il tipo di incapsulamento utilizzato, l’indirizzo IP dell’interfaccia VTEP (= 192.168.0.1, coincidente con l’indirizzo IP dell’interfaccia Loopback 0 di L1) e infine il traffico entrante/uscente dall’interfaccia, ossia la quantità di pacchetti che vengono incapsulati con una intestazione VXLAN (riportati nella visualizzazione come “Pkts Out”) e che vengono decapsulati (riportati nella visualizzazione come “Pkts In”).
Il secondo comando “show” mostra i VNI delle VXLAN associati all’interfaccia VTEP e il corrispondente gruppo multicast associato.
Infine, il terzo comando “show” mostra i VXLAN peers, ossia l’indirizzo IP delle interfacce VTEP e delle VNI presenti nel peer. Si noti che per apprendere i VXLAN peers, ci deve essere prima del traffico tra due Host della stessa VXLAN, appartenenti ai due VXLAN peers.
Con il comando “show” seguente invece è possibile vedere come avviene il MAC learning per il “bridge-domain 10”, che corrisponde al segmento VXLAN con VNI 5010. Inizialmente il comando non mostra alcun indirizzo MAC:
L1# show bridge-domain 10
Bridge-domain 10 (2 ports in all)
State: UP Mac learning: Enabled
Aging-Timer: 300 second(s)
GigabitEthernet4 service instance 10
vni 5010
AED MAC address Policy Tag Age Pseudoport
Dopo aver eseguito un “ping 10.1.10.3” verso l’Host H3 appartenente allo stesso segmento VXLAN 5010, si ottiene il seguente risultato:
L1# show bridge-domain 10
Bridge-domain 10 (2 ports in all)
State: UP Mac learning: Enabled
Aging-Timer: 300 second(s)
GigabitEthernet4 service instance 10
vni 5010
AED MAC address Policy Tag Age Pseudoport
0 FA16.3E1C.2D0C forward dynamic 273 nve1.VNI5010, VxLAN ! MAC remoto
src: 192.168.0.1 dst: 192.168.0.2
0 FA16.3EF6.DBCB forward dynamic 272 GigabitEthernet4.EFP10 ! MAC locale
dal quale si evince che L1 ha “imparato” due indirizzi MAC:
- Quello locale di H1 (MAC = FA16.3EF6.DBCB), raggiungibile attraverso la (pseudo-)porta GigabitEthernet4.EFP10 (NOTA: EFP10 indica l’Ethernet Flow Point associato all’istanza di servizio 10).
- Quello remoto di H3 (MAC = FA16.3E1C.2D0C), raggiungibile attraverso la (pseudo-)porta nve1.VNI5010, con incapsulamento VxLAN.
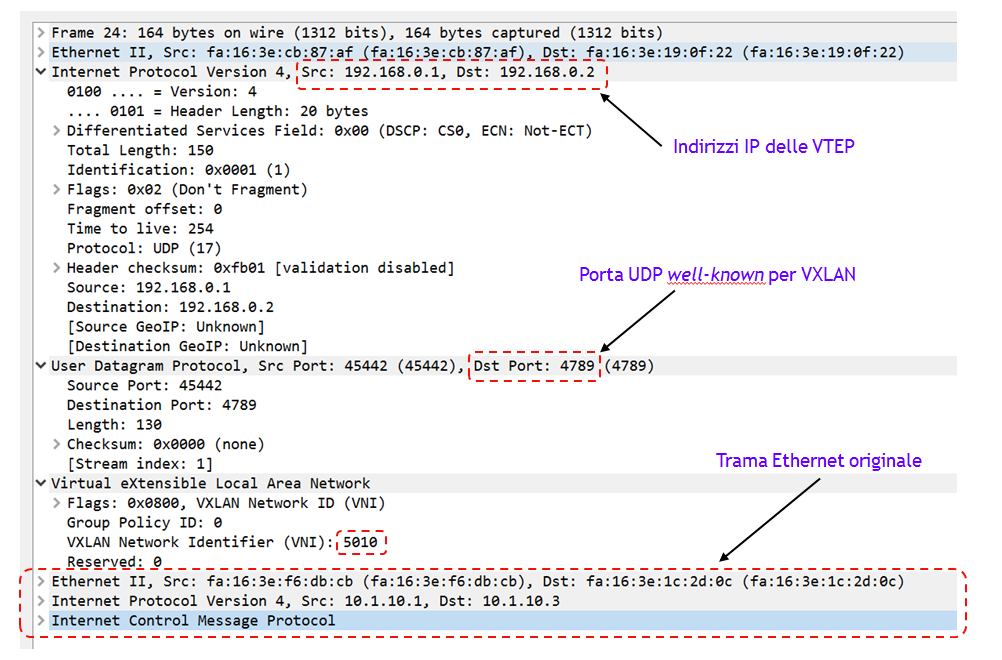
La figura seguente riporta la cattura di un pacchetto VXLAN, analizzato con wireshark. Il pacchetto trasporta uno degli ICMP Echo Request inviati da H1 a H3.
Infine, per completare la prova, ho eseguito un ping da H1, che appartiene al segmento VXLAN 5010, verso l’Host H5, che appartiene invece al segmento VXLAN 5030:
tt@H1:~$ ping 10.1.30.5
PING (10.1.30.5) 56(84) bytes of data.
64 bytes from localhost (10.1.30.5): icmp_seq=1 ttl=64 time=0.032 ms
64 bytes from localhost (10.1.30.5): icmp_seq=2 ttl=64 time=0.072 ms
64 bytes from localhost (10.1.30.5): icmp_seq=3 ttl=64 time=0.054 ms
64 bytes from localhost (10.1.30.5): icmp_seq=4 ttl=64 time=0.056 ms
64 bytes from localhost (10.1.30.5): icmp_seq=5 ttl=64 time=0.083 ms
^C
--- localhost ping statistics ---
5 packets transmitted, 5 received, 0% packet loss, time 3999ms
rtt min/avg/max/mdev = 0.032/0.059/0.083/0.018 ms
Quindi l’inter-VXLAN routing funziona correttamente. Questo grazie alle interfacce (virtuali) BDI configurate sui Leaf, e ai default-gateway configurati sugli Host.
La prova che ho eseguito utilizza come Leaf dei router virtuali CSR1kv, che utilizzano l’IOS XE. Spero presto di poter eseguire lo stesso test utilizzando l’NX-OS (l’IOS dei Nexus ! Ricordo che la linea Nexus costituisce la punta di diamante degli switch multilayer Cisco per i Data center). Purtroppo vi anticipo che i comandi non sono proprio identici, alcuni sono uguali, altri no. E questo, mi dispiace dirlo, è un vezzo molto negativo che ha Cisco, che cambia sovente la struttura dei comandi in funzione del tipo di IOS (provato mai a configurare un protocollo di routing nell’IOS XR ? Stile di configurazione diverso (molto JUNOS-like !) rispetto all’IOS o IOS XE o NX-OS). Il JUNOS da questo punto di vista è molto più intelligente, i comandi sono sempre gli stessi, indipendenti dalla particolare piattaforma. (NOTA: questa mia considerazione personale non deve essere interpretata come un possibile endorsement di uno o dell'altro costruttore)
VXLAN FASE 2 (UNICAST-ONLY VXLAN)
Come detto più volte, essere legati all’utilizzo del routing multicast per il MAC learning è una forte limitazione pratica. La fase successiva nello sviluppo delle VXLAN è stata l’eliminazione del routing multicast e quindi sviluppare una metodologia di MAC learning basata sull’utilizzo del solo routing unicast (per questo spesso chiamata Unicast-only VXLAN).
L’idea in realtà non è nuova. Se tornate indietro con i miei post, parlando del modello EVPN (e anche del modello NG-MVPN), ho citato tra i possibili metodi utilizzabili sul piano dati, di Ingress Replication (talvolta indicato anche come Head-end Replication). Bene, questo metodo, se calato nella realtà delle VXLAN, non è altro che la possibilità di inviare il traffico BUM in modo molto “grezzo” ed inefficiente, replicando in modalità unicast i pacchetti VXLAN, verso tutte le VTEP dove sono attestati Host dello stesso segmento VXLAN.
Il problema a questo punto è quello di restringere l’ambito di destinazione dei pacchetti VXLAN. In teoria è possibile replicare i pacchetti VXLAN verso tutte le VTEP conosciute, anche quelle dove non sono attestati Host dello stesso segmento VXLAN. Ma questo porrebbe un serio problema di scalabilità. Nasce così un secondo problema: come fa una VTEP a conoscere gli indirizzi IP delle altre VTEP dove sono attestati Host dello stesso segmento VXLAN ? In altre parole, come fa uno switch a creare una tabella (tabella VXLAN VTEP) dove a ciascun VNI corrispondono gli indirizzi di tutte le interfacce VTEP dove sono attestati Host dello stesso segmento VXLAN identificato dallo stesso VNI ?
Non esiste a mia conoscenza alcun documento che propone un metodo standard per creare questa tabella VXLAN VTEP. Sempre a mia conoscenza, l’utilizzo dell’Ingress Replication per veicolare il traffico VXLAN di tipo BUM è stato implementato solo nello switch virtuale Cisco Nexus 1000v. Juniper utilizza l’Ingress Replication nel modello EVPN, ma questa, benché simile, è un’altra storia.
Giusto per vedere come funziona questo metodo, vi illustro brevemente la sua implementazione nel Cisco Nexus 1000v. A grandi linee ecco cosa accade:
Infine, per completare la prova, ho eseguito un ping da H1, che appartiene al segmento VXLAN 5010, verso l’Host H5, che appartiene invece al segmento VXLAN 5030:
tt@H1:~$ ping 10.1.30.5
PING (10.1.30.5) 56(84) bytes of data.
64 bytes from localhost (10.1.30.5): icmp_seq=1 ttl=64 time=0.032 ms
64 bytes from localhost (10.1.30.5): icmp_seq=2 ttl=64 time=0.072 ms
64 bytes from localhost (10.1.30.5): icmp_seq=3 ttl=64 time=0.054 ms
64 bytes from localhost (10.1.30.5): icmp_seq=4 ttl=64 time=0.056 ms
64 bytes from localhost (10.1.30.5): icmp_seq=5 ttl=64 time=0.083 ms
^C
--- localhost ping statistics ---
5 packets transmitted, 5 received, 0% packet loss, time 3999ms
rtt min/avg/max/mdev = 0.032/0.059/0.083/0.018 ms
Quindi l’inter-VXLAN routing funziona correttamente. Questo grazie alle interfacce (virtuali) BDI configurate sui Leaf, e ai default-gateway configurati sugli Host.
La prova che ho eseguito utilizza come Leaf dei router virtuali CSR1kv, che utilizzano l’IOS XE. Spero presto di poter eseguire lo stesso test utilizzando l’NX-OS (l’IOS dei Nexus ! Ricordo che la linea Nexus costituisce la punta di diamante degli switch multilayer Cisco per i Data center). Purtroppo vi anticipo che i comandi non sono proprio identici, alcuni sono uguali, altri no. E questo, mi dispiace dirlo, è un vezzo molto negativo che ha Cisco, che cambia sovente la struttura dei comandi in funzione del tipo di IOS (provato mai a configurare un protocollo di routing nell’IOS XR ? Stile di configurazione diverso (molto JUNOS-like !) rispetto all’IOS o IOS XE o NX-OS). Il JUNOS da questo punto di vista è molto più intelligente, i comandi sono sempre gli stessi, indipendenti dalla particolare piattaforma. (NOTA: questa mia considerazione personale non deve essere interpretata come un possibile endorsement di uno o dell'altro costruttore)
VXLAN FASE 2 (UNICAST-ONLY VXLAN)
Come detto più volte, essere legati all’utilizzo del routing multicast per il MAC learning è una forte limitazione pratica. La fase successiva nello sviluppo delle VXLAN è stata l’eliminazione del routing multicast e quindi sviluppare una metodologia di MAC learning basata sull’utilizzo del solo routing unicast (per questo spesso chiamata Unicast-only VXLAN).
L’idea in realtà non è nuova. Se tornate indietro con i miei post, parlando del modello EVPN (e anche del modello NG-MVPN), ho citato tra i possibili metodi utilizzabili sul piano dati, di Ingress Replication (talvolta indicato anche come Head-end Replication). Bene, questo metodo, se calato nella realtà delle VXLAN, non è altro che la possibilità di inviare il traffico BUM in modo molto “grezzo” ed inefficiente, replicando in modalità unicast i pacchetti VXLAN, verso tutte le VTEP dove sono attestati Host dello stesso segmento VXLAN.
Il problema a questo punto è quello di restringere l’ambito di destinazione dei pacchetti VXLAN. In teoria è possibile replicare i pacchetti VXLAN verso tutte le VTEP conosciute, anche quelle dove non sono attestati Host dello stesso segmento VXLAN. Ma questo porrebbe un serio problema di scalabilità. Nasce così un secondo problema: come fa una VTEP a conoscere gli indirizzi IP delle altre VTEP dove sono attestati Host dello stesso segmento VXLAN ? In altre parole, come fa uno switch a creare una tabella (tabella VXLAN VTEP) dove a ciascun VNI corrispondono gli indirizzi di tutte le interfacce VTEP dove sono attestati Host dello stesso segmento VXLAN identificato dallo stesso VNI ?
Non esiste a mia conoscenza alcun documento che propone un metodo standard per creare questa tabella VXLAN VTEP. Sempre a mia conoscenza, l’utilizzo dell’Ingress Replication per veicolare il traffico VXLAN di tipo BUM è stato implementato solo nello switch virtuale Cisco Nexus 1000v. Juniper utilizza l’Ingress Replication nel modello EVPN, ma questa, benché simile, è un’altra storia.
Giusto per vedere come funziona questo metodo, vi illustro brevemente la sua implementazione nel Cisco Nexus 1000v. A grandi linee ecco cosa accade:
- Quando viene istanziata una nuova macchina virtuale (VM, Virtual Machine), l’Hypervisor notifica la sua presenza al VEM (Virtual Ethernet Module, il modulo software che emula le funzioni del piano dati: forwarding, QoS, sicurezza, ecc.; facendo un confronto con switch fisici multi-chassis, il VEM è l’analogo di una linecard).
- Il modulo VEM aggiunge l’indirizzo MAC della VM locale alla tabella VTEP.
- Il modulo VSM (Virtual Supervisor Module, il modulo software che controlla più VEM come fossero un solo switch logico modulare; facendo un confronto con switch fisici multi-chassis, il VSM è l’analogo della scheda, o delle schede supervisor) aggrega continuamente queste informazioni locali e quindi le invia a tutti i moduli VEM degli altri switch virtuali. Come le invia è un mistero, probabilmente con qualche protocollo proprietario. Dalla documentazione Cisco non si evince molto.
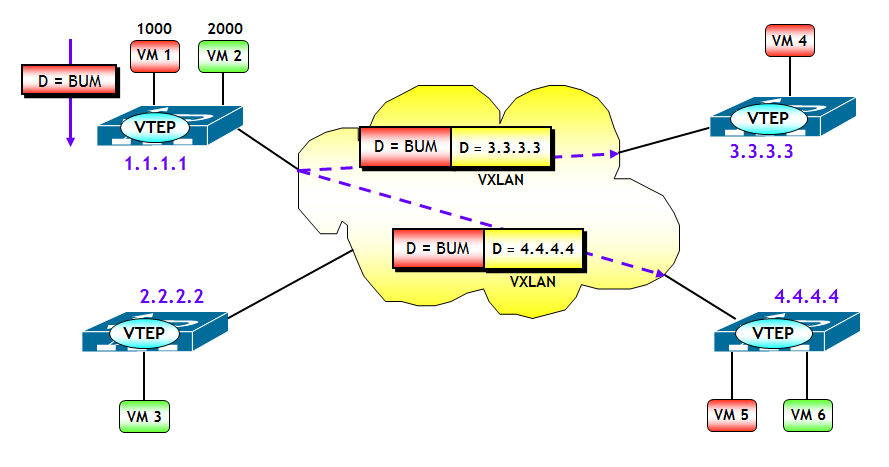
Alla fine di questo processo, ciascun modulo VEM si è costruito le tabelle VXLAN VTEP. Il tutto è riassunto nella figura seguente.
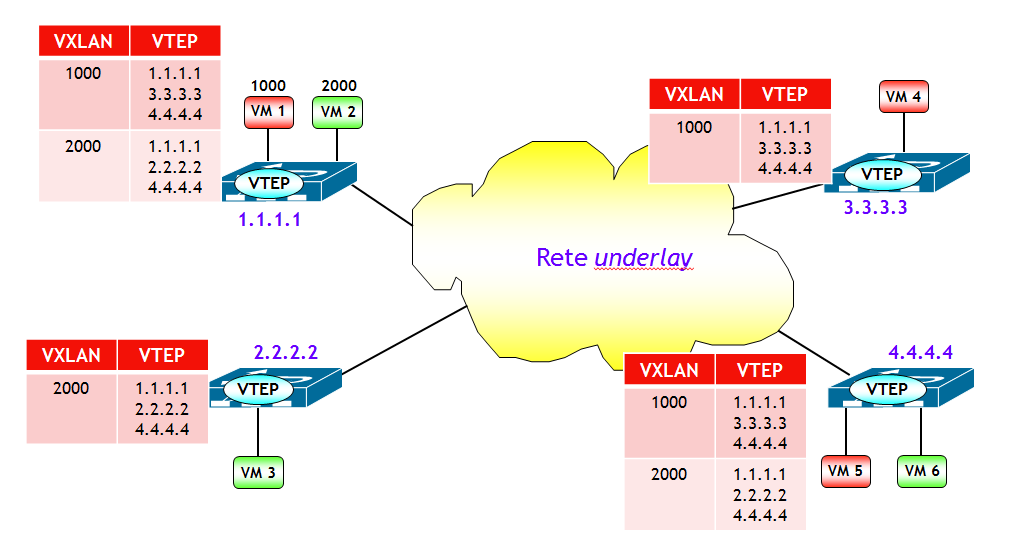
Ora il gioco è semplice. Quando ad esempio il switch virtuale riceve una trama Ethernet di una VXLAN con un determinato VNI, con MAC destinazione BUM, il VEM consulta la tabella VXLAN VTEP, dalla quale apprende tutti gli indirizzi IP (unicast) delle VTEP che hanno Host del segmento VXLAN con lo stesso VNI. Ad esempio, con riferimento alla figura seguente, quando la VM 1, appartenente al segmento VXLAN 1000, genera una trama Ethernet con MAC destinazione BUM, il modulo VEM del switch virtuale consulta la tabella VXLAN VTEP in corrispondenza del VNI 1000, da cui evince gli indirizzi delle VTEP destinazione. Il modulo VEM incapsula quindi la trama Ethernet originale in due pacchetti VXLAN unicast, che vengono inviati separatamente alle VTEP 3.3.3.3 e 4.4.4.4 .
Il metodo Unicast-only VXLAN, a parte il citato caso del Cisco Nexus 1000v (e forse qualche altro che non conosco), non ha riscosso grande successo. In realtà, a ben vedere, è vero che elimina la necessità di un protocollo di routing multicast nella rete underlay, a prezzo però di un notevole aumento del traffico sulla rete, con conseguente spreco di banda. E questo, in un ambiente di tipo cloud dove i tenant (e quindi i segmenti VXLAN) possono tranquillamente essere centinaia di migliaia, potrebbe avere seri problemi di scalabilità. La soluzione migliore sarebbe innanzitutto ridurre il traffico BUM (ad esempio, tramite ARP/ND Proxy, scarto e non flooding dei pacchetti con destinazione sconosciuta). E quel poco che rimane magari inviarlo in unicast con l’Ingress Replication. E qui entra in gioco il modello EVPN !
VXLAN FASE 3: PIANO DI CONTROLLO EVPN
Prima di vedere il funzionamento di VXLAN con piano di controllo EVPN, è opportuno mettere in evidenza quali sono i vantaggi:
Ora il gioco è semplice. Quando ad esempio il switch virtuale riceve una trama Ethernet di una VXLAN con un determinato VNI, con MAC destinazione BUM, il VEM consulta la tabella VXLAN VTEP, dalla quale apprende tutti gli indirizzi IP (unicast) delle VTEP che hanno Host del segmento VXLAN con lo stesso VNI. Ad esempio, con riferimento alla figura seguente, quando la VM 1, appartenente al segmento VXLAN 1000, genera una trama Ethernet con MAC destinazione BUM, il modulo VEM del switch virtuale consulta la tabella VXLAN VTEP in corrispondenza del VNI 1000, da cui evince gli indirizzi delle VTEP destinazione. Il modulo VEM incapsula quindi la trama Ethernet originale in due pacchetti VXLAN unicast, che vengono inviati separatamente alle VTEP 3.3.3.3 e 4.4.4.4 .
Il metodo Unicast-only VXLAN, a parte il citato caso del Cisco Nexus 1000v (e forse qualche altro che non conosco), non ha riscosso grande successo. In realtà, a ben vedere, è vero che elimina la necessità di un protocollo di routing multicast nella rete underlay, a prezzo però di un notevole aumento del traffico sulla rete, con conseguente spreco di banda. E questo, in un ambiente di tipo cloud dove i tenant (e quindi i segmenti VXLAN) possono tranquillamente essere centinaia di migliaia, potrebbe avere seri problemi di scalabilità. La soluzione migliore sarebbe innanzitutto ridurre il traffico BUM (ad esempio, tramite ARP/ND Proxy, scarto e non flooding dei pacchetti con destinazione sconosciuta). E quel poco che rimane magari inviarlo in unicast con l’Ingress Replication. E qui entra in gioco il modello EVPN !
VXLAN FASE 3: PIANO DI CONTROLLO EVPN
Prima di vedere il funzionamento di VXLAN con piano di controllo EVPN, è opportuno mettere in evidenza quali sono i vantaggi:
- Forte riduzione del traffico BUM, grazie a funzionalità come Proxy ARP/ND e alla possibilità di evitare il flooding delle trame Ethernet con MAC destinazione non noto.
- Gestione molto efficiente della mobilità degli Host.
- Meccanismo di autodiscovery basato sul BGP piuttosto che sul routing multicast.
- Integrazione L2/L3 nativa e possibilità di utilizzare la funzionalità di Distributed IP Anycast Gateway.
- Possibilità di utilizzare tutte le funzionalità avanzate del modello EVPN (accessi multi-homing di tipo active-active, aliasing, fast convergence, split horizon, ecc.).
- Possibilità di creare topologie logiche arbitrarie (es. magliatura completa, Hub-and-Spoke, Extranet, ecc.) grazie a un utilizzo oculato dei Route Target.
Ciò detto, l’integrazione VXLAN/EVPN è trattata in un documento IETF ancora allo stato draft “draft-ietf-bess-evpn-overlay”. In realtà il documento è un po’ più generale, poiché applicabile non solo a un incapsulamento di tipo VXLAN, ma anche NVGRE. VXLAN sta però diventando lo standard adottato da tutti i costruttori di apparati hardware e software, per cui non farò riferimento nel seguito a NVGRE.
L’idea principale dietro l’utilizzo di EVPN come piano di controllo per le VXLAN è quella che ormai ho ripetuto più volte: la netta separazione tra piano di controllo e piano dati insita nel modello EVPN. Come detto nel post precedente, questo fa si che EVPN, benché sviluppato inizialmente con un piano dati puramente MPLS, possa essere utilizzato anche con altri tipi di piano dati, tra cui VXLAN, che come noto non utilizza MPLS per il trasporto, ma una comunissima rete IP.
Il ruolo dei PE è giocato dai dispositivi che implementano la funzione VTEP (NOTA: nel draft IETF citato sopra, il punto dove è implementata la funzione VTEP viene genericamente chiamato NVE, Network Virtualization Endpoint. Per semplicità continuerò a utilizzare il termine VTEP, piuttosto che NVE). Questi dispositivi possono essere o del semplice (si fa per dire) software implementato in un Hypervisor di un server (es. Cisco Nexus 1000v, Juniper Contrail, Nuage VSP), oppure dispositivi hardware, tipicamente switch multilayer utilizzati nei Data Center come ToR (es. Cisco Nexus 9k, Juniper QFX5100). In funzione del tipo di dispositivo dove risiede la funzione VTEP, vengono utilizzate o tutte o parte delle funzionalità tipiche di EVPN. Ma prima di vedere questo aspetto, voglio illustrare con un semplice esempio, il principio di base dell’integrazione VXLAN/EVPN.
Con riferimento alla figura seguente, il dispositivo dove risiede la funziona VTEP-3 apprende attraverso un classico MAC learning sul piano dati, l’indirizzo MAC-3 dell’Host H3, che appartiene alla VLAN V3, ed eventualmente anche l’indirizzo IP-3. Sulla VTEP-3 è presente una mappa VLAN-->VNI che fa corrispondere alla VLAN V3 il VNI VNI-3. Ora, utilizzando la sessione MP-BGP verso il Route Reflector RR, viene inviato a RR un annuncio BGP EVPN che contiene come informazioni: MAC-3, IP-3, VNI-3 e nel campo Next-Hop, l’indirizzo IP della VTEP-3. L’annuncio viene propagato dal RR ai vari RR-Client (ossia, gli altri dispositivi dove sono attive altre VTEP), i quali utilizzano le informazioni contenute nell’annuncio per popolare le MAC-VRF associate alla VXLAN VNI-3 (NOTA: come noto in questo processo giocano un ruolo chiave i Route Target, che per brevità non ho illustrato nella figura).
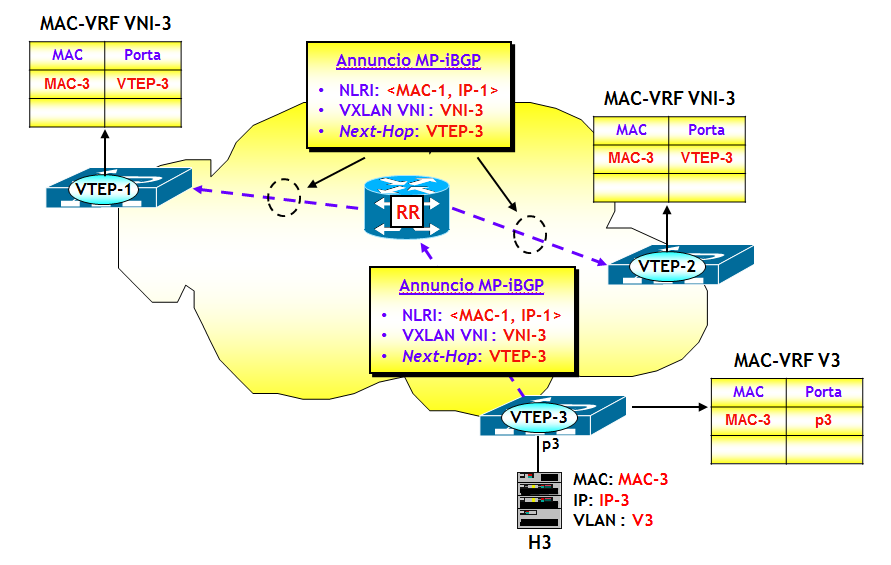
A questo punto, il trasporto del traffico VXLAN da un qualsiasi Host del segmento VXLAN VNI-3 verso H3, segue le regole già viste per il trasporto del traffico VXLAN. Le trame Ethernet originali vengono incapsulate in pacchetti VXLAN e quindi dirette dalla rete IP underlay verso la VTEP-3. Quest’ultima decapsula i pacchetti VXLAN e quindi invia le trame originali verso H3.
All’apparenza tutto semplice, in realtà è così. Però come sempre ci sono dei dettagli da chiarire.
VXLAN + EVPN: ALCUNI DETTAGLI
Le VXLAN utilizzano il valore di VNI per segmentare il traffico dei vari tenant. Il modello EVPN d’altra parte, per risolvere lo stesso problema utilizza il concetto di EVI (Ethernet Virtual Instance). Quando si utilizza il piano di controllo EVPN per le VXLAN, nasce quindi un problema, non presente quando si utilizza il routing multicast o l’Unicast-only VXLAN: quale relazione esiste tra i due metodi di segmentazione ? In realtà un problema analogo lo abbiamo già trattato nel modello EVPN, dove anche lì esistono due metodi di segmentazione, uno basato sulle VLAN del tenant, uno basato sul concetto di EVI.
Sono possibili due opzioni, ciascuna con i suoi pro e contro.
L’idea principale dietro l’utilizzo di EVPN come piano di controllo per le VXLAN è quella che ormai ho ripetuto più volte: la netta separazione tra piano di controllo e piano dati insita nel modello EVPN. Come detto nel post precedente, questo fa si che EVPN, benché sviluppato inizialmente con un piano dati puramente MPLS, possa essere utilizzato anche con altri tipi di piano dati, tra cui VXLAN, che come noto non utilizza MPLS per il trasporto, ma una comunissima rete IP.
Il ruolo dei PE è giocato dai dispositivi che implementano la funzione VTEP (NOTA: nel draft IETF citato sopra, il punto dove è implementata la funzione VTEP viene genericamente chiamato NVE, Network Virtualization Endpoint. Per semplicità continuerò a utilizzare il termine VTEP, piuttosto che NVE). Questi dispositivi possono essere o del semplice (si fa per dire) software implementato in un Hypervisor di un server (es. Cisco Nexus 1000v, Juniper Contrail, Nuage VSP), oppure dispositivi hardware, tipicamente switch multilayer utilizzati nei Data Center come ToR (es. Cisco Nexus 9k, Juniper QFX5100). In funzione del tipo di dispositivo dove risiede la funzione VTEP, vengono utilizzate o tutte o parte delle funzionalità tipiche di EVPN. Ma prima di vedere questo aspetto, voglio illustrare con un semplice esempio, il principio di base dell’integrazione VXLAN/EVPN.
Con riferimento alla figura seguente, il dispositivo dove risiede la funziona VTEP-3 apprende attraverso un classico MAC learning sul piano dati, l’indirizzo MAC-3 dell’Host H3, che appartiene alla VLAN V3, ed eventualmente anche l’indirizzo IP-3. Sulla VTEP-3 è presente una mappa VLAN-->VNI che fa corrispondere alla VLAN V3 il VNI VNI-3. Ora, utilizzando la sessione MP-BGP verso il Route Reflector RR, viene inviato a RR un annuncio BGP EVPN che contiene come informazioni: MAC-3, IP-3, VNI-3 e nel campo Next-Hop, l’indirizzo IP della VTEP-3. L’annuncio viene propagato dal RR ai vari RR-Client (ossia, gli altri dispositivi dove sono attive altre VTEP), i quali utilizzano le informazioni contenute nell’annuncio per popolare le MAC-VRF associate alla VXLAN VNI-3 (NOTA: come noto in questo processo giocano un ruolo chiave i Route Target, che per brevità non ho illustrato nella figura).
A questo punto, il trasporto del traffico VXLAN da un qualsiasi Host del segmento VXLAN VNI-3 verso H3, segue le regole già viste per il trasporto del traffico VXLAN. Le trame Ethernet originali vengono incapsulate in pacchetti VXLAN e quindi dirette dalla rete IP underlay verso la VTEP-3. Quest’ultima decapsula i pacchetti VXLAN e quindi invia le trame originali verso H3.
All’apparenza tutto semplice, in realtà è così. Però come sempre ci sono dei dettagli da chiarire.
VXLAN + EVPN: ALCUNI DETTAGLI
Le VXLAN utilizzano il valore di VNI per segmentare il traffico dei vari tenant. Il modello EVPN d’altra parte, per risolvere lo stesso problema utilizza il concetto di EVI (Ethernet Virtual Instance). Quando si utilizza il piano di controllo EVPN per le VXLAN, nasce quindi un problema, non presente quando si utilizza il routing multicast o l’Unicast-only VXLAN: quale relazione esiste tra i due metodi di segmentazione ? In realtà un problema analogo lo abbiamo già trattato nel modello EVPN, dove anche lì esistono due metodi di segmentazione, uno basato sulle VLAN del tenant, uno basato sul concetto di EVI.
Sono possibili due opzioni, ciascuna con i suoi pro e contro.
- Opzione 1: singolo segmento VXLAN per EVI. Con questa opzione, ciascun segmento VXLAN, identificato da un VNI, viene mappato a una EVI. Questo corrisponde al servizio VLAN-based del modello EVPN, descritto in questo post. Il vantaggio di questa opzione è la possibilità di utilizzare il classico meccanismo dei Route Target, sia per limitare la quantità di messaggi BGP UPDATE (utilizzando il trucchetto del BGP Constrained Route Distribution; se non lo conoscete nessuna preoccupazione, ho in canna un breve post per descriverlo), che l’insieme delle route importate in una EVI (infatti vengono importate solo le route che hanno il VNI giusto). Lo svantaggio di questa opzione è l’overhead di configurazione per il corretto provisioning di RT e RD, analogamente a quanto avviene per le L3VPN (a meno che non esista un metodo di determinazione automatica di RD e RT !). Si noti che con questa opzione, la tabella MAC-VRF è identificata sul piano di controllo dal valore di RT e sul piano dati dal valore del VNI (NOTA: per fare un paragone, nel modello EVPN classico la tabella MAC-VRF è identificata sul piano di controllo sempre dal valore di RT, mentre sul piano dati dal valore della service label MPLS).
- Opzione 2: più segmenti VXLAN per EVI. Con questa opzione, più segmenti VXLAN, ciascuno identificato da un VNI, vengono mappati a una singola EVI. Questo corrisponde al servizio VLAN-aware Bundle del modello EVPN, descritto in questo post. Il vantaggio di questa opzione è che l’overhead di configurazione è ridotto (meno RD e RT da gestire, anche se questo diventa un non-problema in presenza di un metodo di determinazione automatica di RD e RT). Lo svantaggio per contro è che una EVI potrebbe importare delle route inutilmente, quando non ha Host di un particolare segmento VXLAN parte del bundle.Si noti che con questa opzione, la tabella MAC-VRF è identificata sul piano di controllo dal valore di RT, e la specifica tabella di bridging all’interno della MAC-VRF dalla coppia <RT, Ethernet Tag ID>. Sul piano dati, la specifica tabella di bridging all’interno della MAC-VRF è identificata dal solo valore del VNI (che è più che sufficiente essendo i possibili VNI più di 16 milioni).
Il draft IETF citato sopra definisce una modalità standard per la determinazione automatica dei RT. Se siete curiosi potete guardarla sul draft, ma non è un aspetto importante.
A questo punto dobbiamo affrontare un altro problema. Nel modello EVPN classico, basato sul piano dati MPLS, il PE di uscita sceglie la tabella MAC-VRF da consultare per l’inoltro del traffico verso i CE, sulla base della service label MPLS (o anche l’aliasing label, nel caso di aliasing). Se ci pensate un attimo questo è analogo a quanto avviene nelle VXLAN, dove per inoltrare correttamente il traffico a destinazione, la funzione VTEP (equivalente del PE !) utilizza il VNI. Ma con una differenza fondamentale, mentre le service label MPLS sono locali al PE, ossia hanno validità solo per il PE che le sceglie (e annuncia), i valori di VNI hanno validità globale (NOTA: se ci fate caso questa è in ultima analisi la differenza tra VLAN e L3VPN; entrambi sono metodi di virtualizzazione, solo che il primo utilizza per il forwarding gli indirizzi MAC e i VLAN-ID (che sono globali, ma potrebbero essere “localizzati” utilizzando strumenti di tipo VLAN-ID rewrite), mentre il secondo utilizza indirizzi IP e service label MPLS (che sono locali ai PE)).
Vista l’analogia tra service label MPLS e VNI, quando il modello EVPN viene utilizzato come piano di controllo per le VXLAN, il valore di VNI viene annunciato utilizzando i campi riservati alle etichette MPLS dei vari tipi di NLRI BGP EVPN (Ethernet Auto-discovery Route (per EVI), MAC/IP Advertisement Route e Inclusive Multicast Route). Tra l’altro, così facendo è possibile rendere i VNI locali, se utile, e non necessariamente globali, dando maggiore flessibilità alla costruzione dei segmenti VXLAN (in particolare quando gli Host dello stesso segmento VXLAN si trovano su diversi Data Center).
Inoltre, per indicare il tipo di incapsulamento utilizzato sul piano dati (VXLAN, NVGRE, MPLS, e possibilmente altro), a tutti gli annunci BGP EVPN, di qualsiasi tipo, viene aggiunta la BGP Encapsulation Extended Community definita nella RFC 5512. Il tipo di incapsulamento è identificato da un valore numerico standard (es. VXLAN = 8, NVGRE = 9, MPLS = 10, ecc.).
Infine, aspetto molto importante, il campo Next-Hop dell’attributo MP_REACH_NLRI degli annunci contiene l’indirizzo IP della VTEP da dove parte l’annuncio.
Solo per vostra curiosità, vi riporto il risultato di un comando “show” ottenuto su un switch multilayer Cisco Nexus della serie 9000, che mostra il dettaglio di un annuncio BGP EVPN di tipo MAC/IP Advertisement,con alcuni commenti (NOTA: nella visualizzazione ho omesso alcune parti che riguardano l’inter-VXLAN routing, che illustrerò in un prossimo post).

Come ho già citato, in funzione del tipo di dispositivo dove risiede la funzione VTEP, vengono utilizzate o tutte o parte delle funzionalità tipiche di EVPN. In particolare i casi da valutare sono due:
A questo punto dobbiamo affrontare un altro problema. Nel modello EVPN classico, basato sul piano dati MPLS, il PE di uscita sceglie la tabella MAC-VRF da consultare per l’inoltro del traffico verso i CE, sulla base della service label MPLS (o anche l’aliasing label, nel caso di aliasing). Se ci pensate un attimo questo è analogo a quanto avviene nelle VXLAN, dove per inoltrare correttamente il traffico a destinazione, la funzione VTEP (equivalente del PE !) utilizza il VNI. Ma con una differenza fondamentale, mentre le service label MPLS sono locali al PE, ossia hanno validità solo per il PE che le sceglie (e annuncia), i valori di VNI hanno validità globale (NOTA: se ci fate caso questa è in ultima analisi la differenza tra VLAN e L3VPN; entrambi sono metodi di virtualizzazione, solo che il primo utilizza per il forwarding gli indirizzi MAC e i VLAN-ID (che sono globali, ma potrebbero essere “localizzati” utilizzando strumenti di tipo VLAN-ID rewrite), mentre il secondo utilizza indirizzi IP e service label MPLS (che sono locali ai PE)).
Vista l’analogia tra service label MPLS e VNI, quando il modello EVPN viene utilizzato come piano di controllo per le VXLAN, il valore di VNI viene annunciato utilizzando i campi riservati alle etichette MPLS dei vari tipi di NLRI BGP EVPN (Ethernet Auto-discovery Route (per EVI), MAC/IP Advertisement Route e Inclusive Multicast Route). Tra l’altro, così facendo è possibile rendere i VNI locali, se utile, e non necessariamente globali, dando maggiore flessibilità alla costruzione dei segmenti VXLAN (in particolare quando gli Host dello stesso segmento VXLAN si trovano su diversi Data Center).
Inoltre, per indicare il tipo di incapsulamento utilizzato sul piano dati (VXLAN, NVGRE, MPLS, e possibilmente altro), a tutti gli annunci BGP EVPN, di qualsiasi tipo, viene aggiunta la BGP Encapsulation Extended Community definita nella RFC 5512. Il tipo di incapsulamento è identificato da un valore numerico standard (es. VXLAN = 8, NVGRE = 9, MPLS = 10, ecc.).
Infine, aspetto molto importante, il campo Next-Hop dell’attributo MP_REACH_NLRI degli annunci contiene l’indirizzo IP della VTEP da dove parte l’annuncio.
Solo per vostra curiosità, vi riporto il risultato di un comando “show” ottenuto su un switch multilayer Cisco Nexus della serie 9000, che mostra il dettaglio di un annuncio BGP EVPN di tipo MAC/IP Advertisement,con alcuni commenti (NOTA: nella visualizzazione ho omesso alcune parti che riguardano l’inter-VXLAN routing, che illustrerò in un prossimo post).
Come ho già citato, in funzione del tipo di dispositivo dove risiede la funzione VTEP, vengono utilizzate o tutte o parte delle funzionalità tipiche di EVPN. In particolare i casi da valutare sono due:
- La funzione VTEP è svolta via software e localizzata in un Hypervisor (es. KVM, Hyper-V, VMware NSX, ecc.).
- La funzione VTEP è realizzata in hardware e localizzata in un switch ToR.
ASPETTI OPERATIVI: VTEP IN UN HYPERVISOR
Quando, utilizzando la nomenclatura EVPN, PE e CE sono colocati sulla stessa macchina fisica, es. quando un PE, ossia la funzione VTEP, risiede in un server e i CE sono delle VM (Virtual Machine), i collegamenti PE-CE sono virtuali e tipicamente non sono multi-homed. Il caso pratico più comune di questo scenario si ha quando la funzione VTEP risiede in un Hypervisor.
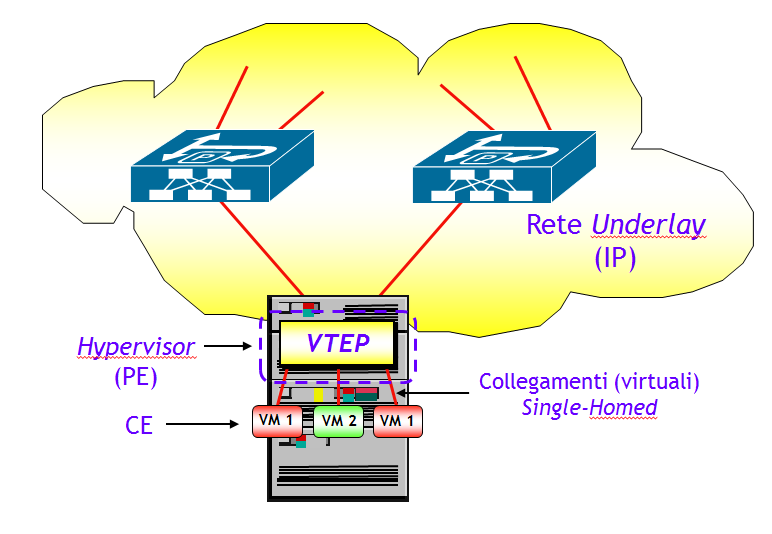
In questo scenario, tutte le funzionalità EVPN legate al multi-homing (es. split horizon, aliasing, fast convergence, elezione del DF) non sono necessarie. Questo riduce quindi l’insieme dei tipi di annunci BGP EVPN e delle nuove Extended Community, necessari al funzionamento. In particolare, sono utilizzate solo gli NLRI di tipo 2 (MAC/IP Advertisement Route) e tipo 3 (Inclusive Multicast Route), e le Extended Community MAC Mobility e Default Gateway. Attenzione però, per fare in modo che i PE che risiedono in Hypervisor possano interagire con PE che hanno CE multi-homed, questi devono essere comunque in grado di trattare tutto l’insieme degli annunci BGP EVPN e tutte le Extended Community.
In questo scenario le procedure EVPN necessarie si riducono a:
- MAC learning locale degli indirizzi MAC delle VM.
- Annuncio degli indirizzi MAC delle VM attraverso MAC/IP Advertisement Route.
- MAC learning remoto degli indirizzi MAC.
- Scoperta delle altre VTEP e costruzione del piano dati per il trasporto del traffico BUM, attraverso Inclusive Multicast Route.
- Gestione della mobilità delle VM (MAC mobility).
Lo scenario di VTEP che risiedono in un Hypervisor richiede quindi una versione semplificata delle funzionalità EVPN. Vorrei farvi notare infine, che in questo scenario, i switch ToR dove sono connessi i server (tipicamente con collegamenti multi-homed), sono parte integrante della rete underlay, ossia possono essere considerati come dei semplici router della rete underlay.
ASPETTI OPERATIVI: VTEP IN UN SWITCH ToR
Lo scenario in cui invece la funzione VTEP risiede in un switch ToR è molto più complesso e richiede tutte le funzionalità avanzate del modello EVPN. Questo perché i server, che in questo scenario sono i CE, hanno normalmente collegamenti dual-homed verso due switch ToR.
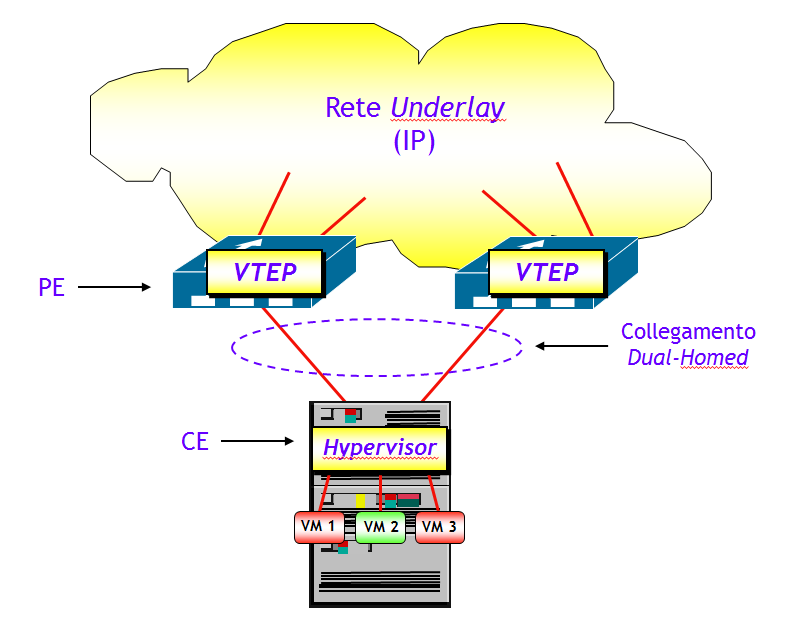
In questo scenario, sono necessarie tutte le funzionalità EVPN legate al multi-homing, e quindi tutto l’armamentario degli annunci BGP EVPN e le nuove Extended Community. Però, il lettore attento avrà notato che bisogna apportare alcune piccole modifiche al funzionamento di EVPN. Infatti, tra le varie funzionalità di gestione dei collegamenti multi-homed nel modello EVPN, ve ne sono due che utilizzano delle etichette MPLS: lo split horizon e l’aliasing, che utilizzano rispettivamente la split horizon label (annunciata attraverso la ESI label Extended Community inserita negli Ethernet AD per ES) e l’aliasing label (inserita nel campo MPLS Label degli annunci Ethernet AD per EVI). Ora, quando si utilizza come piano dati VXLAN, la rete underlay è una pura e semplice rete IP, che quindi non è in grado di gestire etichette MPLS.
La soluzione al problema è però abbastanza semplice. Ad esempio, per lo split horizon è sufficiente utilizzare sui PE che ricevono traffico BUM da un altro PE, la seguente regola (un po’ più laboriosa):
ASPETTI OPERATIVI: VTEP IN UN SWITCH ToR
Lo scenario in cui invece la funzione VTEP risiede in un switch ToR è molto più complesso e richiede tutte le funzionalità avanzate del modello EVPN. Questo perché i server, che in questo scenario sono i CE, hanno normalmente collegamenti dual-homed verso due switch ToR.
In questo scenario, sono necessarie tutte le funzionalità EVPN legate al multi-homing, e quindi tutto l’armamentario degli annunci BGP EVPN e le nuove Extended Community. Però, il lettore attento avrà notato che bisogna apportare alcune piccole modifiche al funzionamento di EVPN. Infatti, tra le varie funzionalità di gestione dei collegamenti multi-homed nel modello EVPN, ve ne sono due che utilizzano delle etichette MPLS: lo split horizon e l’aliasing, che utilizzano rispettivamente la split horizon label (annunciata attraverso la ESI label Extended Community inserita negli Ethernet AD per ES) e l’aliasing label (inserita nel campo MPLS Label degli annunci Ethernet AD per EVI). Ora, quando si utilizza come piano dati VXLAN, la rete underlay è una pura e semplice rete IP, che quindi non è in grado di gestire etichette MPLS.
La soluzione al problema è però abbastanza semplice. Ad esempio, per lo split horizon è sufficiente utilizzare sui PE che ricevono traffico BUM da un altro PE, la seguente regola (un po’ più laboriosa):
- Determinare l’indirizzo IP sorgente della VTEP che ha inviato la trama BUM.
- Consultare la tabella degli annunci BGP EVPN di tipo 4 ricevuti da questo indirizzo IP.
- Se tra gli annunci di tipo 4 inviati dalla stessa VTEP del punto 1, ve ne è uno con ESI identico a quello configurato sul PE, allora la trama BUM viene scartata.
Per quanto riguarda l’aliasing, il funzionamento è analogo al caso delle etichette MPLS, con la differenza che il load balancing è basato sugli indirizzi IP delle VTEP destinazione appartenenti allo stesso segmento Ethernet, senza utilizzare etichette MPLS.
Bene, con questo ho concluso. In realtà manca di affrontare il problema dell’inter-VXLAN routing con le modalità simmetrica e asimmetrica, ma lascio questo argomento per un prossimo post.
CONCLUSIONI
In questo post ho mostrato l’evoluzione del piano di controllo delle VXLAN. Si è passati da una proposta iniziale di un non-piano di controllo (RFC 7348), dove il MAC learning avviene esclusivamente sul piano dati, utilizzando il routing multicast nella rete IP underlay, a una soluzione intermedia con un mezzo piano di controllo (quello che serve a creare le tabelle VXLAN VTEP) e che utilizza Ingress Replication per il traffico BUM (Unicast-only VXLAN), infine al più sofisticato ma molto più efficiente piano di controllo EVPN.
Quest’ultima soluzione è già implementata in apparati molto utilizzati nei Data Center, come ad esempio i più volte citati Cisco Nexus 9k e Juniper QFX5100.
Ricordo comunque che in tutte le varie soluzioni, il MAC learning locale rimane (mi chiedo, ma non sarebbe più semplice comunicare immediatamente con qualche diavoleria simil-annuncio di un protocollo di routing, quale è l’indirizzo MAC della VM alla sua accensione, senza attendere l’invio della prima trama Ethernet (un po’ come avveniva nel vecchio ES-IS ...) ? Sarebbe tutto più semplice e più veloce, e si potrebbe tranquillamente evitare il flooding delle trame con indirizzo MAC sconosciuto (e questo vi fa capire come all’origine di tutti i problemi delle reti switched Ethernet vi sia il concetto di flooding ! Se ci riflettete un attimo, tutti i problemi nascono da lì. Che poi in ultima analisi questa è la vera differenza tra il forwarding a Livello 2 e Livello 3 di trame/pacchetti con destinazione ignota: il Livello 2 fa flooding, il Livello 3 scarta)).
Ma questo pone un problema ben più complesso: ma se dotiamo il Livello 2 Ethernet di un piano di controllo, aggiungendo a EVPN anche un piano di controllo Host-Switch, che differenza (concettuale) ci sarebbe tra Livello 2 e Livello 3 ? Nessuna, e quindi uno dei due è ridondante e andrebbe eliminato. Quale ? Io non avrei dubbi ... (e pian piano ci si arriverà, tranquilli, è solo questione di tempo; intanto lo Spanning Tree è defunto (anche Radja Perlman, quella che lo inventato si è pentita !), il MAC learning rimane solo a livello locale ma prima o poi sparirà, e così via ...).
Il prossimo post: Dalle Reti di Clos ... alle Reti di Clos.
Bene, con questo ho concluso. In realtà manca di affrontare il problema dell’inter-VXLAN routing con le modalità simmetrica e asimmetrica, ma lascio questo argomento per un prossimo post.
CONCLUSIONI
In questo post ho mostrato l’evoluzione del piano di controllo delle VXLAN. Si è passati da una proposta iniziale di un non-piano di controllo (RFC 7348), dove il MAC learning avviene esclusivamente sul piano dati, utilizzando il routing multicast nella rete IP underlay, a una soluzione intermedia con un mezzo piano di controllo (quello che serve a creare le tabelle VXLAN VTEP) e che utilizza Ingress Replication per il traffico BUM (Unicast-only VXLAN), infine al più sofisticato ma molto più efficiente piano di controllo EVPN.
Quest’ultima soluzione è già implementata in apparati molto utilizzati nei Data Center, come ad esempio i più volte citati Cisco Nexus 9k e Juniper QFX5100.
Ricordo comunque che in tutte le varie soluzioni, il MAC learning locale rimane (mi chiedo, ma non sarebbe più semplice comunicare immediatamente con qualche diavoleria simil-annuncio di un protocollo di routing, quale è l’indirizzo MAC della VM alla sua accensione, senza attendere l’invio della prima trama Ethernet (un po’ come avveniva nel vecchio ES-IS ...) ? Sarebbe tutto più semplice e più veloce, e si potrebbe tranquillamente evitare il flooding delle trame con indirizzo MAC sconosciuto (e questo vi fa capire come all’origine di tutti i problemi delle reti switched Ethernet vi sia il concetto di flooding ! Se ci riflettete un attimo, tutti i problemi nascono da lì. Che poi in ultima analisi questa è la vera differenza tra il forwarding a Livello 2 e Livello 3 di trame/pacchetti con destinazione ignota: il Livello 2 fa flooding, il Livello 3 scarta)).
Ma questo pone un problema ben più complesso: ma se dotiamo il Livello 2 Ethernet di un piano di controllo, aggiungendo a EVPN anche un piano di controllo Host-Switch, che differenza (concettuale) ci sarebbe tra Livello 2 e Livello 3 ? Nessuna, e quindi uno dei due è ridondante e andrebbe eliminato. Quale ? Io non avrei dubbi ... (e pian piano ci si arriverà, tranquilli, è solo questione di tempo; intanto lo Spanning Tree è defunto (anche Radja Perlman, quella che lo inventato si è pentita !), il MAC learning rimane solo a livello locale ma prima o poi sparirà, e così via ...).
Il prossimo post: Dalle Reti di Clos ... alle Reti di Clos.
Pubblicato in
ReissBlog
Etichettato sotto
Giovedì, 07 Gennaio 2016 07:14
EVPN: L’EVOLUZIONE DEL SERVIZIO VPLS – PARTE III
Nei due post precedenti sul modello EVPN ho illustrato i concetti e le idee fondamentali, focalizzando l’attenzione soprattutto sulle problematiche legate alla gestione dei collegamenti multi-homed e alla connettività di Livello 2. Però, come ricorderete, nei messaggi UPDATE BGP EVPN contenenti NLRI di tipo MAC/IP Advertisement, vi è la possibilità (opzionale !) di annunciare uno o più indirizzi IPv4/v6 associati all’indirizzo MAC (NOTA: ricordo che nel caso vi siano due o più indirizzi IP associati all’indirizzo MAC, ad esempio negli Host dual stack IPv4/IPv6, sono necessari più messaggi BGP EVPN con NLRI di tipo MAC/IP Advertisement, uno per ciascun indirizzo IP).
Questo aspetto del modello EVPN consente ulteriori ottimizzazioni, e gioca un ruolo molto importante nell’inter-vlan routing. Questo post sarà proprio focalizzato sull’integrazione L2/L3 nel modello EVPN.
PROXY ARP/ND
Uno degli aspetti interessanti del modello EVPN è che consente di ridurre il traffico broadcast sulla rete, in particolare il traffico dei messaggi ARP. I router PE, grazie alla conoscenza degli indirizzi IP associati agli indirizzi MAC, possono infatti svolgere la funzione di Proxy ARP (o Proxy ND nel caso di indirizzi IPv6), ossia rispondere direttamente ai messaggi ARP Request (o Neighbor Solicitation nel caso di indirizzi IPv6). Per semplicità considererò da qui in avanti solo la funzione Proxy ARP, essendo la funzione Proxy ND concettualmente identica.
Per capire bene il (semplice) funzionamento, farò riferimento alla figura seguente, dove è illustrato l’annuncio di tipo MAC/IP Advertisement da parte di PE2-1, con il quale viene annunciata la coppia <MAC-2; IP-2>.
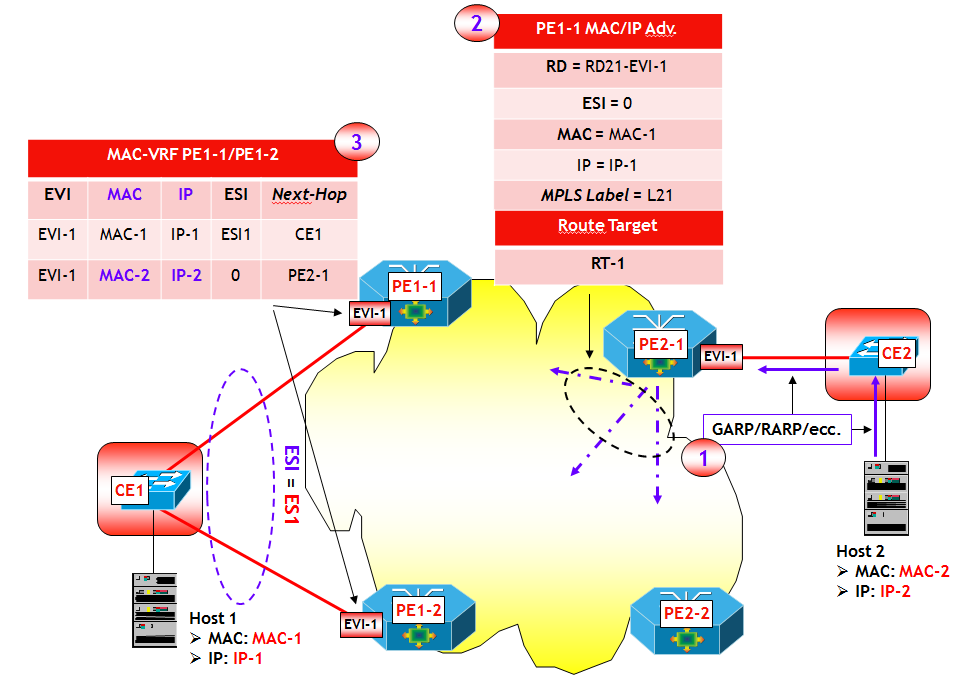
Come faccia un PE ad apprendere un indirizzo IP associato a un indirizzo MAC l’ho spiegato nel post precedente (es. ARP/DHCP snooping, Gratuitous ARP, Reverse ARP, ecc.). Questo, seppur importante, è comunque un aspetto secondario.
Giusto per ricapitolare, questa è la sequenza degli eventi:
Ritornando all’esempio, quando il messaggio ARP Request inviato dall’Host 1 arriva al router PE1-1, questo ha tutte le informazioni necessarie per rispondere, senza quindi il bisogno di propagare il messaggio ARP Request agli altri PE.
La figura seguente riassume la sequenza degli eventi.
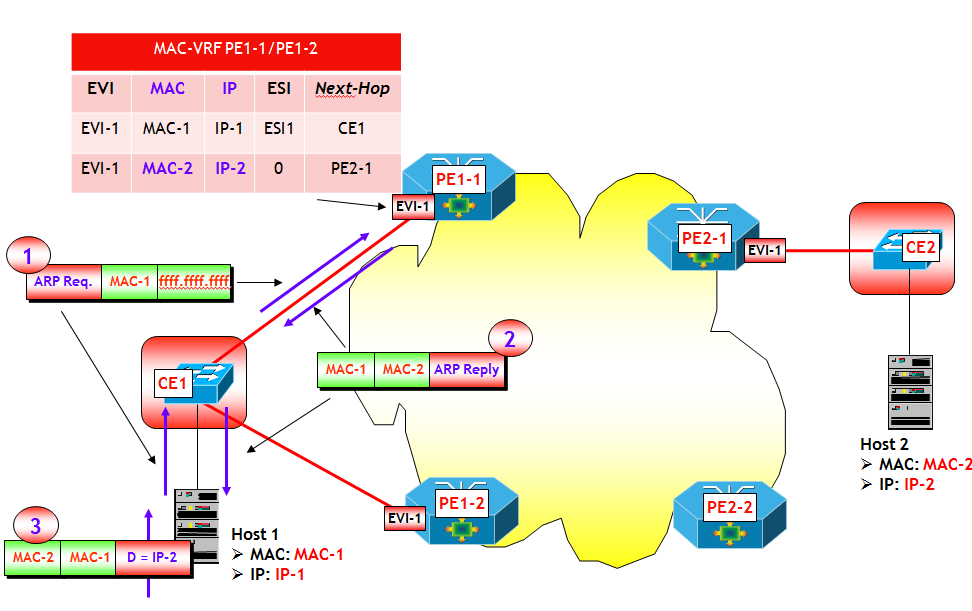
Per i più curiosi in cerca di approfondimenti sugli aspetti operativi del Proxy ARP/ND nel modello EVPN, consiglio la lettura di questo breve documento IETF .
INTEGRAZIONE DI ROUTING E BRIDGING
Il fatto che il modello EVPN preveda nei suoi annunci BGP EVPN la possibilità di annunciare la coppia <MAC; IP> di un Host, consente di integrare e ottimizzare le funzioni di routing e bridging. La funzione di bridging in realtà parte già ottimizzata da tutte le funzionalità già presenti nel modello EVPN. Per il traffico intra-VLAN (o anche, in modo equivalente, intra-subnet) quindi tutte le problematiche più importanti sono già risolte dal modello EVPN. Il problema è come rendere ottimale anche il trasporto del traffico inter-VLAN (inter-subnet).
Il modello EVPN affronta queste problematiche attraverso delle funzionalità che integrano il trasporto L2 (anche noto come bridging) e il trasporto L3 (anche noto come routing). L’insieme di queste funzionalità è noto come Integrated Routing and Bridging (IRB), ed è l’oggetto di un documento IETF ancora allo stato di draft: “Integrated Routing and Bridging in EVPN” (draft-ietf-bess-evpn-inter-subnet-forwarding-01; NOTA: bess non è il nome dell’autore del draft, ma un acronimo che sta per BGP Enabled ServiceS).
Le funzionalità IRB di EVPN sono utili anche perché consentono di integrare il modello EVPN con il classico modello L3VPN, e questo è molto utile per la fornitura di servizi cloud ai propri clienti. Per maggiore flessibilità e scalabilità, per ciascun cliente (tenant) è possibile definire più domini broadcast (o domini di bridging) all’interno di ciascuna EVI, e quindi associare una o più EVI a una singola istanza L3VPN (VRF).
Per il supporto di questo modello è necessario definire una interfaccia virtuale IRB, che faccia da “ponte” tra le funzioni di Livello 2 e Livello 3. Inoltre, ciascun dominio di bridging si mappa ad un’unica subnet IP nella VRF.
In generale, a ciascun tenant di un Data Center è assegnata una singola L3VPN VRF, ma possono essere associate più EVI e uno o più domini di bridging per ciascuna EVI. La figura seguente riporta un esempio di un tenant che ha 4 domini di bridging, uno, identificato dalla VLAN 10, associato all’istanza EVPN EVI-1 e tre, identificati dalle VLAN 21, 22, 23, associati all’istanza EVPN EVI-2. A ciascuno dei 4 domini di bridging viene associata una subnet IP e una interfaccia virtuale IRB, il cui indirizzo IP è parte della subnet IP associata, e viene utilizzato come default gateway per il traffico inter-vlan.
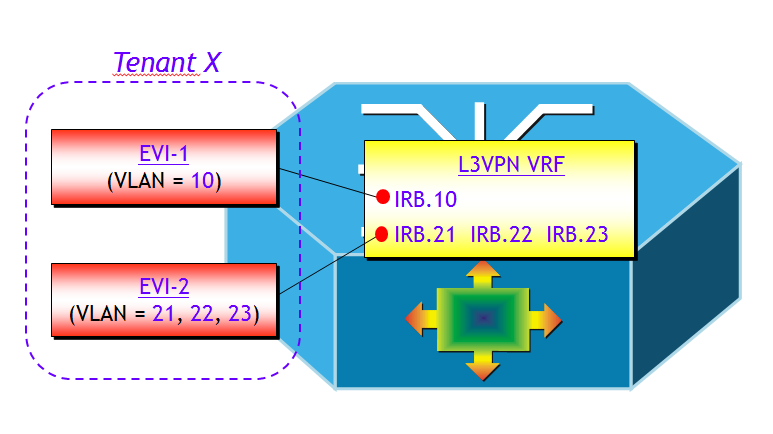
Ci sono due funzioni chiave per il supporto delle funzionalità EVPN IRB:
SINCRONIZZAZIONE DEI DEFAULT GATEWAY
Come noto, la comunicazione tra VLAN (inter-VLAN routing) avviene a Livello 3, definendo una interfaccia virtuale (interfaccia VLAN nella terminologia Cisco, interfaccia IRB (Integrated Routing and Bridging) nella documentazione Juniper e in molti documenti ufficiali IETF), il cui indirizzo IP funge da Default Gateway per gli Host delle VLAN coinvolte. Nel modello EVPN il funzionamento è analogo, solo che bisogna fare attenzione ad evitare una sorta di effetto trombooning, che rende il routing non ottimale.
L’importanza della sincronizzazione dei default gateway può essere apprezzata vedendo cosa accade senza di questa. Si consideri l’esempio nella figura seguente, dove l’Host H3, appartenente alla VLAN 10 e attestato a CE3, voglia scambiare traffico IP con l’Host H2, appartenente alla VLAN 20. Gli Host H2 e H3 sono connessi rispettivamente a CE2 e CE3, entrambi connessi a PE2.
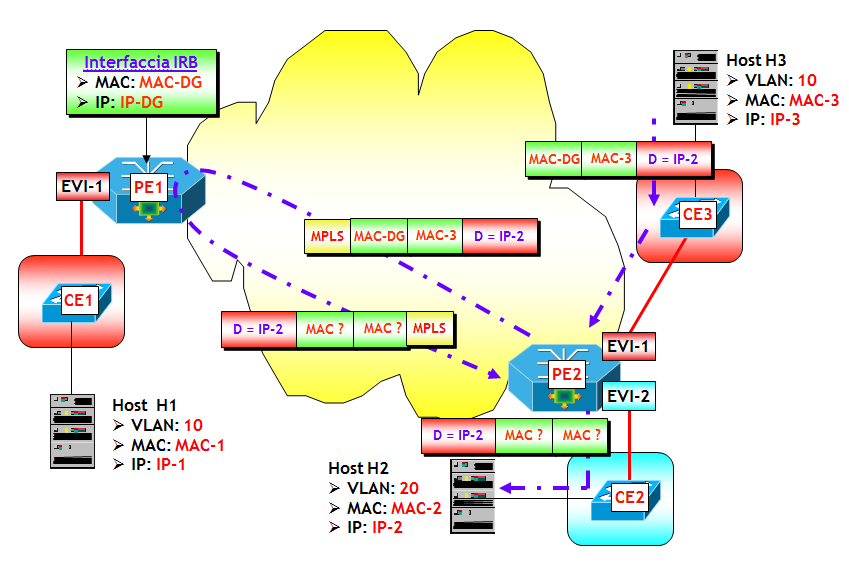
La funzione di default gateway è assegnata al router PE1, dove è configurata una interfaccia IRB con indirizzo IP = IP-DG e indirizzo MAC = MAC-DG. Il router PE1 genera un messaggio BGP EVPN con NLRI di tipo MAC/IP Advertisement per annunciare la coppia <MAC-DG; IP-DG>. PE2 riceve l’annuncio e inserisce nella MAC-VRF associata all’istanza EVPN EVI-10, l’informazione <MAC-DG; Next-Hop = PE1>. Si noti che per PE2 questo è un normale annuncio di una generica coppia <MAC; IP>; PE2 è totalmente ignaro che la coppia <MAC; IP> identifica un default gateway. Ora, questa è la sequenza degli eventi che accade quando H3 invia un pacchetto IP a H2:
La sincronizzazione dei default gateway presente nel modello EVPN, consente di risolvere il problema, distribuendo su tutti i PE che partecipano all’EVI, la funzione di default gateway. Ciò significa che ciascun PE che partecipa ad una determinata EVI, può svolgere la funzione di default gateway.
Ci sono due modi per sincronizzare i default gateway, uno statico e uno dinamico. Nella modalità statica, si configura su ciascun PE che partecipa all’EVI, una interfaccia IRB con identico indirizzo MAC e identico indirizzo IP, per ciascuna VLAN che fa parte dell’EVI. Per questo la modalità statica viene talvolta chiamata Distributed IP Anycast Gateway. Si noti che in questo caso la sincronizzazione è automatica, nel senso che non vi è bisogno per ciascun PE di annunciarsi agli altri PE come default gateway attraverso dei messaggi BGP EVPN. Per questo i costruttori, per evitare l’annuncio automatico (inutile) della coppia <MAC-DG; IP-DG> via annunci BGP EVPN, mettono a disposizione dei comandi di configurazione (es. nel JUNOS il comando “[edit routing-instances NOME-EVI] set protocols evpn default-gateway do-not-advertise”).
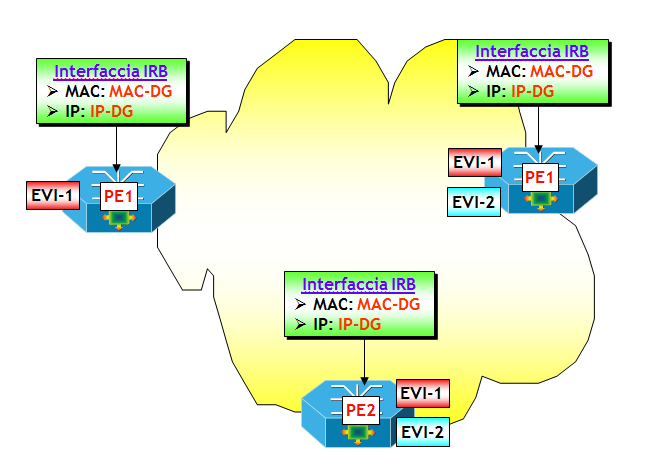
Nella modalità dinamica è prevista la possibilità di utilizzare indirizzi MAC e/o IP dei default gateway, diversi da PE a PE, per la stessa subnet IP. La sincronizzazione avviene attraverso annunci BGP EVPN con NLRI di tipo MAC/IP Advertisement, che contengono l’Extended Community Default Gateway (l’unica di cui non avevo ancora spiegato l’utilizzo). In un certo senso ciò che avviene è una sorta di aliasing del default gateway, ossia è come se il default gateway fosse virtualmente unico, con unico indirizzo IP e MAC, anche se in realtà non è vero. Si noti comunque, che è possibile utilizzare tranquillamente lo stesso indirizzo MAC, per tutte le subnet IP (come d’altra parte è anche possibile nell’inter-vlan routing tradizionale).
Quale tra le due soluzioni è preferibile ? La best practice corrente, benché la soluzione dinamica dia maggiori gradi di libertà, suggerisce di utilizzare la prima. Questo perché avere un unico IP e MAC semplifica le configurazioni, poiché consente di assegnare a tutti gli Host dello stesso segmento LAN lo stesso default gateway, riduce l’overhead del piano di controllo poiché non vi è bisogno del default gateway aliasing, e minimizza il tempo di ripristino nel caso di fuori servizio di un PE. Per quanto riguarda invece la mobilità degli Host, entrambi i metodi sono equivalenti.
La funzione Distributed IP Anycast Gateway non è peculiare del modello EVPN, ma è stata introdotto anche in altre tecnologie di tipo proprietario (vedi ad esempio la funzionalità di Virtual ARP introdotta da Arista).
INTER-VLAN ROUTING: MODALITÀ DI FORWARDING
A questo punto, risolto il nodo del default gateway, manca un solo tassello per completare il quadro, ossia vedere come avviene l’inter-vlan routing. E qui ci sono due modalità alternative, asimmetrica e simmetrica. Gli aggettivi asimmetrico/simmetrico si riferiscono a come avviene il lookup per il forwarding del traffico inter-subnet nei due PE di ingresso e uscita.
Nella modalità asimmetrica, il forwarding avviene con un doppio lookup sul PE di ingresso e un singolo lookup sul PE di uscita (da qui l’aggettivo asimmetrico). Sul PE di ingresso, il primo lookup è di tipo L2 e viene effettuato sulla tabella MAC-VRF, mentre il secondo è un lookup L3 sulla VRF. Sul PE di uscita invece il singolo lookup è di tipo L2 e viene effettuato sulla tabella MAC-VRF. Il percorso dei pacchetti IP e i lookup per l’instradamento sono schematizzati nella figura seguente.
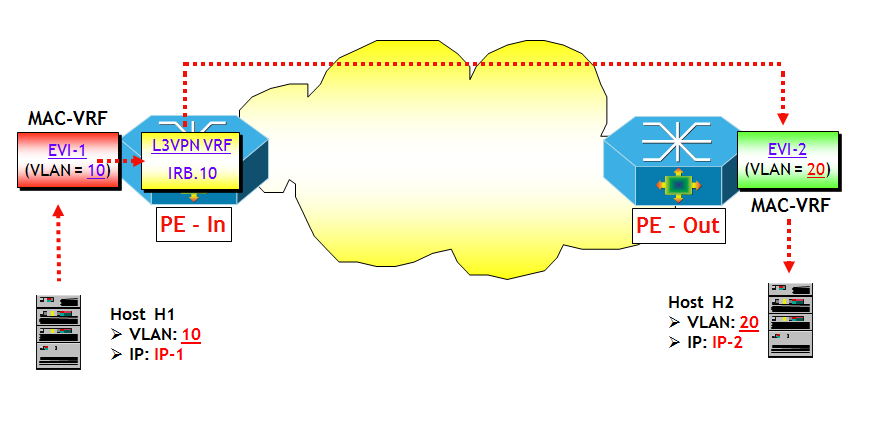
Nella modalità simmetrica, il forwarding avviene con un doppio lookup sia sul PE di ingresso che su quello di uscita (da qui l’aggettivo simmetrico). Sul PE di ingresso, il primo lookup è di tipo L2 e viene effettuato sulla tabella MAC-VRF, mentre il secondo è un lookup L3 sulla VRF associata. Sul PE di uscita, viceversa, il primo lookup è di tipo L3 e il secondo di tipo L2. Il percorso dei pacchetti IP e i lookup per l’instradamento sono schematizzati nella figura seguente.
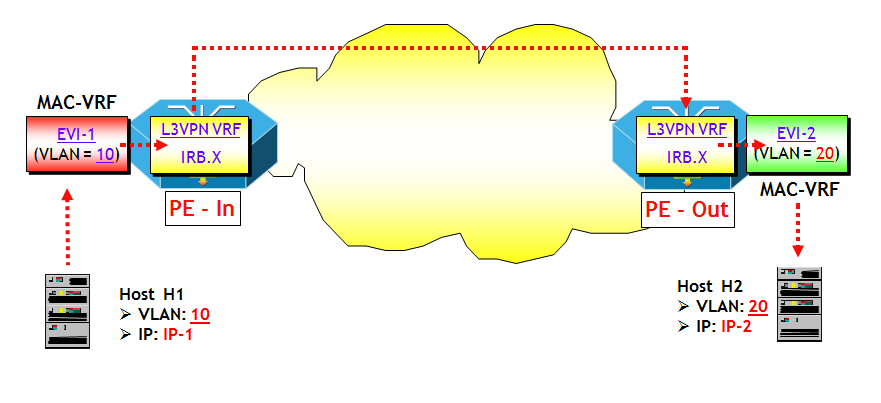
PIANO DI CONTROLLO L2/L3 INTEGRATO
Prima di vedere i dettagli sul funzionamento delle modalità di forwarding asimmetrica e simmetrica, è necessario fare maggiore luce sul funzionamento del piano di controllo nell’integrazione L2/L3. Ciò che dirò spiega le funzioni logiche del piano di controllo, le implementazioni dei vari costruttori potrebbero differire leggermente, ma i concetti rimangono validi.
Quando un PE apprende (via GARP, RARP, ecc.) un’associazione <MAC; IP> da un CE parte di una EVI, questo esegue sul piano di controllo due azioni:
Solo a titolo di esempio, queste sono le informazioni memorizzate nella VRF IP sul PE locale (PE21), che apprende l’Host route 10.1.1.2, in un router Juniper:
tt@PE21> show route 10.1.1.2
IPVPN-1.inet.0: 24 destinations, 24 routes (24 active, 0 holddown, 0 hidden)
+ = Active Route, - = Last Active, * = Both
10.1.1.2/32 *[EVPN/7] 00:03:35
> via irb.10
Queste sono invece le informazioni relative alla stessa Host route, memorizzate nella VRF IP di un PE remoto (PE11):
tt@PE11> show route 10.1.1.2
IPVPN-1.inet.0: 24 destinations, 24 routes (24 active, 0 holddown, 0 hidden)
+ = Active Route, - = Last Active, * = Both
10.1.1.2/32 *[EVPN/7] 00:4:16
> to 10.11.1.1 via xe-1/2/0.0, label-switched-path from-11-to-21
to 10.11.1.1 via xe-1/2/0.0, label-switched-path from-11-to-22
In alcune implementazioni (es. Juniper), per annunciare l’Host route i PE inviano anche i classici annunci MP-BGP L3VPN (NOTA: questo avviene perché nel JUNOS l’esportazione dei prefissi dalle VRF è automatica, a differenza dell’IOS Cisco, dove l’esportazione avviene solo a fronte di comandi di redistribuzione, a meno che il protocollo di routing PE-CE non sia eBGP). Ricordo che questi sono annunci dell’address-family VPN-IPv4/v6 (AFI/SAFI = 1/128 nel caso di VPN-IPv4, AFI/SAFI = 2/128 nel caso di VPN-IPv6). A questo annunci viene associato un classico Route-Target (RT), che consente ai PE remoti di importarlo nelle VRF del tenant. In questa implementazione, alle VRF IP dei PE remoti arrivano due annunci, entrambi BGP, della stessa Host route. Il primo annuncio via MP-BGP L3VPN classico, il secondo annuncio via BGP EVPN. Quale dei due viene utilizzato ? Attenzione che il processo di selezione BGP in questo caso non vale, ossia non è il processo BGP che sceglie il best-path tra i due annunci (i quali è vero che sono entrambi BGP, ma di due address-family diverse).
Ora, non resta da vedere che tipo di informazioni sono memorizzate nelle VRF IP remote e come queste informazioni vengono utilizzate per il forwarding asimmetrico e simmetrico. In ultima analisi, la differenza tra il forwarding simmetrico e asimmetrico dipende proprio dalle informazioni utilizzate.
INTER-VLAN ROUTING: FORWARDING DI TIPO ASIMMETRICO
La chiave del funzionamento del forwarding di tipo asimmetrico, sono le informazioni memorizzate nelle VRF IP dei PE remoti, alla ricezione di un annuncio BGP EVPN di tipo 2 (MAC/IP Advertisement). Oltre alle informazioni classiche, il PE che riceve un annuncio BGP EVPN, installa nella VRF IP anche il MAC dell’Host remoto e la EVPN label MPLS associata (ossia, l’etichetta contenuta nel campo “MPLS Label1”). Queste informazioni aggiuntive, consentono sul piano dati di eliminare sul PE di uscita il lookup a Livello 3.
Vediamo in dettaglio il funzionamento del piano dati. Supponiamo che un Host H1 della VLAN 10, attestato attraverso un CE1 al router PE1, voglia inviare un pacchetto IP a un Host H2 della VLAN 20, attestato a PE2 attraverso un CE2 (NOTA: gli Host non sono necessariamente Host fisici, ma potrebbero essere macchine virtuali create su un server; così come i CE non sono necessariamente macchine fisiche, ma potrebbero essere ad esempio, degli switch virtuali definiti in un Hypervisor di un server (tipici esempi, Cisco Nexus 1000v, Open vSwitch, VMware NSX, ecc.)). Su PE1 viene configurata una interfaccia IRB, supponiamo IRB.10, associata alla VLAN 10, il cui indirizzo IP svolge la funzione di default gateway. Questa interfaccia, sempre via configurazione, viene associata alla VRF IP.
L’Host H1 invia il pacchetto IP incapsulato, come da copione classico, in una trama Ethernet con MAC sorgente il proprio MAC (= MAC-1) e MAC destinazione l’indirizzo MAC del default gateway (= MAC-DG), che altro non è che l’indirizzo MAC associato all’interfaccia IRB.10. Come H1 abbia appreso l’indirizzo MAC-DG è anche questo un classico, utilizza il protocollo ARP, con PE1 che eventualmente svolge la funzione di Proxy ARP.
La trama Ethernet viene intercettata dal PE, che esegue un primo lookup sulla tabella MAC-VRF associata alla EVI. Poiché l’interfaccia di uscita risulta essere l’interfaccia (virtuale) IRB.10, viene effettuato un secondo lookup sulla VRF IP. Le informazioni per l’inoltro, contenute nella VRF IP in corrispondenza dell’indirizzo IP destinazione (IP-2), sono il Next-Hop (= PE2), il MAC dell’Host H2 (= MAC-2) e la EVPN label associata a MAC-2 (= L2).
A questo punto, PE1 incapsula il pacchetto IP originale in una trama Ethernet con MAC sorgente MAC-1, MAC destinazione MAC-2 e incapsula la trama con due etichette MPLS (un classico anche questo): la più interna è la EVPN label, la più esterna è la PSN label del LSP MPLS che congiunge PE1 a PE2. Il pacchetto MPLS così formato arriva a PE2 con la sola EVPN label (a causa del Penultimate Hop Popping MPLS), e la EVPN label viene utilizzata da PE2, come da funzionamento del modello EVPN, per effettuare un lookup sulla tabella MAC-VRF associata alla VLAN 20. Quest’ultimo lookup consente di individuare l’interfaccia uscente. Così, tolta la EVPN label, la trama Ethernet risultante viene inviata direttamente a CE2 e quindi ad H2 e il gioco è fatto. Il tutto è riassunto nella figura seguente.
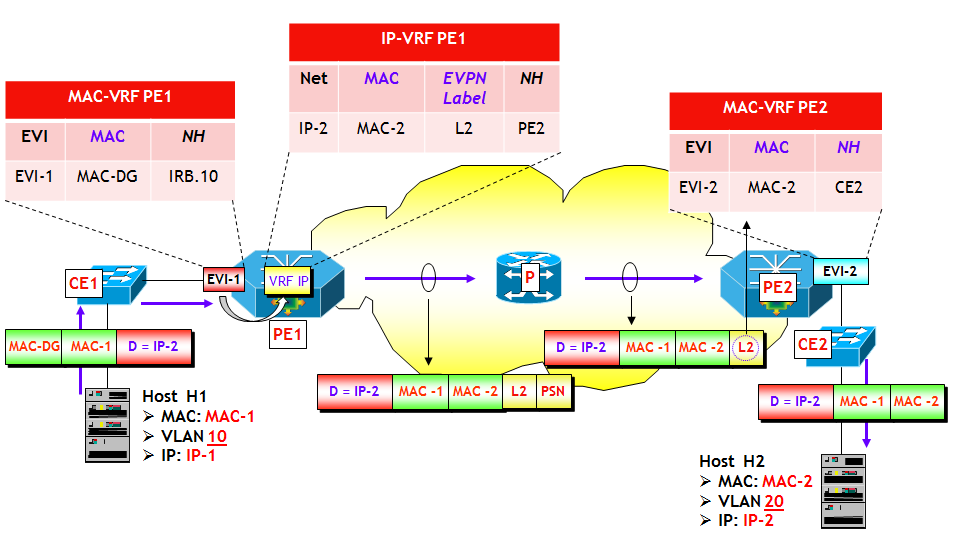
Si noti che in funzione di come viene scelta la EVPN label, l’ultimo lookup potrebbe addirittura essere evitato. Ad esempio, se PE2 scegliesse una EVPN label unica per tutti i MAC raggiungibili da CE2, a valle dell’operazione di Label Pop, la trama Ethernet potrebbe essere direttamente inviata a CE2 senza eseguire alcun lookup sulla tabella MAC-VRF di PE2.
Vorrei farvi notare che l’aspetto chiave del forwarding asimmetrico è che le informazioni per il forwarding contenute nella VRF IP su PE1, sono esattamente quelle dell’annuncio BGP EVPN inviato da PE2 a PE1 (solo la L3VPN label non viene utilizzata).
Nelle implementazioni come quella Juniper, che annunciano le Host route anche attraverso annunci classici L3VPN, le informazioni di questo secondo annuncio non vengono utilizzate, per cui questo annuncio, per risparmiare un po’ di memoria, può essere anche filtrato (ossia, scartato attraverso un filtro sul PE1 !). Attenzione però a come scrivere il filtro, perché bisogna fare in modo che altri annunci L3VPN possano essere accettati (ad esempio un eventuale annuncio di una default-route per raggiungere un Internet Gateway). Dovrei lasciarvelo come esercizio, ma visto che sto scrivendo questo post durante le vacanze natalizie, mi sento più buono del solito. Il trucco è semplice, basta aggiungere agli annunci L3VPN classici che volete filtrare, un secondo RT fittizio, e quindi configurare dei filtri che scartino gli annunci che contengono questo RT fittizio. Gli annunci L3VPN che non devono essere scartati conterranno il solo RT della L3VPN, e quindi non verranno scartati.
INTER-VLAN ROUTING: FORWARDING DI TIPO SIMMETRICO
Anche qui, la chiave del funzionamento del forwarding di tipo simmetrico, sono le informazioni memorizzate nelle VRF IP dei PE remoti, alla ricezione di un annuncio BGP EVPN di tipo 2 (MAC/IP Advertisement). Nel forwarding di tipo simmetrico, il PE che riceve un annuncio BGP EVPN, installa nella VRF IP le informazioni classiche di tipo L3VPN: la L3VPN label MPLS associata (ossia, l’etichetta contenuta nel campo “MPLS Label2”) e il BGP Next-Hop.
Vediamo in dettaglio il funzionamento del piano dati. Riprendiamo per semplicità lo stesso esempio visto nella sezione precedente sul forwarding asimmetrico. La prima parte del piano dati è identica a quella vista per il forwarding asimmetrico, ossia, l’Host H1 invia il pacchetto IP incapsulato, come da copione classico, in una trama Ethernet con MAC sorgente il proprio MAC (= MAC-1) e MAC destinazione l’indirizzo MAC del default gateway (= MAC-DG).
La trama Ethernet viene intercettata dal PE, che esegue un primo lookup sulla tabella MAC-VRF associata alla EVI. Poiché l’interfaccia di uscita risulta essere l’interfaccia (virtuale) IRB.10, viene effettuato un secondo lookup sulla VRF IP. Le informazioni per l’inoltro, contenute nella VRF IP in corrispondenza dell’indirizzo IP destinazione (IP-2), sono il BGP Next-Hop (= PE2), e la L3VPN label associata a MAC-2 (= L3).
A questo punto, PE1 incapsula il pacchetto IP originale in un pacchetto con due etichette MPLS (e non in una trama Ethernet come nel caso del forwarding asimmetrico !): la più interna è la L3VPN label, la più esterna è la PSN label del LSP MPLS che congiunge PE1 a PE2. Il pacchetto MPLS così formato arriva a PE2 con la sola L3VPN label (a causa del Penultimate Hop Popping MPLS), e la L3VPN label viene utilizzata da PE2, come da funzionamento classico del modello L3VPN, per effettuare un lookup sulla VRF IP associata. Ora, il risultato del lookup è l’interfaccia IRB.20 associata alla VLAN 20. Questo significa che per portare a destinazione il pacchetto IP è necessario un secondo lookup sulla tabella MAC-VRF associata alla VLAN 20. Quest’ultimo lookup consente di individuare l’interfaccia uscente. Il pacchetto IP verrà quindi incapsulato in una trama Ethernet con MAC sorgente pari all’indirizzo MAC del default gateway della VLAN 20 e MAC destinazione MAC-2 (ossia, l’indirizzo MAC di H2). La trama Ethernet risultante viene inviata direttamente a CE2 e quindi ad H2 e il gioco è fatto. Il tutto è riassunto nella figura seguente.
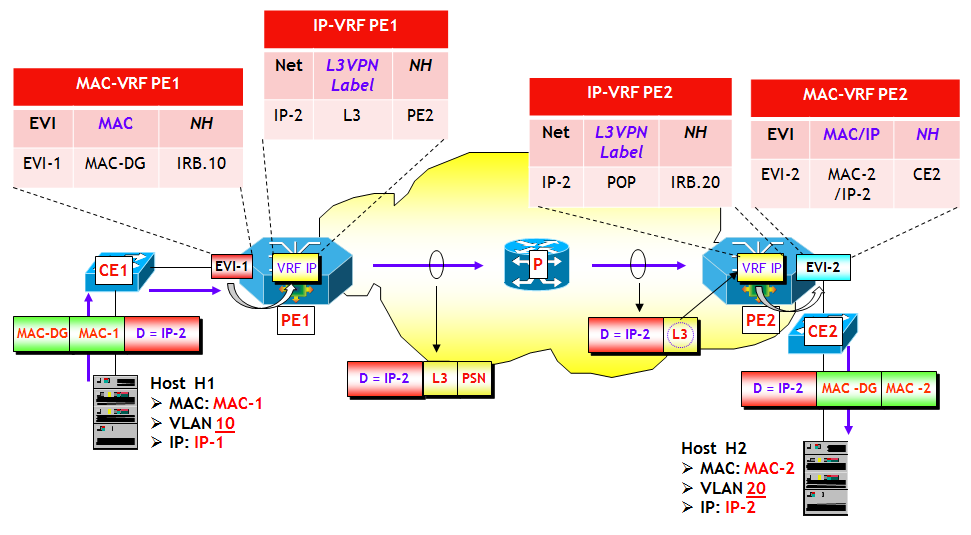
INTER-VLAN ROUTING DI TIPO ASIMMETRICO E SIMMETRICO: CONFRONTO
L’inter-vlan routing di tipo simmetrico e asimmetrico è oggi applicato quasi esclusivamente congiuntamente alle VXLAN. Come ho già citato più volte, una delle maggiori applicazioni del modello EVPN è di fare da piano di controllo per le VXLAN, per le quali, nativamente non è stato specificato alcun piano di controllo (vedi RFC 7348), o meglio, il lavoro del piano di controllo è svolto dal piano dati (il classico MAC learning) !
Per cui rimando il confronto tra le due modalità di forwarding in un prossimo post in cui tratterò diffusamente l’integrazione VXLAN/EVPN. Però sono sicuro che il lettore astuto e attento, dalla lettura delle due sezioni precedenti, una idea dei vantaggi/svantaggi delle due modalità sicuramente se la sarà fatta.
EVPN: UN PIANO DI CONTROLLO PER TUTTE LE STAGIONI ...
Per chiudere questa trilogia sul modello EVPN, vorrei mettere in evidenza una delle sue proprietà più importanti. Il modello EVPN può essere applicato in modo nativo, come evoluzione del servizio VPLS, che consente di emulare un servizio di LAN Ethernet su scala geografica.
Ma può essere integrato anche con altri standard. L’idea di fondo è sempre la stessa: la netta separazione tra piano di controllo e piano dati. Il piano di controllo EVPN è quello che abbiamo ampiamente spiegato, basato sul BGP e in particolare sugli annunci di tipo EVPN (AFI/SAFI = 25/70) e su alcune nuove Extended Community. Il piano dati che ho utilizzato finora è basato su MPLS. Ma in realtà potrebbe essere completamente diverso e basato su altri standard.
Attualmente ci sono due standard e una proposta allo stato draft, che hanno in comune il piano di controllo EVPN:
Da un punto di vista puramente pratico, personalmente non sono a conoscenza di importanti applicazioni pratiche dell’integrazione di EVPN con il PBB. Questa integrazione è molto spinta da Cisco, ma realizzazioni importanti sul campo ancora non si vedono (se qualcuno ha informazioni contrarie, avrei piacere che me le segnalasse al mio indirizzo e-mail Questo indirizzo email è protetto dagli spambots. È necessario abilitare JavaScript per vederlo.).
L’applicazione più interessante del modello EVPN è senza dubbio l’integrazione con il piano dati VXLAN. Oggi tutti i maggiori costruttori di apparati supportano l’integrazione EVPN/VXLAN (Cisco, Juniper, Alcatel, ecc.). Per questo, anche perché lo considero di importanza rilevante in ambito Data Center, tratterò questo aspetto diffusamente nei prossimi post.
CONCLUSIONI
Con questo post ho concluso una trilogia sugli aspetti fondamentali del nuovo modello EVPN. Ora su EVPN sapete tutto quello che c’è da sapere. Se avete nelle vostre reti implementato un servizio VPLS, il mio consiglio è di migrarlo, se possibile, verso il modello EVPN. Ma come ho detto poco sopra, l’applicazione più interessante del modello EVPN è senza dubbio l’integrazione con il piano dati VXLAN (e questo è alternativo all’utilizzo di un piano dati basato su MPLS, VXLAN viaggia su reti IP senza bisogno di MPLS).
Il modello EVPN mi intriga perché lo ritengo molto ben fatto, ma mi rimane un dubbio che mi porto appresso e mi angoscia da 20 anni (ossia, da quando ho iniziato a occuparmi delle reti IP): ma non sarebbe più semplice, oggi che IP è diventato un protocollo multiservizio, avere reti puramente IP, senza indirizzi MAC ? Perché un Host deve avere due indirizzi, uno MAC e uno IP ? Non sarebbe stato sufficiente un solo indirizzo (magari IPv6, così non avremmo nemmeno avuto la rogna del NAT) ? Pensateci un attimo, no ARP, no Spanning Tree, no Broadcast Storm, ecc. ecc. (e a dirla tutta, no VPLS e no EVPN !). La nostra vita sarebbe stata un po’ più semplice, per contro Cisco, Juniper e compagnia allegra avrebbero venduto molti meno apparati !!! E allora mi cresce ancor di più il dubbio: non è che siano stati i costruttori a darci delle idee tali che loro potessero venderci più roba ? (d’altra parte, in ultima analisi fanno il loro mestiere, fare più soldi possibile). Però attenzione, molti illuminati networkers si stanno ponendo lo stesso dilemma e qualche nuova startup, più creativa dei vendor tradizionali e senza gli stessi pregiudizi, sta proponendo architetture di Data Center L3-only (sentito mai parlare di Cumulus Network, di Juniper Contrail ?). C’è spazio per ampie discussioni future, nel frattempo vi consiglio di leggervi questo illuminante e stupendo post di Mark Burgess, dove troverete, parafrasando Dan Brown nel suo libro “Angeli e Demoni”, il “cammino dell’illuminazione”.
Arrivederci al prossimo post: l’evoluzione del piano di controllo delle VXLAN (con qualche piccolo lab, se riesco).
Questo aspetto del modello EVPN consente ulteriori ottimizzazioni, e gioca un ruolo molto importante nell’inter-vlan routing. Questo post sarà proprio focalizzato sull’integrazione L2/L3 nel modello EVPN.
PROXY ARP/ND
Uno degli aspetti interessanti del modello EVPN è che consente di ridurre il traffico broadcast sulla rete, in particolare il traffico dei messaggi ARP. I router PE, grazie alla conoscenza degli indirizzi IP associati agli indirizzi MAC, possono infatti svolgere la funzione di Proxy ARP (o Proxy ND nel caso di indirizzi IPv6), ossia rispondere direttamente ai messaggi ARP Request (o Neighbor Solicitation nel caso di indirizzi IPv6). Per semplicità considererò da qui in avanti solo la funzione Proxy ARP, essendo la funzione Proxy ND concettualmente identica.
Per capire bene il (semplice) funzionamento, farò riferimento alla figura seguente, dove è illustrato l’annuncio di tipo MAC/IP Advertisement da parte di PE2-1, con il quale viene annunciata la coppia <MAC-2; IP-2>.
Come faccia un PE ad apprendere un indirizzo IP associato a un indirizzo MAC l’ho spiegato nel post precedente (es. ARP/DHCP snooping, Gratuitous ARP, Reverse ARP, ecc.). Questo, seppur importante, è comunque un aspetto secondario.
Giusto per ricapitolare, questa è la sequenza degli eventi:
- L’Host 2, non appena va online invia un qualche messaggio a CE2 per segnalare la sua presenza e CE2 lo propaga a PE2-1. Il tipo di messaggio dipende dal tipo di Hypervisor o dal tipo di sistema operativo utilizzato dall’Host. Solo per fare un paio di esempi, l’Hyper-V di Microsoft, non appena una macchina virtuale va online (o anche quando la macchina migra da un server fisico ad un altro), invia un messaggio GARP (Gratuitous ARP); il vCenter di VMware (almeno fino all’ESX 5.5) invia invece un messaggio RARP (Reverse ARP) (NOTA: curiosamente i messaggi RARP non contengono il proprio indirizzo di Livello 3, ma vengono utilizzati per richiederlo, come ad esempio avviene con il DHCP. Chi non lo avesse mai sentito nominare, visto che ormai il RARP è stato soppiantato da anni dal DHCP, può migliorare le proprie conoscenze storiche del Networking IP andandosi a guardare la RFC 903 del Giugno 1984 !).
- Non appena PE2-1 apprende la presenza della coppia <MAC-2; IP-2>, genera un messaggio UPDATE BGP EVPN contenente un NLRI di tipo MAC/IP Advertisement, per annunciare agli altri PE che partecipano alla stessa EVI, la coppia <MAC-2; IP-2>.
- Sulla tabella MAC-VRF degli altri PE che partecipano alla stessa EVI (nella figura PE1-1 e PE1-2) , oltre all’informazione sull’indirizzo MAC-2, verrà quindi memorizzata anche l’informazione sull’indirizzo IP-2 associato.
Ritornando all’esempio, quando il messaggio ARP Request inviato dall’Host 1 arriva al router PE1-1, questo ha tutte le informazioni necessarie per rispondere, senza quindi il bisogno di propagare il messaggio ARP Request agli altri PE.
La figura seguente riassume la sequenza degli eventi.
- L’Host 1 invia un messaggio ARP Request con il quale richiede la conoscenza dell’indirizzo MAC associato all’indirizzo IP destinazione IP-2.
- Il router PE1-1 intercetta il messaggio ARP Request e, poiché conosce già dalla tabella MAC-VRF l’associazione <MAC-2; IP-2>, risponde direttamente con un messaggio ARP Reply, facendo le veci del router PE2-1 (funzione Proxy ARP).
- L’Host 1, analizzando il messaggio ARP Reply, impara l’associazione <MAC-2; IP-2> e quindi è in grado di inviare traffico IP all’Host 2. Si noti comunque che i pacchetti IP inviati dall’Host 1 all’Host 2, vengono commutati a Livello 2 e non a Livello 3 (come d’altra parte avviene in un classico segmento Ethernet).
Per i più curiosi in cerca di approfondimenti sugli aspetti operativi del Proxy ARP/ND nel modello EVPN, consiglio la lettura di questo breve documento IETF .
INTEGRAZIONE DI ROUTING E BRIDGING
Il fatto che il modello EVPN preveda nei suoi annunci BGP EVPN la possibilità di annunciare la coppia <MAC; IP> di un Host, consente di integrare e ottimizzare le funzioni di routing e bridging. La funzione di bridging in realtà parte già ottimizzata da tutte le funzionalità già presenti nel modello EVPN. Per il traffico intra-VLAN (o anche, in modo equivalente, intra-subnet) quindi tutte le problematiche più importanti sono già risolte dal modello EVPN. Il problema è come rendere ottimale anche il trasporto del traffico inter-VLAN (inter-subnet).
Il modello EVPN affronta queste problematiche attraverso delle funzionalità che integrano il trasporto L2 (anche noto come bridging) e il trasporto L3 (anche noto come routing). L’insieme di queste funzionalità è noto come Integrated Routing and Bridging (IRB), ed è l’oggetto di un documento IETF ancora allo stato di draft: “Integrated Routing and Bridging in EVPN” (draft-ietf-bess-evpn-inter-subnet-forwarding-01; NOTA: bess non è il nome dell’autore del draft, ma un acronimo che sta per BGP Enabled ServiceS).
Le funzionalità IRB di EVPN sono utili anche perché consentono di integrare il modello EVPN con il classico modello L3VPN, e questo è molto utile per la fornitura di servizi cloud ai propri clienti. Per maggiore flessibilità e scalabilità, per ciascun cliente (tenant) è possibile definire più domini broadcast (o domini di bridging) all’interno di ciascuna EVI, e quindi associare una o più EVI a una singola istanza L3VPN (VRF).
Per il supporto di questo modello è necessario definire una interfaccia virtuale IRB, che faccia da “ponte” tra le funzioni di Livello 2 e Livello 3. Inoltre, ciascun dominio di bridging si mappa ad un’unica subnet IP nella VRF.
In generale, a ciascun tenant di un Data Center è assegnata una singola L3VPN VRF, ma possono essere associate più EVI e uno o più domini di bridging per ciascuna EVI. La figura seguente riporta un esempio di un tenant che ha 4 domini di bridging, uno, identificato dalla VLAN 10, associato all’istanza EVPN EVI-1 e tre, identificati dalle VLAN 21, 22, 23, associati all’istanza EVPN EVI-2. A ciascuno dei 4 domini di bridging viene associata una subnet IP e una interfaccia virtuale IRB, il cui indirizzo IP è parte della subnet IP associata, e viene utilizzato come default gateway per il traffico inter-vlan.
Ci sono due funzioni chiave per il supporto delle funzionalità EVPN IRB:
- Sincronizzazione delle associazioni <MAC; IP>: questa avviene, come più volte detto, attraverso l’utilizzo degli annunci BGP EVPN con NLRI di tipo MAC/IP Advertisement. Alla ricezione di questi annunci, un PE installa nella tabella MAC-VRF associata a una EVI la coppia <MAC; Next-Hop>, e nella VRF della L3VPN associata l’indirizzo IP.
- Sincronizzazione dei Default Gateway: questa avviene sempre attraverso annunci BGP EVPN con NLRI di tipo MAC/IP Advertisement, dove la coppia <MAC; IP> annunciata corrisponde rispettivamente agli indirizzi MAC e IP dell’interfaccia IRB (per i lettori familiari con l’ambiente Cisco, credo tutti, questa altro non è che la classica “interfaccia VLAN”). Alla ricezione di questi annunci, un PE crea un forwarding state per il routing dei pacchetti IP, incapsulati in trame Ethernet con MAC destinazione il MAC dell’interfaccia IRB (che altro non è che il MAC del default gateway). Il PE esegue anche la funzione di Proxy ARP/ND per il default gateway (ossia, risponde ai messaggi ARP Request degli Host, che richiedono l’indirizzo MAC corrispondente all’indirizzo IP del default gateway).
SINCRONIZZAZIONE DEI DEFAULT GATEWAY
Come noto, la comunicazione tra VLAN (inter-VLAN routing) avviene a Livello 3, definendo una interfaccia virtuale (interfaccia VLAN nella terminologia Cisco, interfaccia IRB (Integrated Routing and Bridging) nella documentazione Juniper e in molti documenti ufficiali IETF), il cui indirizzo IP funge da Default Gateway per gli Host delle VLAN coinvolte. Nel modello EVPN il funzionamento è analogo, solo che bisogna fare attenzione ad evitare una sorta di effetto trombooning, che rende il routing non ottimale.
L’importanza della sincronizzazione dei default gateway può essere apprezzata vedendo cosa accade senza di questa. Si consideri l’esempio nella figura seguente, dove l’Host H3, appartenente alla VLAN 10 e attestato a CE3, voglia scambiare traffico IP con l’Host H2, appartenente alla VLAN 20. Gli Host H2 e H3 sono connessi rispettivamente a CE2 e CE3, entrambi connessi a PE2.
La funzione di default gateway è assegnata al router PE1, dove è configurata una interfaccia IRB con indirizzo IP = IP-DG e indirizzo MAC = MAC-DG. Il router PE1 genera un messaggio BGP EVPN con NLRI di tipo MAC/IP Advertisement per annunciare la coppia <MAC-DG; IP-DG>. PE2 riceve l’annuncio e inserisce nella MAC-VRF associata all’istanza EVPN EVI-10, l’informazione <MAC-DG; Next-Hop = PE1>. Si noti che per PE2 questo è un normale annuncio di una generica coppia <MAC; IP>; PE2 è totalmente ignaro che la coppia <MAC; IP> identifica un default gateway. Ora, questa è la sequenza degli eventi che accade quando H3 invia un pacchetto IP a H2:
- H3 invia un messaggio ARP Request a PE3 (via CE3) per chiedere l’indirizzo MAC corrispondente all’indirizzo IP del default gateway (= IP-DG).
- PE3 intercetta il messaggio ARP Request e risponde direttamente (funzione di Proxy ARP) inviando a H3 un ARP Reply. H3 apprende così l’indirizzo MAC del default gateway (= MAC-DG).
- H3 invia un pacchetto IP con indirizzo IP destinazione di H2 (= IP-2) e indirizzo IP sorgente il proprio (= IP-3). Il pacchetto IP viene incapsulato in una trama Ethernet con indirizzo MAC sorgente di H3 (= MAC-3) e indirizzo MAC destinazione del default gateway (= MAC-DG).
- PE2 invia la trama Ethernet, incapsulata con le opportune etichette MPLS, al Next-Hop PE1.
- PE1, dopo l’operazione di label pop, riceve la trama Ethernet con indirizzo MAC destinazione MAC-DG. Questo significa che deve eseguire un lookup a livello IP, per inoltrare il pacchetto verso l’indirizzo IP destinazione (= IP-2), ossia, in altre parole PE1 esegue l’operazione di inter-vlan routing.
- Il pacchetto viene quindi inoltrato, via routing IP classico, all’Host destinazione H2 (in realtà, come mostrerò nel seguito, il routing IP non è tanto classico; nella figura ho omesso gli indirizzi MAC utilizzati, poiché dipendono dalla modalità di inter-vlan routing scelta, simmetrica o asimmetrica).
La sincronizzazione dei default gateway presente nel modello EVPN, consente di risolvere il problema, distribuendo su tutti i PE che partecipano all’EVI, la funzione di default gateway. Ciò significa che ciascun PE che partecipa ad una determinata EVI, può svolgere la funzione di default gateway.
Ci sono due modi per sincronizzare i default gateway, uno statico e uno dinamico. Nella modalità statica, si configura su ciascun PE che partecipa all’EVI, una interfaccia IRB con identico indirizzo MAC e identico indirizzo IP, per ciascuna VLAN che fa parte dell’EVI. Per questo la modalità statica viene talvolta chiamata Distributed IP Anycast Gateway. Si noti che in questo caso la sincronizzazione è automatica, nel senso che non vi è bisogno per ciascun PE di annunciarsi agli altri PE come default gateway attraverso dei messaggi BGP EVPN. Per questo i costruttori, per evitare l’annuncio automatico (inutile) della coppia <MAC-DG; IP-DG> via annunci BGP EVPN, mettono a disposizione dei comandi di configurazione (es. nel JUNOS il comando “[edit routing-instances NOME-EVI] set protocols evpn default-gateway do-not-advertise”).
Nella modalità dinamica è prevista la possibilità di utilizzare indirizzi MAC e/o IP dei default gateway, diversi da PE a PE, per la stessa subnet IP. La sincronizzazione avviene attraverso annunci BGP EVPN con NLRI di tipo MAC/IP Advertisement, che contengono l’Extended Community Default Gateway (l’unica di cui non avevo ancora spiegato l’utilizzo). In un certo senso ciò che avviene è una sorta di aliasing del default gateway, ossia è come se il default gateway fosse virtualmente unico, con unico indirizzo IP e MAC, anche se in realtà non è vero. Si noti comunque, che è possibile utilizzare tranquillamente lo stesso indirizzo MAC, per tutte le subnet IP (come d’altra parte è anche possibile nell’inter-vlan routing tradizionale).
Quale tra le due soluzioni è preferibile ? La best practice corrente, benché la soluzione dinamica dia maggiori gradi di libertà, suggerisce di utilizzare la prima. Questo perché avere un unico IP e MAC semplifica le configurazioni, poiché consente di assegnare a tutti gli Host dello stesso segmento LAN lo stesso default gateway, riduce l’overhead del piano di controllo poiché non vi è bisogno del default gateway aliasing, e minimizza il tempo di ripristino nel caso di fuori servizio di un PE. Per quanto riguarda invece la mobilità degli Host, entrambi i metodi sono equivalenti.
La funzione Distributed IP Anycast Gateway non è peculiare del modello EVPN, ma è stata introdotto anche in altre tecnologie di tipo proprietario (vedi ad esempio la funzionalità di Virtual ARP introdotta da Arista).
INTER-VLAN ROUTING: MODALITÀ DI FORWARDING
A questo punto, risolto il nodo del default gateway, manca un solo tassello per completare il quadro, ossia vedere come avviene l’inter-vlan routing. E qui ci sono due modalità alternative, asimmetrica e simmetrica. Gli aggettivi asimmetrico/simmetrico si riferiscono a come avviene il lookup per il forwarding del traffico inter-subnet nei due PE di ingresso e uscita.
Nella modalità asimmetrica, il forwarding avviene con un doppio lookup sul PE di ingresso e un singolo lookup sul PE di uscita (da qui l’aggettivo asimmetrico). Sul PE di ingresso, il primo lookup è di tipo L2 e viene effettuato sulla tabella MAC-VRF, mentre il secondo è un lookup L3 sulla VRF. Sul PE di uscita invece il singolo lookup è di tipo L2 e viene effettuato sulla tabella MAC-VRF. Il percorso dei pacchetti IP e i lookup per l’instradamento sono schematizzati nella figura seguente.
Nella modalità simmetrica, il forwarding avviene con un doppio lookup sia sul PE di ingresso che su quello di uscita (da qui l’aggettivo simmetrico). Sul PE di ingresso, il primo lookup è di tipo L2 e viene effettuato sulla tabella MAC-VRF, mentre il secondo è un lookup L3 sulla VRF associata. Sul PE di uscita, viceversa, il primo lookup è di tipo L3 e il secondo di tipo L2. Il percorso dei pacchetti IP e i lookup per l’instradamento sono schematizzati nella figura seguente.
PIANO DI CONTROLLO L2/L3 INTEGRATO
Prima di vedere i dettagli sul funzionamento delle modalità di forwarding asimmetrica e simmetrica, è necessario fare maggiore luce sul funzionamento del piano di controllo nell’integrazione L2/L3. Ciò che dirò spiega le funzioni logiche del piano di controllo, le implementazioni dei vari costruttori potrebbero differire leggermente, ma i concetti rimangono validi.
Quando un PE apprende (via GARP, RARP, ecc.) un’associazione <MAC; IP> da un CE parte di una EVI, questo esegue sul piano di controllo due azioni:
- Il PE installa nella tabella MAC-VRF associata alla EVI, la coppia <MAC; Porta> e nella VRF IP associata, una Host route IP (/32 in IPv4, /128 in IPv6) che ha come Next-Hop l’interfaccia IRB associata alla MAC-VRF e come protocollo EVPN.
- Il PE annuncia ai PE remoti l’associazione <MAC; IP>, attraverso un annuncio BGP EVPN con NLRI di tipo 2 (MAC/IP Advertisement). Questo annuncio contiene due Route-Target (RT), uno corrispondente alla EVI e l’altro alla VRF IP. Inoltre, nei campi “MPLS Label1” e “MPLS Label2” sono contenute due etichette MPLS, la prima è la EVPN label (service label per il servizio L2VPN via modello EVPN) e la seconda la L3VPN label (service label per il servizio L3VPN).
Solo a titolo di esempio, queste sono le informazioni memorizzate nella VRF IP sul PE locale (PE21), che apprende l’Host route 10.1.1.2, in un router Juniper:
tt@PE21> show route 10.1.1.2
IPVPN-1.inet.0: 24 destinations, 24 routes (24 active, 0 holddown, 0 hidden)
+ = Active Route, - = Last Active, * = Both
10.1.1.2/32 *[EVPN/7] 00:03:35
> via irb.10
Queste sono invece le informazioni relative alla stessa Host route, memorizzate nella VRF IP di un PE remoto (PE11):
tt@PE11> show route 10.1.1.2
IPVPN-1.inet.0: 24 destinations, 24 routes (24 active, 0 holddown, 0 hidden)
+ = Active Route, - = Last Active, * = Both
10.1.1.2/32 *[EVPN/7] 00:4:16
> to 10.11.1.1 via xe-1/2/0.0, label-switched-path from-11-to-21
to 10.11.1.1 via xe-1/2/0.0, label-switched-path from-11-to-22
In alcune implementazioni (es. Juniper), per annunciare l’Host route i PE inviano anche i classici annunci MP-BGP L3VPN (NOTA: questo avviene perché nel JUNOS l’esportazione dei prefissi dalle VRF è automatica, a differenza dell’IOS Cisco, dove l’esportazione avviene solo a fronte di comandi di redistribuzione, a meno che il protocollo di routing PE-CE non sia eBGP). Ricordo che questi sono annunci dell’address-family VPN-IPv4/v6 (AFI/SAFI = 1/128 nel caso di VPN-IPv4, AFI/SAFI = 2/128 nel caso di VPN-IPv6). A questo annunci viene associato un classico Route-Target (RT), che consente ai PE remoti di importarlo nelle VRF del tenant. In questa implementazione, alle VRF IP dei PE remoti arrivano due annunci, entrambi BGP, della stessa Host route. Il primo annuncio via MP-BGP L3VPN classico, il secondo annuncio via BGP EVPN. Quale dei due viene utilizzato ? Attenzione che il processo di selezione BGP in questo caso non vale, ossia non è il processo BGP che sceglie il best-path tra i due annunci (i quali è vero che sono entrambi BGP, ma di due address-family diverse).
Ora, non resta da vedere che tipo di informazioni sono memorizzate nelle VRF IP remote e come queste informazioni vengono utilizzate per il forwarding asimmetrico e simmetrico. In ultima analisi, la differenza tra il forwarding simmetrico e asimmetrico dipende proprio dalle informazioni utilizzate.
INTER-VLAN ROUTING: FORWARDING DI TIPO ASIMMETRICO
La chiave del funzionamento del forwarding di tipo asimmetrico, sono le informazioni memorizzate nelle VRF IP dei PE remoti, alla ricezione di un annuncio BGP EVPN di tipo 2 (MAC/IP Advertisement). Oltre alle informazioni classiche, il PE che riceve un annuncio BGP EVPN, installa nella VRF IP anche il MAC dell’Host remoto e la EVPN label MPLS associata (ossia, l’etichetta contenuta nel campo “MPLS Label1”). Queste informazioni aggiuntive, consentono sul piano dati di eliminare sul PE di uscita il lookup a Livello 3.
Vediamo in dettaglio il funzionamento del piano dati. Supponiamo che un Host H1 della VLAN 10, attestato attraverso un CE1 al router PE1, voglia inviare un pacchetto IP a un Host H2 della VLAN 20, attestato a PE2 attraverso un CE2 (NOTA: gli Host non sono necessariamente Host fisici, ma potrebbero essere macchine virtuali create su un server; così come i CE non sono necessariamente macchine fisiche, ma potrebbero essere ad esempio, degli switch virtuali definiti in un Hypervisor di un server (tipici esempi, Cisco Nexus 1000v, Open vSwitch, VMware NSX, ecc.)). Su PE1 viene configurata una interfaccia IRB, supponiamo IRB.10, associata alla VLAN 10, il cui indirizzo IP svolge la funzione di default gateway. Questa interfaccia, sempre via configurazione, viene associata alla VRF IP.
L’Host H1 invia il pacchetto IP incapsulato, come da copione classico, in una trama Ethernet con MAC sorgente il proprio MAC (= MAC-1) e MAC destinazione l’indirizzo MAC del default gateway (= MAC-DG), che altro non è che l’indirizzo MAC associato all’interfaccia IRB.10. Come H1 abbia appreso l’indirizzo MAC-DG è anche questo un classico, utilizza il protocollo ARP, con PE1 che eventualmente svolge la funzione di Proxy ARP.
La trama Ethernet viene intercettata dal PE, che esegue un primo lookup sulla tabella MAC-VRF associata alla EVI. Poiché l’interfaccia di uscita risulta essere l’interfaccia (virtuale) IRB.10, viene effettuato un secondo lookup sulla VRF IP. Le informazioni per l’inoltro, contenute nella VRF IP in corrispondenza dell’indirizzo IP destinazione (IP-2), sono il Next-Hop (= PE2), il MAC dell’Host H2 (= MAC-2) e la EVPN label associata a MAC-2 (= L2).
A questo punto, PE1 incapsula il pacchetto IP originale in una trama Ethernet con MAC sorgente MAC-1, MAC destinazione MAC-2 e incapsula la trama con due etichette MPLS (un classico anche questo): la più interna è la EVPN label, la più esterna è la PSN label del LSP MPLS che congiunge PE1 a PE2. Il pacchetto MPLS così formato arriva a PE2 con la sola EVPN label (a causa del Penultimate Hop Popping MPLS), e la EVPN label viene utilizzata da PE2, come da funzionamento del modello EVPN, per effettuare un lookup sulla tabella MAC-VRF associata alla VLAN 20. Quest’ultimo lookup consente di individuare l’interfaccia uscente. Così, tolta la EVPN label, la trama Ethernet risultante viene inviata direttamente a CE2 e quindi ad H2 e il gioco è fatto. Il tutto è riassunto nella figura seguente.
Si noti che in funzione di come viene scelta la EVPN label, l’ultimo lookup potrebbe addirittura essere evitato. Ad esempio, se PE2 scegliesse una EVPN label unica per tutti i MAC raggiungibili da CE2, a valle dell’operazione di Label Pop, la trama Ethernet potrebbe essere direttamente inviata a CE2 senza eseguire alcun lookup sulla tabella MAC-VRF di PE2.
Vorrei farvi notare che l’aspetto chiave del forwarding asimmetrico è che le informazioni per il forwarding contenute nella VRF IP su PE1, sono esattamente quelle dell’annuncio BGP EVPN inviato da PE2 a PE1 (solo la L3VPN label non viene utilizzata).
Nelle implementazioni come quella Juniper, che annunciano le Host route anche attraverso annunci classici L3VPN, le informazioni di questo secondo annuncio non vengono utilizzate, per cui questo annuncio, per risparmiare un po’ di memoria, può essere anche filtrato (ossia, scartato attraverso un filtro sul PE1 !). Attenzione però a come scrivere il filtro, perché bisogna fare in modo che altri annunci L3VPN possano essere accettati (ad esempio un eventuale annuncio di una default-route per raggiungere un Internet Gateway). Dovrei lasciarvelo come esercizio, ma visto che sto scrivendo questo post durante le vacanze natalizie, mi sento più buono del solito. Il trucco è semplice, basta aggiungere agli annunci L3VPN classici che volete filtrare, un secondo RT fittizio, e quindi configurare dei filtri che scartino gli annunci che contengono questo RT fittizio. Gli annunci L3VPN che non devono essere scartati conterranno il solo RT della L3VPN, e quindi non verranno scartati.
INTER-VLAN ROUTING: FORWARDING DI TIPO SIMMETRICO
Anche qui, la chiave del funzionamento del forwarding di tipo simmetrico, sono le informazioni memorizzate nelle VRF IP dei PE remoti, alla ricezione di un annuncio BGP EVPN di tipo 2 (MAC/IP Advertisement). Nel forwarding di tipo simmetrico, il PE che riceve un annuncio BGP EVPN, installa nella VRF IP le informazioni classiche di tipo L3VPN: la L3VPN label MPLS associata (ossia, l’etichetta contenuta nel campo “MPLS Label2”) e il BGP Next-Hop.
Vediamo in dettaglio il funzionamento del piano dati. Riprendiamo per semplicità lo stesso esempio visto nella sezione precedente sul forwarding asimmetrico. La prima parte del piano dati è identica a quella vista per il forwarding asimmetrico, ossia, l’Host H1 invia il pacchetto IP incapsulato, come da copione classico, in una trama Ethernet con MAC sorgente il proprio MAC (= MAC-1) e MAC destinazione l’indirizzo MAC del default gateway (= MAC-DG).
La trama Ethernet viene intercettata dal PE, che esegue un primo lookup sulla tabella MAC-VRF associata alla EVI. Poiché l’interfaccia di uscita risulta essere l’interfaccia (virtuale) IRB.10, viene effettuato un secondo lookup sulla VRF IP. Le informazioni per l’inoltro, contenute nella VRF IP in corrispondenza dell’indirizzo IP destinazione (IP-2), sono il BGP Next-Hop (= PE2), e la L3VPN label associata a MAC-2 (= L3).
A questo punto, PE1 incapsula il pacchetto IP originale in un pacchetto con due etichette MPLS (e non in una trama Ethernet come nel caso del forwarding asimmetrico !): la più interna è la L3VPN label, la più esterna è la PSN label del LSP MPLS che congiunge PE1 a PE2. Il pacchetto MPLS così formato arriva a PE2 con la sola L3VPN label (a causa del Penultimate Hop Popping MPLS), e la L3VPN label viene utilizzata da PE2, come da funzionamento classico del modello L3VPN, per effettuare un lookup sulla VRF IP associata. Ora, il risultato del lookup è l’interfaccia IRB.20 associata alla VLAN 20. Questo significa che per portare a destinazione il pacchetto IP è necessario un secondo lookup sulla tabella MAC-VRF associata alla VLAN 20. Quest’ultimo lookup consente di individuare l’interfaccia uscente. Il pacchetto IP verrà quindi incapsulato in una trama Ethernet con MAC sorgente pari all’indirizzo MAC del default gateway della VLAN 20 e MAC destinazione MAC-2 (ossia, l’indirizzo MAC di H2). La trama Ethernet risultante viene inviata direttamente a CE2 e quindi ad H2 e il gioco è fatto. Il tutto è riassunto nella figura seguente.
INTER-VLAN ROUTING DI TIPO ASIMMETRICO E SIMMETRICO: CONFRONTO
L’inter-vlan routing di tipo simmetrico e asimmetrico è oggi applicato quasi esclusivamente congiuntamente alle VXLAN. Come ho già citato più volte, una delle maggiori applicazioni del modello EVPN è di fare da piano di controllo per le VXLAN, per le quali, nativamente non è stato specificato alcun piano di controllo (vedi RFC 7348), o meglio, il lavoro del piano di controllo è svolto dal piano dati (il classico MAC learning) !
Per cui rimando il confronto tra le due modalità di forwarding in un prossimo post in cui tratterò diffusamente l’integrazione VXLAN/EVPN. Però sono sicuro che il lettore astuto e attento, dalla lettura delle due sezioni precedenti, una idea dei vantaggi/svantaggi delle due modalità sicuramente se la sarà fatta.
EVPN: UN PIANO DI CONTROLLO PER TUTTE LE STAGIONI ...
Per chiudere questa trilogia sul modello EVPN, vorrei mettere in evidenza una delle sue proprietà più importanti. Il modello EVPN può essere applicato in modo nativo, come evoluzione del servizio VPLS, che consente di emulare un servizio di LAN Ethernet su scala geografica.
Ma può essere integrato anche con altri standard. L’idea di fondo è sempre la stessa: la netta separazione tra piano di controllo e piano dati. Il piano di controllo EVPN è quello che abbiamo ampiamente spiegato, basato sul BGP e in particolare sugli annunci di tipo EVPN (AFI/SAFI = 25/70) e su alcune nuove Extended Community. Il piano dati che ho utilizzato finora è basato su MPLS. Ma in realtà potrebbe essere completamente diverso e basato su altri standard.
Attualmente ci sono due standard e una proposta allo stato draft, che hanno in comune il piano di controllo EVPN:
- RFC 7432: piano dati MPLS.
- RFC 7623: piano dati MAC-in-MAC, anche noto come PBB (Provider Backbone Bridge), definito dallo standard IEEE 802.1ah.
- draft-ietf-bess-evpn-overlay: piano dati generico utilizzato nelle Overlay Virtual Network. In particolare il documento tratta l’integrazione di EVPN con i due standard più utilizzati, VXLAN e NVGRE (si noti che tra i due, è il primo che sta godendo del maggior supporto da parte di tutti i costruttori e produttori di software di virtualizzazione).
Da un punto di vista puramente pratico, personalmente non sono a conoscenza di importanti applicazioni pratiche dell’integrazione di EVPN con il PBB. Questa integrazione è molto spinta da Cisco, ma realizzazioni importanti sul campo ancora non si vedono (se qualcuno ha informazioni contrarie, avrei piacere che me le segnalasse al mio indirizzo e-mail Questo indirizzo email è protetto dagli spambots. È necessario abilitare JavaScript per vederlo.).
L’applicazione più interessante del modello EVPN è senza dubbio l’integrazione con il piano dati VXLAN. Oggi tutti i maggiori costruttori di apparati supportano l’integrazione EVPN/VXLAN (Cisco, Juniper, Alcatel, ecc.). Per questo, anche perché lo considero di importanza rilevante in ambito Data Center, tratterò questo aspetto diffusamente nei prossimi post.
CONCLUSIONI
Con questo post ho concluso una trilogia sugli aspetti fondamentali del nuovo modello EVPN. Ora su EVPN sapete tutto quello che c’è da sapere. Se avete nelle vostre reti implementato un servizio VPLS, il mio consiglio è di migrarlo, se possibile, verso il modello EVPN. Ma come ho detto poco sopra, l’applicazione più interessante del modello EVPN è senza dubbio l’integrazione con il piano dati VXLAN (e questo è alternativo all’utilizzo di un piano dati basato su MPLS, VXLAN viaggia su reti IP senza bisogno di MPLS).
Il modello EVPN mi intriga perché lo ritengo molto ben fatto, ma mi rimane un dubbio che mi porto appresso e mi angoscia da 20 anni (ossia, da quando ho iniziato a occuparmi delle reti IP): ma non sarebbe più semplice, oggi che IP è diventato un protocollo multiservizio, avere reti puramente IP, senza indirizzi MAC ? Perché un Host deve avere due indirizzi, uno MAC e uno IP ? Non sarebbe stato sufficiente un solo indirizzo (magari IPv6, così non avremmo nemmeno avuto la rogna del NAT) ? Pensateci un attimo, no ARP, no Spanning Tree, no Broadcast Storm, ecc. ecc. (e a dirla tutta, no VPLS e no EVPN !). La nostra vita sarebbe stata un po’ più semplice, per contro Cisco, Juniper e compagnia allegra avrebbero venduto molti meno apparati !!! E allora mi cresce ancor di più il dubbio: non è che siano stati i costruttori a darci delle idee tali che loro potessero venderci più roba ? (d’altra parte, in ultima analisi fanno il loro mestiere, fare più soldi possibile). Però attenzione, molti illuminati networkers si stanno ponendo lo stesso dilemma e qualche nuova startup, più creativa dei vendor tradizionali e senza gli stessi pregiudizi, sta proponendo architetture di Data Center L3-only (sentito mai parlare di Cumulus Network, di Juniper Contrail ?). C’è spazio per ampie discussioni future, nel frattempo vi consiglio di leggervi questo illuminante e stupendo post di Mark Burgess, dove troverete, parafrasando Dan Brown nel suo libro “Angeli e Demoni”, il “cammino dell’illuminazione”.
Arrivederci al prossimo post: l’evoluzione del piano di controllo delle VXLAN (con qualche piccolo lab, se riesco).
Pubblicato in
ReissBlog
Etichettato sotto
Martedì, 22 Dicembre 2015 15:45
AUGURI
Carissimi Lettori del blog,
vi auguro un Buon Natale e come dico ogni anno ai miei Amici, "noi speriamo che ce la caviamo" anche nel 2016.
Volevo chiudere l’anno con un nuovo post sul modello EVPN, giusto per completare la trilogia, ma gli impegni di lavoro non mi hanno dato il tempo di scriverlo. Sarà pronto per il ritorno dalle solenni “abbuffate” natalizie e di fine anno.
Quest’anno ho scritto 24 post sugli argomenti più disparati. Tra questi ci sono vari capitoli del libro su IS-IS (brutto acronimo di questi tempi !), che è arrivato al Capitolo 9. Ne mancano due, praticamente pronti, che pubblicherò nel 2016.
Lo spirito del blog è quello di tenervi aggiornati su cose nuove e interessanti nei campi che mi sono più familiari. Ci sono molte novità in arrivo, il mondo del networking sta conoscendo nuovi stimoli e si stanno affacciando sulla scena molte novità, soprattutto legate alle nuove tecnologie dei Data Center e della virtualizzazione. Cercherò, per quanto mi è possibile, di tenervi sempre aggiornati. Purtroppo le cose da scrivere sarebbero infinite e il tempo è tiranno (e chissà, forse anche l’energia inizia inesorabilmente a calare).
Se pensate che questo blog possa essere utile anche a vostri colleghi e/o amici, fate pubblicità. Non costa niente, è solo un servizio che la Reiss Romoli srl, mette a disposizione per diffondere la cultura dell'Internetworking IP.
Di nuovo Buon Natale e auguri per un ottimo 2016 (e speriamo che questa sia la volta buona, il PIL Italiano è previsto in crescita del 1,5% nel 2016 ...).

vi auguro un Buon Natale e come dico ogni anno ai miei Amici, "noi speriamo che ce la caviamo" anche nel 2016.
Volevo chiudere l’anno con un nuovo post sul modello EVPN, giusto per completare la trilogia, ma gli impegni di lavoro non mi hanno dato il tempo di scriverlo. Sarà pronto per il ritorno dalle solenni “abbuffate” natalizie e di fine anno.
Quest’anno ho scritto 24 post sugli argomenti più disparati. Tra questi ci sono vari capitoli del libro su IS-IS (brutto acronimo di questi tempi !), che è arrivato al Capitolo 9. Ne mancano due, praticamente pronti, che pubblicherò nel 2016.
Lo spirito del blog è quello di tenervi aggiornati su cose nuove e interessanti nei campi che mi sono più familiari. Ci sono molte novità in arrivo, il mondo del networking sta conoscendo nuovi stimoli e si stanno affacciando sulla scena molte novità, soprattutto legate alle nuove tecnologie dei Data Center e della virtualizzazione. Cercherò, per quanto mi è possibile, di tenervi sempre aggiornati. Purtroppo le cose da scrivere sarebbero infinite e il tempo è tiranno (e chissà, forse anche l’energia inizia inesorabilmente a calare).
Se pensate che questo blog possa essere utile anche a vostri colleghi e/o amici, fate pubblicità. Non costa niente, è solo un servizio che la Reiss Romoli srl, mette a disposizione per diffondere la cultura dell'Internetworking IP.
Di nuovo Buon Natale e auguri per un ottimo 2016 (e speriamo che questa sia la volta buona, il PIL Italiano è previsto in crescita del 1,5% nel 2016 ...).
Pubblicato in
ReissBlog
Etichettato sotto
Sabato, 05 Dicembre 2015 14:24
EVPN: L’EVOLUZIONE DEL SERVIZIO VPLS – PARTE II
Nel post precedente sul modello EVPN ho illustrato i concetti e le idee fondamentali, focalizzando l’attenzione soprattutto alle problematiche legate alla gestione dei collegamenti multi-homed e alle loro (eleganti) soluzioni. Ho tralasciato molti dettagli di funzionamento, che in questo post cercherò almeno in parte di colmare.
In particolare, illustrerò quali sono i nuovi BGP NLRI dell’address-family EVPN (AFI/SAFI = 25/70), e le nuove extended community introdotte. Poi farò vedere come viene eletto il Designated Forwarder e come viene trasportato il traffico, sia BUM che unicast. Infine illustrerò i principi generali del MAC mobility, ossia la possibilità che un indirizzo MAC si muova da un segmento Ethernet a un altro. Vi preannuncio che comunque le cose da dire sono ancora molte, per cui aspettatevi altri post sull’argomento.
DETERMINAZIONE DELL’ESI
Nel post precedente ho illustrato il ruolo fondamentale giocato dall’ESI (Ethernet Segment Identifier) nei collegamenti multi-homed. Ricordo che l’ESI è un identificativo dell’ES (Ethernet Segment), e come tale deve essere univoco all’interno della rete (non dell’istanza EVPN (EVI) !).
La RFC 7432 ha specificato per l’ESI una lunghezza di 10 byte, con un formato molto semplice riportato nella figura seguente (tratta direttamente dalla RFC 7432).
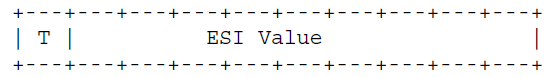
Il campo T identifica come può essere determinato dell’ESI. La RFC 7432 prevede una determinazione manuale, via configurazione, o una determinazione automatica.
Per valori di ESI configurati manualmente, T = 0x00. Per valori di ESI determinati automaticamente la RFC 7432 ha identificato ben 5 modalità diverse, identificate da T = 0x01, ..., T = 0x05. Non starò qui a illustrare tutte le 5 possibilità, farò solo vedere la prima, lasciando al lettore di “esplorare” le altre nella RFC 7432. Ma, faccio notare, non è un argomento di vitale importanza. Tanto, un ESI vale l’altro, purché sia verificata l’univocità su tutta la rete.
Quando T = 0x01, è previsto che i CE utilizzino nei loro collegamenti verso i PE, lo standard IEEE 802.1AX (LAG con LACP). Questo tipo di ESI indica un valore auto-generato, in cui i restanti 9 byte dell’ESI sono determinati dai parametri del protocollo LACP e così suddivisi (partendo dai byte più significativi):
Si noti che i due seguenti valori di ESI sono riservati:
SERVIZI EVPN E ETHERNET TAG
Nel post precedente ho introdotto, ma solo come terminologia, il concetto di Ethernet tag. Ricordo che l’Ethernet tag è un identificativo di un dominio broadcast (es. una VLAN). Una EVI consiste di uno o più domini broadcast. I valori di Ethernet tag assegnati ai domini broadcast di una data EVI, sono determinati dal tipo di servizio e assegnati dal service provider. L’Ethernet tag ha lunghezza di 32 bit, dei quali vengono utilizzati 12 o 24 bit. Nel caso in cui l’identificativo sia di 12 bit, l’Ethernet tag viene anche chiamato VLAN ID (VID) e coincide con i classici valori di VLAN ID. I valori di Ethernet tag sono utilizzati solo negli annunci BGP EVPN.
Una EVI è costituita da uno o più domini di broadcast (VLAN). Una data VLAN può a sua volta essere rappresentata da più VID (su diversi PE). In tali casi, i PE che partecipano a quella VLAN per una determinata EVI, sono responsabili della traduzione dei VID da/verso i CE collegati localmente. Se una VLAN è rappresentata da un singolo VID su tutti i PE che partecipano a quella VLAN, per quella determinata EVI, allora viene meno la necessità della traduzione dei VID da parte dei PE.
Un problema interessante a questo punto è il seguente: quale è la relazione tra i domini di broadcast (identificati ad esempio da VID), l’Ethernet tag e le MAC-VRF di ciascuna EVI ? In altre parole, quando un PE riceve un annuncio BGP EVPN contenente un dato valore di Ethernet tag, a fronte di questo annuncio il PE deve stabilire una relazione tra il valore dei VID lato CE e le EVI. Il tipo di relazione dipende dal tipo di servizio EVPN. Bene, il modello EVPN ha tre tipi di servizi a questo riguardo, che specificano quale sia questa relazione (riporto i nomi così come appaiono nella RFC 7432) e di cui voglio dare una breve descrizione:
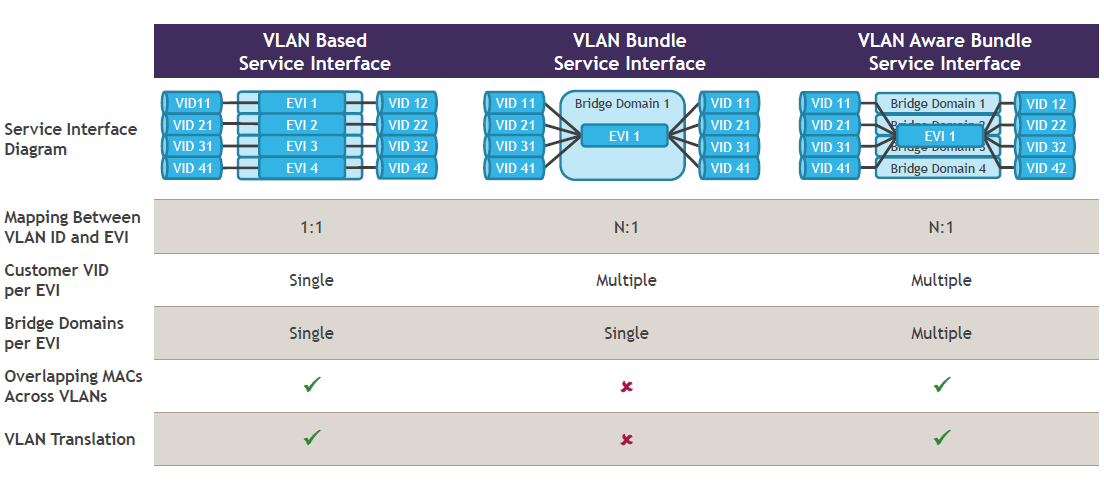
LA NUOVA ADDRESS-FAMILY BGP EVPN (AFI/SAFI = 25/70)
Come più volte detto, uno degli aspetti più innovativi del modello EVPN, è che il MAC learning remoto avviene sul piano di controllo, utilizzando annunci BGP. Per questo è stata definita una nuova address-family BGP, caratterizzata dai codici AFI/SAFI = 25/70.
Il formato generale della nuova EVPN NLRI è del classico tipo TLV (Type-Length-Value) ed è riportato nella figura seguente, dove il campo Route Type rappresenta il tipo di codifica presente nel campo Route Type Specific, il campo Length la lunghezza in byte del campo successivo, e infine il campo Route Type Specific la codifica vera e propria del NLRI.

La RFC 7432 ha definito 4 tipi diversi di NLRI, riportati nella tabella seguente.
Del secondo tipo abbiamo dato ampiamente conto nel post precedente. Degli altri, finora non abbiamo mai parlato del terzo. Sarà trattato nella sezione sotto sul trasporto del traffico BUM.
Piuttosto che dare per ciascun tipo il formato e il significato dei vari campi, preferisco riassumere in una tabella i campi più importanti e soprattutto l’utilizzo (in parte già visto nel post precedente). I lettori più curiosi possono far riferimento alla RFC 7432 per il formato completo.
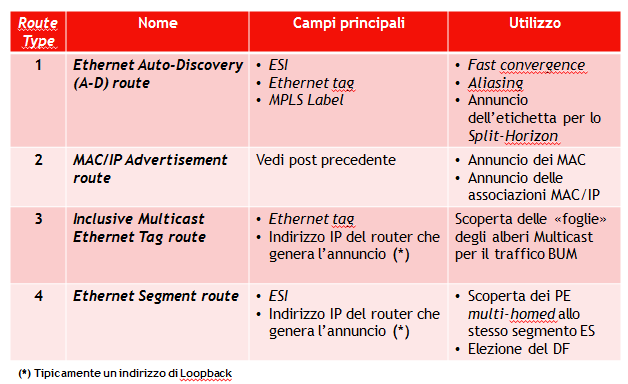
In tutti i tipi di NLRI è inoltre presente un valore di Route Distinguisher (RD), il cui formato e significato è identico a quello delle L3VPN, ossia è un valore che serve a distinguere eventuali NLRI identiche, ma generate da Clienti diversi. Si noti che la RFC 7432 impone per il RD il formato “IP-PE : valore”, dove “IP-PE” è un indirizzo IP del PE (tipicamente una interfaccia di Loopback) e “valore” è un numero arbitrario assegnato dall’amministratore del servizio.
LE NUOVE EXTENDED COMMUNITY
Il modello EVPN utilizza delle nuove BGP Extended Community, alcune delle quali già citate nel post precedente. Anche qui, piuttosto che dare per ciascuna nuova Extended Community il formato e il significato dei vari campi, preferisco riassumere in una tabella l’utilizzo (in parte già visto nel post precedente) e a quali EVPN NLRI vanno associate.

Su alcune di cui finora non abbiamo ancora visto l’utilizzo (ad esempio MAC mobility e Default Gateway), torneremo a tempo debito. Per ora è sufficiente sapere che esistono.
Oltre a queste nuove Extended Community, vi è poi il classico Route Target, utilizzato allo stesso modo e con le stesse identiche regole del servizio L3VPN e dell’auto-discovery via BGP nel servizio VPLS.
DETERMINAZIONE DEL DESIGNATED FORWARDER
Nel post precedente sul modello EVPN è stato evidenziato il ruolo chiave, nei collegamenti multi-homed, giocato dai Designated Forwarder (DF), che ricordiamo, sono quei PE multi-homed responsabili di inviare ai CE il traffico BUM. L’elezione di un DF è essenziale per risolvere problemi come ad esempio la duplicazione delle trame BUM e del ritorno del traffico BUM nei CE che lo hanno generato (Split Horizon).
L’elezione del DF avviene a valle della scoperta dei PE che sono multi-homed allo stesso ES. Per distribuire la funzione di DF tra i PE di un ES, la RFC 7432 definisce una procedura di default denominata service carving, che consente di eleggere un DF per ciascuna coppia <ES, VLAN> del caso dei servizi VLAN-based e per ciascuna coppia <ES, VLAN bundle> per i servizi VLAN bundle e VLAN-aware bundle. Con il metodo del service carving è quindi possibile l’elezione di più DF per ES, consentendo così di eseguire un Load Balancing per il traffico BUM destinato ai CE di un ES.
La procedura di service carving è basata sui seguenti passi:
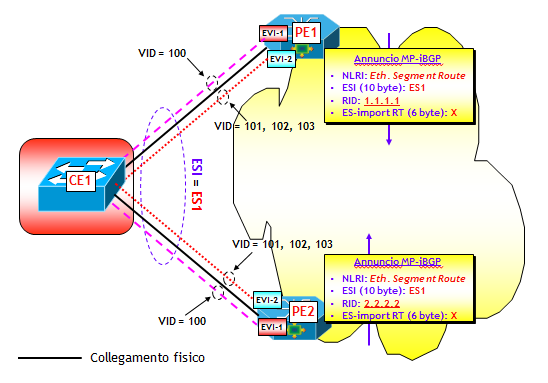
Il servizio della EVI-1 è di tipo VLAN-based mentre il servizio della EVI-2 è di tipo VLAN bundle (o VLAN-aware bundle, fa lo stesso). Il primo passo da eseguire, a valle della scoperta da parte di un PE di quali sono gli altri PE multi-homed, è l’associazione del numero intero sequenziale. Poiché l’indirizzo 1.1.1.1 è (numericamente) più basso dell’indirizzo 2.2.2.2, il PE1 ha associato il valore 0 e il PE2 il valore 1. Per determinare il DF per la EVI-1, ossia per la coppia <ES, VID = 100>, si esegue l’operazione “100 mod 2”, che da come risultato 0 (ossia, il resto della divisione tra 100 e 2). Ne consegue che il PE1 è il DF per l’EVI-1 poiché ha associato il numero intero sequenziale 0. Per determinare il DF per l’EVI-2 si esegue la stessa operazione, prendendo come valore di riferimento per il VID il minimo tra tutti VID associati all’EVI-2, ossia 101 = min [101, 102, 103]. L’operazione “V mod N” = “101 mod 2” da come risultato 1, e quindi il DF per l’EVI-2 è il PE2. “Elementare Watson”, avrebbe detto Sherlock Holmes !
ETHERNET A-D PER ES E EHTERNET A-D PER EVI
Una volta che ciascun PE ha scoperto gli altri PE multi-homed allo stesso ES, attraverso gli annunci BGP EVPN di tipo Ethernet Segment (tipo 4) e il filtraggio attraverso l’ES-import, ed eletti i DF per ciascun ES, la fase successiva nella sequenza di startup del modello EVPN, è l’annuncio degli ES. Questa fase è fondamentale per risolvere i problemi del possibile ritorno delle trame BUM sul CE che le ha generate, della convergenza veloce e dell’aliasing.
L’annuncio degli ES avviene attraverso NLRI di tipo Ethernet A-D (tipo 1). Il modello EVPN utilizza due tipi di Ethernet A-D: Ethernet A-D per ES e Ethernet A-D per EVI.
L’Ethernet A-D per ES viene sempre annunciato da ciascun PE di un ES multi-homed e contiene come informazioni:
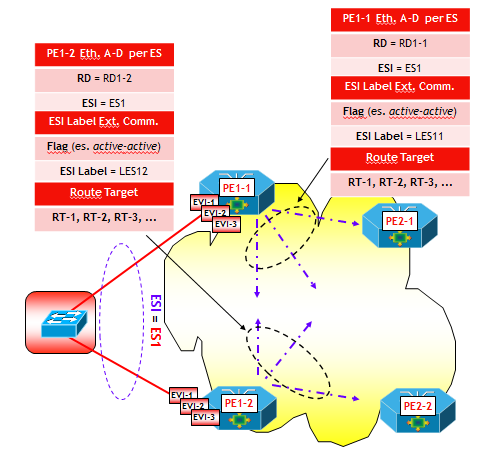
Gli annunci di tipo Ethernet A-D per ES vengono utilizzati per implementare il meccanismo dello Split Horizon e per la convergenza veloce. Per l’aliasing e il Backup Path, vengono utilizzati annunci sempre di tipo Ethernet A-D (quindi sempre di tipo 1), ma con una struttura diversa. Questi annunci, detti Ethernet A-D per EVI sono opzionali ma, almeno nelle implementazioni che ho visto finora, vengono comunque sempre inviati. In realtà nel caso di ESI = 0 (ossia, collegamenti single-homed), non sono necessari.
L’Ethernet A-D per EVI contiene come informazioni:
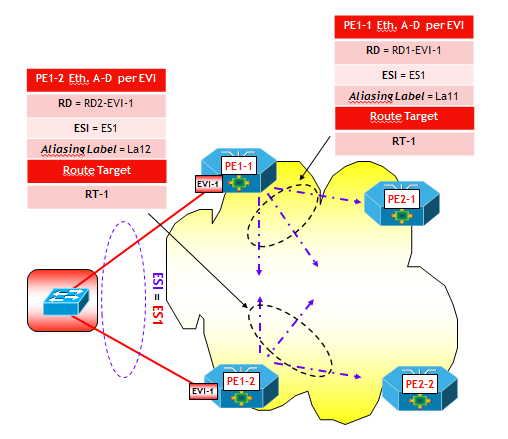
Quando un router PE “impara” da un CE multi-homed un indirizzo MAC, questo come più volte detto nel post precedente, invia un annuncio BGP EVPN del tipo MAC/IP Advertisement (tipo 2) che include l’indirizzo MAC, l’indirizzo IP associato (se noto), una etichetta MPLS e il valore di ESI che identifica l’ES da dove l’indirizzo MAC è stato appreso. Un PE remoto correla questo valore di ESI con quello presente nei due annunci Ethernet A-D (per ES e per EVI) e può così determinare l’insieme dei PE multi-homed, ai quali può trasmettere le trame Ethernet (incapsulate in qualche modo) dirette all’indirizzo MAC. Quando il PE remoto invia le trame Ethernet utilizzando come Next-Hop il PE che inviato l’annuncio di tipo MAC/IP Advertisement, incapsula le trame in un pacchetto MPLS utilizzando come etichetta interna (service label) l’etichetta associata all’annuncio MAC/IP Advertisement. Quando invece il PE remoto invia le trame Ethernet utilizzando come Next-Hop un PE che inviato gli annunci di tipo Ethernet A-D con il medesimo valore di ESI dell’annuncio MAC/IP Advertisement, utilizza l’aliasing label (a meno che il PE remoto non abbia ricevuto anche lui un MAC/IP Advertisement che annuncia lo stesso indirizzo MAC, nel qual caso utilizza anche lui la service label contenuta nell’annuncio).
TRASPORTO DEL TRAFFICO BUM
Nelle reti di Livello 2 il traffico BUM viene inoltrato attraverso un classico meccanismo di flooding, senza distinzione alcuna tra traffico multi-destinazione (multicast e broadcast) e traffico unicast ma diretto verso un indirizzo MAC sconosciuto.
Il modello EVPN introduce per la prima volta una distinzione tra traffico multi-destinazione (le lettere B e M dell’acronimo BUM) e il traffico diretto verso un indirizzo MAC sconosciuto (la lettera U dell’acronimo BUM). Infatti, mentre il traffico multi-destinazione segue il classico meccanismo del flooding, il traffico diretto verso un indirizzo MAC sconosciuto può seguire o no il classico meccanismo del flooding. La RFC 7432 a questo proposito è molto chiara. Nella sezione 12 “Processing of Unknown Unicast Packets”, così recita:
The procedures in this document do not require the PEs to flood unknown unicast traffic to other PEs. If PEs learn CE MAC addresses via a control-plane protocol, the PEs can then distribute MAC addresses via BGP, and all unicast MAC addresses will be learned prior to traffic to those destinations.
However, if a destination MAC address of a received packet is not known by the PE, the PE may have to flood the packet.
Traduciamo, per essere più chiari. La prima parte dice che la RFC 7432 non richiede tassativamente di utilizzare il meccanismo del flooding per le trame con MAC destinazione ignoto (NOTA: questo concetto non è nuovo nelle reti L2 ed è stato introdotto da Cisco nel suo protocollo OTV, Overlay Transport Virtualization, per l’interconnessione di Data Center). Poi dice che se i PE fossero in grado di “imparare” dai CE gli indirizzi MAC attraverso un meccanismo del piano di controllo (es. ARP/DHCP snooping, o qualche diavoleria tipo protocollo di routing che annunci gli indirizzi MAC raggiungibili dai CE), i PE possono distribuire la conoscenza degli indirizzi MAC (unicast) via BGP, prima che il traffico fluisca verso questi indirizzi MAC, ossia prima ancora che i MAC vengano appresi sul piano dati. Fermi tutti, ma questo non è lo stesso identico ragionamento che avviene a Livello 3, dove un PE “impara” dal piano di controllo via routing PE-CE (statico o dinamico) i prefissi raggiungibili dai CE, e quindi li annuncia agli altri PE via BGP ? Ebbene si, è esattamente lo stesso identico ragionamento. Allora vuol dire che tutti gli “esegeti” (NOTA: chiedo perdono per la forzatura nell'utilizzo di questa parola, che letteralmente significa "commentatore, interprete, critico di testi letterari, giuridici o sacri") delle reti Switched Ethernet, ossia tutti quelli che per anni ci hanno riempito la testa che le flat networks (basate sul flooding e non sui protocolli di routing) erano la soluzione di tutti i problemi del networking sono stati folgorati sulla via di Damasco e ci hanno ripensato ? Lascio a voi la conclusione.
La seconda parte dice che comunque in assenza di MAC learning PE-CE sul piano di controllo, i PE possono (= may) utilizzare il flooding. Si noti comunque che quanto detto riguarda solo il trasporto PE-PE. Il flooding a livello locale, ossia sulle interfacce lato CE, può comunque avvenire (e di solito avviene, lato CE il PE si comporta infatti come un classico L2 switch).
Bene, ciò premesso, come viene veicolato il traffico BUM nel modello EVPN ? A ben vedere, questo traffico origina da un particolare PE ed è diretto a tutti i PE della stessa EVI. Suona familiare ? Ebbene si, è lo stesso problema che si deve affrontare nel servizio L3VPN multicast o nell’inoltro del traffico BUM nelle VPLS. Per cui possono essere riciclate le stesse tecniche. I PE di una stessa EVI possono utilizzare come P-tunnel, LSP MPLS di tipo P2MP o MP2MP (trattati ampiamente in post precedenti) oppure Ingress Replication. La segnalazione di quale tipo di meccanismo utilizzare avviene attraverso annunci BGP EVPN del tipo Inclusive Multicast Ethernet Tag (tipo 3), i quali, oltre ai campi del NLRI (molto semplici, vedi la tabella sopra) contengono (obbligatoriamente) il nuovo attributo BGP PMSI Tunnel, esattamente identico a quello utilizzato nel modello NG-MVPN (vedi post precedente sull’argomento). Tra l’altro, lo stesso attributo è stato introdotto anche per il servizio VPLS che utilizza il BGP come protocollo di auto-discovery (vedi la recente RFC 7117, Multicast in Virtual Private LAN Service (VPLS)), per ottimizzare il flooding delle trame BUM.
Si noti che anche per il modello EVPN, per evitare loop interni del traffico, vale la regola dello Split Horizon utilizzata nel servizio VPLS, ossia che il traffico BUM ricevuto da un PE, non viene mai inoltrato agli altri PE della stessa EVI (NOTA: questa regola non ha niente a che vedere con la regola dello Split Horizon vista nel post precedente, tanto che la RFC 7432, per evitare confusione la indica come Split Horizon Forwarding).
Nel caso di P-tunnel di tipo Ingress Replication, ad oggi il metodo ancora preferito nelle implementazioni “primitive” del modello EVPN grazie alla sua semplicità, vengono utilizzati normali LSP MPLS di tipo P2P tra il PE di origine e tutti gli altri PE della stesa EVI. Le etichette MPLS da utilizzare vengono segnalate utilizzando il campo MPLS Label presente nell’attributo PMSI Tunnel. Queste etichette sono da considerarsi come downstream allocated, ossia devono essere utilizzate dal PE origine del traffico BUM come service label, per inviare il traffico BUM agli altri PE della stessa EVI. Per chiarire meglio concetto, illustrerò come avviene in questo caso la segnalazione e come avviene il trasporto del trasporto del traffico, ossia piano di controllo e piano dati.
La figura seguente illustra come avviene la segnalazione.
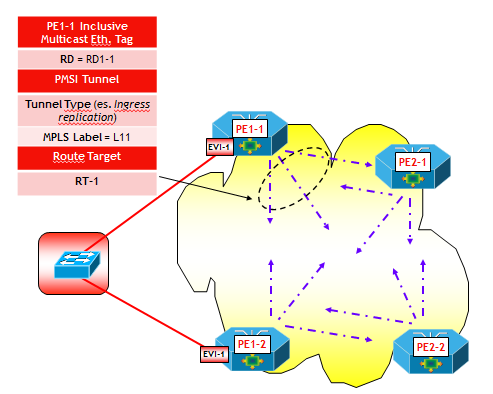
Per motivi di spazio ho evidenziato il solo annuncio EVPN generato da PE1-1. Ma ciascun PE di ciascuna istanza EVI, genera un annuncio simile. Come si può notare, l’annuncio contiene l’attributo PMSI Tunnel che definisce il tipo di P-tunnel da utilizzare (nell’esempio Ingress Replication) e ho evidenziato anche il valore di una etichetta MPLS (NOTA: il PMSI Tunnel contiene anche altri due campi, qui non evidenziati perché di minore importanza).
A questo punto vediamo il piano dati, illustrato nella figura seguente. Nella figura, le etichette segnalate dai router PEX-Y nel PMSI Tunnel sono indicate con LXY. Inoltre, nella figura compare anche la ESI-label annunciata da PE1-2 (= L12-SH) per lo Split Horizon.
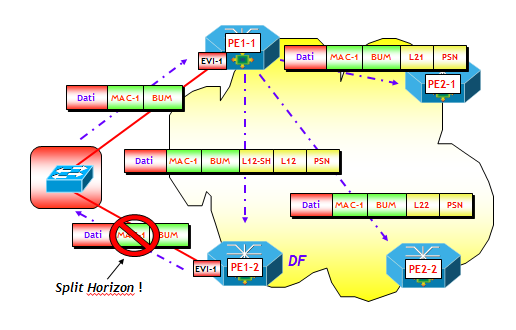
Quando PE1-1 riceve una trama Ethernet con MAC destinazione BUM, replica la trama verso tutti i PE della stessa EVI (nella figura gli altri 3 PE). A ciascuna trama viene dapprima aggiunta, dove applicabile, la ESI-label (nella figura alla sola trama diretta verso PE1-2, poiché PE1-1 e PE1-2 fanno parte dello stesso ES e PE1-2 è il DF dell’ES), quindi la service label annunciata dai PE remoti attraverso l’attributo PMSI Tunnel e infine la PSN label, ossia l’etichetta MPLS per il trasporto PE-PE (indicata nella figura genericamente come PSN).
Qualora si utilizzino come P-tunnel i più efficienti LSP MPLS di tipo multipoint (P2MP o MP2MP), la segnalazione segue le logiche già viste nei post precedenti sui LSP MPLS di tipo multipoint. In questo caso l’etichetta MPLS presente nell’attributo PMSI Tunnel non viene utilizzata poiché la demultiplazione sui PE che ricevono il traffico, avviene sulla base dell’etichetta più esterna (per questo ricordo che in questa applicazione non è ammesso il Penultimate Hop Popping). Solo nel caso di aggregazione di più EVI su un singolo P-tunnel, allora viene utilizzata l’etichetta presente nell’attributo PMSI Tunnel per demultiplare a valle l’appartenenza alla particolare EVI all’interno del (singolo) P-tunnel (e il il Penultimate Hop Popping è ammesso). L’ etichetta annunciata nell’attributo PMSI Tunnel è da considerarsi in questo caso come upstream allocated, ossia segnalata e utilizzata dai PE che originano il traffico.
Come quasi sempre accade nel mondo delle tecnologie (non solo quelle del networking !) vi è sempre un compromesso nell’utilizzo di metodi differenti. Nel caso del trasporto del traffico BUM, la scelta del tipo di P-tunnel non si sottrae a questa regola. Infatti, l’utilizzo di LSP MPLS di tipo multipoint, se da un lato ottimizzano l’uso della banda (replica dei pacchetti MPLS solo nei punti di diramazione degli alberi utilizzati), dall’altro hanno lo svantaggio di richiedere degli stati aggiuntivi sui router interni alla rete IP/MPLS (router P), per la replica dei pacchetti sui punti di diramazione. E questo aspetto potrebbe creare problemi di scalabilità considerato l’elevato numero di LSP MPLS multipoint che potrebbero essere necessari (senza aggregazione,uno per EVI). Questo non accade nel caso di Ingress Replication, dove non sono necessari stati aggiuntivi perché non esistono punti di diramazione. Per contro lo svantaggio è che la replica dei pacchetti MPLS avviene a partire dal PE di ingresso, con conseguente spreco di banda.
TRASPORTO DEL TRAFFICO UNICAST
Gli aspetti fondamentali sulla segnalazione di indirizzi MAC unicast via annunci BGP EVPN sono già stati trattati, ma voglio in questa sezione, per maggiore chiarezza, fare un riepilogo complessivo, sul quale poi innestare come avviene il trasporto del traffico unicast, quando gli indirizzi MAC sono già stati appresi.
Quando un router PE “impara” (sul piano dati o con qualche meccanismo del piano di controllo) un nuovo indirizzo MAC da un CE, sul suo attachment circuit (AC) associato a una particolare EVI, aggiunge alla sua MAC table locale (o MAC-VRF) un nuovo entry del tipo <MAC; AC>. Il PE crea quindi un annuncio BGP EVPN del tipo MAC/IP Advertisement (tipo 2), che invia (direttamente o, come più sovente accade, con l’ausilio di Route Reflector), a tutti gli altri PE della stessa EVI (NOTA: in realtà, a meno di non implementare meccanismi di BGP route-target filtering sui Route Reflector, l’annuncio viene ricevuto da tutti i PE, i quali mediante il classico filtraggio basato sui Route Target provvedono o meno ad accettarlo). Questo è essenzialmente il processo di MAC learning remoto via BGP, già descritto nel post precedente sul modello EVPN, che è la novità principale introdotta dal modello EVPN.
Come già descritto nell’ultima sezione del post precedente sul modello EVPN, gli annunci BGP EVPN di tipo MAC/IP Advertisement includono le seguenti informazioni:
Quando un PE inizialmente “impara” il solo indirizzo MAC, invia l’annuncio BGP EVPN di tipo MAC/IP Advertisement solo con queste informazioni. Qualora successivamente il PE “imparasse” con qualche “trucco” (es. ARP snooping) anche l’indirizzo IP associato all’indirizzo MAC e sul PE sia stata configurata una interfaccia IRB per la VLAN (interfaccia Integrated Routing and Bridging, spesso anche chiamata interfaccia VLAN), allora il PE invia un secondo annuncio MAC/IP Advertisement aggiungendo informazioni di livello 3 come l’indirizzo IP e il Default Gateway. Illustrerò nel prossimo post sul modello EVPN, i vantaggi che si ottengono dalla possibilità introdotta nel modello, di poter annunciare sia indirizzi MAC che indirizzi IP associati e Default Gateway.
Infine, per concludere questo breve “riassunto” del MAC learning sul piano di controllo, si noti che quando un indirizzo MAC scade (ebbene si, anche qui c’è il MAC aging !), l’entry corrispondente sulla MAC-VRF viene cancellato e l’indirizzo MAC ritirato attraverso un ritiro dell’annuncio BGP EVPN MAC/IP Advertisement inviato in precedenza. L’annuncio e il ritiro di un indirizzo MAC sono particolarmente importanti nel caso di MAC mobility, ossia quando un indirizzo MAC si muove da un ES a un altro. Illustrerò i principi che regolano la MAC mobility nella prossima sezione.
La figura seguente riassume quanto detto sulla segnalazione di un nuovo indirizzo MAC appreso da PE1-1 dal CE1 (indirizzo MAC-1). Ho anche evidenziato nella figura l’annuncio BGP EVPN di tipo Ethernet A-D per EVI, già visto sopra, e che ci servirà per capire meglio la funzionalità di aliasing sul piano dati.
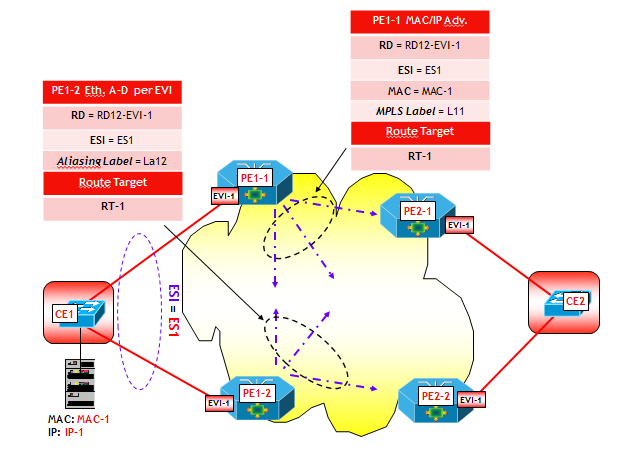
La figura seguente riporta invece il piano dati. Nella figura sono evidenziate due trame Ethernet generate da Host attestati a CE2 e inviate da questo a PE2-1. Le due trame hanno identico MAC destinazione MAC-1, noto a PE2-1 attraverso l’annuncio MAC/IP Advertisement inviato da PE1-1. Nella propria MAC-VRF, PE2-1 ha come Next-Hop sia PE1-1 che PE1-2, quest’ultimo grazie all’annuncio BGP EVPN Ethernet A-D per EVI. PE2-1 ha così la possibilità di bilanciare il traffico tra i due Next-Hop. Quando sceglie di inoltrare una trama utilizzando come Next-Hop PE1-1, la incapsula con la service label annunciata da PE1-1 attraverso l’annuncio MAC/IP Advertisement mentre quando sceglie di inoltrare una trama utilizzando come Next-Hop PE1-2, la incapsula con l’aliasing label annunciata da PE1-2 attraverso l’annuncio Ethernet A-D per EVI. In entrambi i casi viene poi aggiunta come top label, la PSN label, ossia l’etichetta MPLS che consente di trasportare i pacchetti MPLS tra il PE d’ingresso (PE2-1) e i PE di uscita (PE1-1 e PE1-2). Per completare il quadro della situazione, manca un piccolo tassello, che comunque non riguarda il modello EVPN, ma è un aspetto generale del load balancing: con quale criterio PE2-1 sceglie il Next-Hop ? Bene, qui le possibilità sono molte, ci si può affidare semplicemente agli indirizzi MAC, oppure, se possibile, andare in profondità sul pacchetto trasportato. Ad esempio, se questo fosse un semplice pacchetto TCP/IP, come hash key per il load balancing si potrebbero utilizzare tutti o parte dei seguenti campi: indirizzo IP sorgente, indirizzo IP destinazione, porta TCP sorgente, porta TCP destinazione, ecc. .
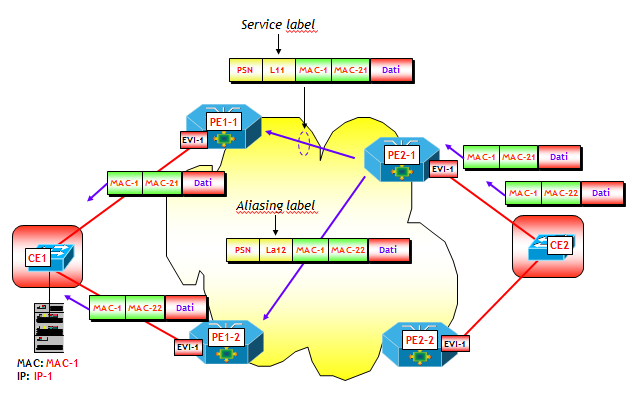
MOBILITÀ DEGLI INDIRIZZI MAC(MAC MOBILITY)
Nelle applicazioni attuali nei moderni Data Center, è pratica comune muovere le macchine virtuali (VM, Virtual Machine) da un segmento Ethernet a un altro. Questo comporta che un indirizzo MAC annunciato in precedenza da un PE, venga anche annunciato dal (o dai) PE del nuovo segmento Ethernet. Se non gestito correttamente, questo processo può portare a perdita di traffico, qualora trame Ethernet dirette all’indirizzo MAC che ha cambiato ES, vengano instradate verso il PE “vecchio”.
Per permettere a tutti i PE di una stessa EVI di “localizzare” correttamente gli indirizzi MAC “in movimento”, deve accadere che:
Per gestire correttamente situazioni transitorie che si potrebbero verificare a causa di rapidi e continui spostamenti di un indirizzo MAC tra due o più ES, negli annunci BGP EVPN di tipo MAC/IP Advertisement viene aggiunto l’attributo MAC Mobility Extended Community. Questo attributo contiene un numero di sequenza, che viene incrementato di una unità ogniqualvolta un PE invia un annuncio BGP EVPN di tipo MAC/IP Advertisement (NOTA: in realtà nel primo annuncio l’attributo non viene inserito, e ciò corrisponde di default a un numero di sequenza nullo). Quando un PE riceve un annuncio di tipo MAC/IP Advertisement con numero di sequenza più elevato di quello già in memoria, sostituisce quello presente in memoria con quello ricevuto con il numero di sequenza maggiore.
La figura seguente mostra un esempio di utilizzo dell’attributo MAC Mobility Extended Community. Nella figura si ipotizza che l’indirizzo MAC-1 si sia già mosso una volta da Ovest verso Est e che sia ritornato ad Ovest. PE1-1, una volta appreso di nuovo l’indirizzo MAC-1 (via MAC learning sul piano dati o di controllo), invia a tutti i PE della stessa EVI un annuncio MAC/IP Advertisement con l’attributo MAC Mobility Extended Community avente il numero di sequenza posto a 2.
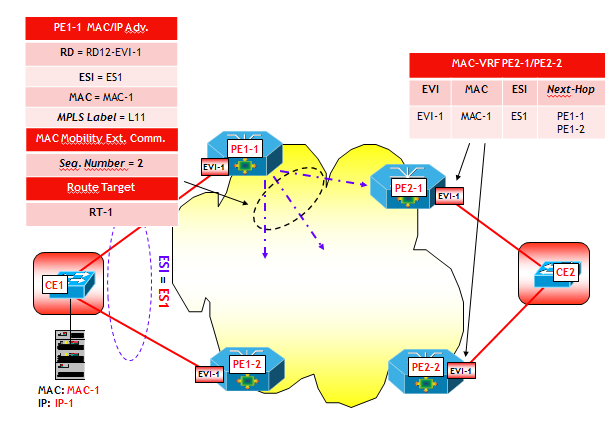
La figura seguente mostra invece cosa avviene dopo un nuovo spostamento dell’indirizzo MAC-1 da Ovest verso Est (fase 1 nella figura). Il router PE2-1, una volta accortosi (sempre via MAC learning sul piano dati o di controllo) della presenza di MAC-1 sul proprio ES, genera un nuovo annuncio di tipo MAC/IP Advertisement con numero di sequenza 3 (ossia, uno in più del valore del numero di sequenza ricevuto), che viene inviato a tutti i PE dell’EVI (fase 2 nella figura). Quando PE1-1 riceve questo nuovo annuncio con numero di sequenza maggiore, esegue due operazioni:
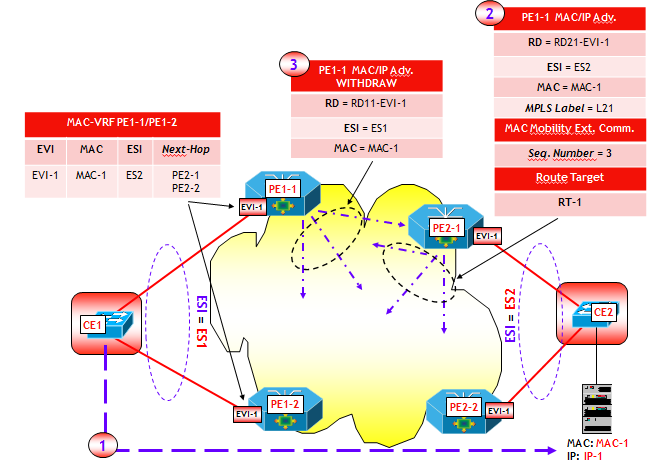
CONCLUSIONI
In questo post ho illustrato molti dettagli di funzionamento del modello EVPN introdotto in un post precedente. Finora però mi sono limitato a trattare gli aspetti legati al Livello 2, ossia di annuncio degli indirizzi MAC, del trasporto del traffico BUM e unicast noto, della mobilità degli indirizzi MAC, oltre che alle problematiche della gestione dei collegamenti multi-homed e le soluzioni ai problemi principali.
Il modello EVPN ha però un’altra formidabile freccia nel suo arco, l’integrazione con il Livello 3 (questo grazie alla possibilità offerta dagli annunci BGP EVPN di tipo MAC/IP Advertisement, di trasportare anche informazioni su un indirizzo IP associato all’indirizzo MAC). E questo è uno degli aspetti più interessanti del modello EVPN che tratterò nei post successivi.
Ricordo infine quanto detto nelle conclusioni del post precedente sul modello EVPN, questo non sta solo nelle slide, nei documenti IETF o nelle chiacchiere del sottoscritto, ma è già implementato in varie piattaforme commerciali (es. Cisco ASR 9k, Nexus 7k/9k, Juniper MX/EX, Alcatel-Lucent 7750 SR).
Coming up next... EVPN come piano di controllo per le VXLAN.
In particolare, illustrerò quali sono i nuovi BGP NLRI dell’address-family EVPN (AFI/SAFI = 25/70), e le nuove extended community introdotte. Poi farò vedere come viene eletto il Designated Forwarder e come viene trasportato il traffico, sia BUM che unicast. Infine illustrerò i principi generali del MAC mobility, ossia la possibilità che un indirizzo MAC si muova da un segmento Ethernet a un altro. Vi preannuncio che comunque le cose da dire sono ancora molte, per cui aspettatevi altri post sull’argomento.
DETERMINAZIONE DELL’ESI
Nel post precedente ho illustrato il ruolo fondamentale giocato dall’ESI (Ethernet Segment Identifier) nei collegamenti multi-homed. Ricordo che l’ESI è un identificativo dell’ES (Ethernet Segment), e come tale deve essere univoco all’interno della rete (non dell’istanza EVPN (EVI) !).
La RFC 7432 ha specificato per l’ESI una lunghezza di 10 byte, con un formato molto semplice riportato nella figura seguente (tratta direttamente dalla RFC 7432).
Il campo T identifica come può essere determinato dell’ESI. La RFC 7432 prevede una determinazione manuale, via configurazione, o una determinazione automatica.
Per valori di ESI configurati manualmente, T = 0x00. Per valori di ESI determinati automaticamente la RFC 7432 ha identificato ben 5 modalità diverse, identificate da T = 0x01, ..., T = 0x05. Non starò qui a illustrare tutte le 5 possibilità, farò solo vedere la prima, lasciando al lettore di “esplorare” le altre nella RFC 7432. Ma, faccio notare, non è un argomento di vitale importanza. Tanto, un ESI vale l’altro, purché sia verificata l’univocità su tutta la rete.
Quando T = 0x01, è previsto che i CE utilizzino nei loro collegamenti verso i PE, lo standard IEEE 802.1AX (LAG con LACP). Questo tipo di ESI indica un valore auto-generato, in cui i restanti 9 byte dell’ESI sono determinati dai parametri del protocollo LACP e così suddivisi (partendo dai byte più significativi):
- CE LACP System MAC address (6 byte).
- CE LACP Port Key (2 byte).
- Ultimo byte = 0x00.
Si noti che i due seguenti valori di ESI sono riservati:
- ESI = 0 : valore riservato ai collegamenti single-homed.
- ESI = 0xFF (ripetuto 10 volte) : valore definito nella RFC 7432 come MAX-ESI.
SERVIZI EVPN E ETHERNET TAG
Nel post precedente ho introdotto, ma solo come terminologia, il concetto di Ethernet tag. Ricordo che l’Ethernet tag è un identificativo di un dominio broadcast (es. una VLAN). Una EVI consiste di uno o più domini broadcast. I valori di Ethernet tag assegnati ai domini broadcast di una data EVI, sono determinati dal tipo di servizio e assegnati dal service provider. L’Ethernet tag ha lunghezza di 32 bit, dei quali vengono utilizzati 12 o 24 bit. Nel caso in cui l’identificativo sia di 12 bit, l’Ethernet tag viene anche chiamato VLAN ID (VID) e coincide con i classici valori di VLAN ID. I valori di Ethernet tag sono utilizzati solo negli annunci BGP EVPN.
Una EVI è costituita da uno o più domini di broadcast (VLAN). Una data VLAN può a sua volta essere rappresentata da più VID (su diversi PE). In tali casi, i PE che partecipano a quella VLAN per una determinata EVI, sono responsabili della traduzione dei VID da/verso i CE collegati localmente. Se una VLAN è rappresentata da un singolo VID su tutti i PE che partecipano a quella VLAN, per quella determinata EVI, allora viene meno la necessità della traduzione dei VID da parte dei PE.
Un problema interessante a questo punto è il seguente: quale è la relazione tra i domini di broadcast (identificati ad esempio da VID), l’Ethernet tag e le MAC-VRF di ciascuna EVI ? In altre parole, quando un PE riceve un annuncio BGP EVPN contenente un dato valore di Ethernet tag, a fronte di questo annuncio il PE deve stabilire una relazione tra il valore dei VID lato CE e le EVI. Il tipo di relazione dipende dal tipo di servizio EVPN. Bene, il modello EVPN ha tre tipi di servizi a questo riguardo, che specificano quale sia questa relazione (riporto i nomi così come appaiono nella RFC 7432) e di cui voglio dare una breve descrizione:
- VLAN-based Service Interface: in questo servizio, vi è una coincidenza 1:1 tra EVI e domini broadcast (VLAN). Le MAC-VRF di ciascuna EVI hanno quindi una singola tabella di bridging corrispondente a quella determinata VLAN. Se la VLAN è rappresentata da più VID (ad esempio, un VID diverso per ogni segmento Ethernet per PE), ogni PE ha bisogno di eseguire la traduzione tra i VID (VLAN rewrite) utilizzati per le trame destinate ai suoi Ethernet Segment. Il valore di Ethernet tag presente nei vari annunci BGP EVPN, per questo servizio, viene impostato a 0.
- VLAN Bundle Service Interface: in questo servizio, a ogni EVI sono associati più domini broadcast. Le MAC-VRF di ciascuna EVI hanno comunque una unica tabella di bridging corrispondente a tutte le VLAN che identificano i domini di broadcast. Ciò implica che gli indirizzi MAC devono essere univoci in tutte le VLAN per quella EVI. In questo servizio ogni VLAN è rappresentata da un VID univoco, ciò significa che la traduzione di VID non è ammessa. Anche per questo servizio, il valore di Ethernet tag presente nei vari annunci BGP EVPN viene impostato a 0. Un caso particolare di questo servizio è il Port-based Service Interface, dove tutte le VLAN definite su una particolare porta, sono parte della medesima EVI.
- VLAN-aware Bundle Service Interface: come il servizio precedente, a ogni EVI sono associati più domini broadcast. La differenza è però che le MAC-VRF di ciascuna EVI hanno più tabelle di bridging , una per ciascuna VLAN (ed è quindi possibile la sovrapposizione di indirizzi MAC tra le VLAN). Il traffico BUM viene inviato in questo caso ai soli CE di un determinato dominio broadcast. I VID per ciascuna VLAN possono essere identici su tutti i PE o possono essere diversi. In quest’ultimo caso è necessario implementare sui PE una funzione di VLAN rewrite. Per questo servizio, il valore di Ethernet tag presente nei vari annunci BGP EVPN viene impostato dal service provider. Come nel servizio precedente, un caso particolare di questo servizio è il Port-Based VLAN-aware Service Interface, dove tutte le VLAN definite su una particolare porta sono parte della medesima EVI, ma ciascuna VLAN ha la sua unica tabella di bridging.
LA NUOVA ADDRESS-FAMILY BGP EVPN (AFI/SAFI = 25/70)
Come più volte detto, uno degli aspetti più innovativi del modello EVPN, è che il MAC learning remoto avviene sul piano di controllo, utilizzando annunci BGP. Per questo è stata definita una nuova address-family BGP, caratterizzata dai codici AFI/SAFI = 25/70.
Il formato generale della nuova EVPN NLRI è del classico tipo TLV (Type-Length-Value) ed è riportato nella figura seguente, dove il campo Route Type rappresenta il tipo di codifica presente nel campo Route Type Specific, il campo Length la lunghezza in byte del campo successivo, e infine il campo Route Type Specific la codifica vera e propria del NLRI.
La RFC 7432 ha definito 4 tipi diversi di NLRI, riportati nella tabella seguente.
Del secondo tipo abbiamo dato ampiamente conto nel post precedente. Degli altri, finora non abbiamo mai parlato del terzo. Sarà trattato nella sezione sotto sul trasporto del traffico BUM.
Piuttosto che dare per ciascun tipo il formato e il significato dei vari campi, preferisco riassumere in una tabella i campi più importanti e soprattutto l’utilizzo (in parte già visto nel post precedente). I lettori più curiosi possono far riferimento alla RFC 7432 per il formato completo.
In tutti i tipi di NLRI è inoltre presente un valore di Route Distinguisher (RD), il cui formato e significato è identico a quello delle L3VPN, ossia è un valore che serve a distinguere eventuali NLRI identiche, ma generate da Clienti diversi. Si noti che la RFC 7432 impone per il RD il formato “IP-PE : valore”, dove “IP-PE” è un indirizzo IP del PE (tipicamente una interfaccia di Loopback) e “valore” è un numero arbitrario assegnato dall’amministratore del servizio.
LE NUOVE EXTENDED COMMUNITY
Il modello EVPN utilizza delle nuove BGP Extended Community, alcune delle quali già citate nel post precedente. Anche qui, piuttosto che dare per ciascuna nuova Extended Community il formato e il significato dei vari campi, preferisco riassumere in una tabella l’utilizzo (in parte già visto nel post precedente) e a quali EVPN NLRI vanno associate.
Su alcune di cui finora non abbiamo ancora visto l’utilizzo (ad esempio MAC mobility e Default Gateway), torneremo a tempo debito. Per ora è sufficiente sapere che esistono.
Oltre a queste nuove Extended Community, vi è poi il classico Route Target, utilizzato allo stesso modo e con le stesse identiche regole del servizio L3VPN e dell’auto-discovery via BGP nel servizio VPLS.
DETERMINAZIONE DEL DESIGNATED FORWARDER
Nel post precedente sul modello EVPN è stato evidenziato il ruolo chiave, nei collegamenti multi-homed, giocato dai Designated Forwarder (DF), che ricordiamo, sono quei PE multi-homed responsabili di inviare ai CE il traffico BUM. L’elezione di un DF è essenziale per risolvere problemi come ad esempio la duplicazione delle trame BUM e del ritorno del traffico BUM nei CE che lo hanno generato (Split Horizon).
L’elezione del DF avviene a valle della scoperta dei PE che sono multi-homed allo stesso ES. Per distribuire la funzione di DF tra i PE di un ES, la RFC 7432 definisce una procedura di default denominata service carving, che consente di eleggere un DF per ciascuna coppia <ES, VLAN> del caso dei servizi VLAN-based e per ciascuna coppia <ES, VLAN bundle> per i servizi VLAN bundle e VLAN-aware bundle. Con il metodo del service carving è quindi possibile l’elezione di più DF per ES, consentendo così di eseguire un Load Balancing per il traffico BUM destinato ai CE di un ES.
La procedura di service carving è basata sui seguenti passi:
- Quando un PE multi-homed scopre (via configurazione manuale o attraverso un qualche meccanismo di auto sensing tipo quello descritto sopra nella sezione “Determinazione dell’ESI”, basato sui parametri del protocollo LACP) il valore di ESI dell’ES a cui è (fisicamente) connesso, invia un annuncio BGP EVPN con NLRI di tipo Ethernet Segment (tipo 4), con associata una ES-import Extended Community. Il valore di ES-import è costituito da 6 dei 9 byte utili dell’ESI.
- Il PE fa quindi partire un timer, la cui durata è di 3 sec (default), per consentire la ricezione degli annunci BGP EVPN con NLRI di tipo Ethernet Segment da parte degli altri PE multi-homed allo stesso ES. Questo timer è identico per tutti i altri PE multi-homed allo stesso ES.
- Allo scadere del timer, ciascun PE crea una lista ordinata in senso crescente, degli indirizzi IP contenuti negli annunci di tipo Ethernet Segment (incluso il proprio) nel campo Originating Router’s IP address (tipicamente una interfaccia di Loopback).
- Nel caso di servizi VLAN-based il DF è il PE che ha il numero definito dall’operazione “V mod N”, dove V è il VID (NOTA: ricordo a chi non è avvezzo alle notazioni matematiche, che l’operazione “V mod N” corrisponde al banale resto della divisione tra V ed N; ad esempio “11 mod 3” = 2, “14 mod 2” = 0, ecc.).
- Nel caso invece di servizi VLAN bundle e VLAN-aware bundle, dove a ciascuna EVI corrispondono più VID, l’operazione da eseguire è identica, prendendo come valore di V il minimo VID.
Il servizio della EVI-1 è di tipo VLAN-based mentre il servizio della EVI-2 è di tipo VLAN bundle (o VLAN-aware bundle, fa lo stesso). Il primo passo da eseguire, a valle della scoperta da parte di un PE di quali sono gli altri PE multi-homed, è l’associazione del numero intero sequenziale. Poiché l’indirizzo 1.1.1.1 è (numericamente) più basso dell’indirizzo 2.2.2.2, il PE1 ha associato il valore 0 e il PE2 il valore 1. Per determinare il DF per la EVI-1, ossia per la coppia <ES, VID = 100>, si esegue l’operazione “100 mod 2”, che da come risultato 0 (ossia, il resto della divisione tra 100 e 2). Ne consegue che il PE1 è il DF per l’EVI-1 poiché ha associato il numero intero sequenziale 0. Per determinare il DF per l’EVI-2 si esegue la stessa operazione, prendendo come valore di riferimento per il VID il minimo tra tutti VID associati all’EVI-2, ossia 101 = min [101, 102, 103]. L’operazione “V mod N” = “101 mod 2” da come risultato 1, e quindi il DF per l’EVI-2 è il PE2. “Elementare Watson”, avrebbe detto Sherlock Holmes !
ETHERNET A-D PER ES E EHTERNET A-D PER EVI
Una volta che ciascun PE ha scoperto gli altri PE multi-homed allo stesso ES, attraverso gli annunci BGP EVPN di tipo Ethernet Segment (tipo 4) e il filtraggio attraverso l’ES-import, ed eletti i DF per ciascun ES, la fase successiva nella sequenza di startup del modello EVPN, è l’annuncio degli ES. Questa fase è fondamentale per risolvere i problemi del possibile ritorno delle trame BUM sul CE che le ha generate, della convergenza veloce e dell’aliasing.
L’annuncio degli ES avviene attraverso NLRI di tipo Ethernet A-D (tipo 1). Il modello EVPN utilizza due tipi di Ethernet A-D: Ethernet A-D per ES e Ethernet A-D per EVI.
L’Ethernet A-D per ES viene sempre annunciato da ciascun PE di un ES multi-homed e contiene come informazioni:
- Il valore dell’ESI.
- La ESI-label Extended Community utilizzata nel meccanismo dello Split Horizon, che, ricordo dal precedente post, consente di evitare il possibile ritorno delle trame BUM sul CE che le ha generate. Questa Extended Community contiene anche la flag che definisce la modalità di funzionamento dell’ES: flag = 0 se la modalità è active-active, flag = 1 se la modalità è single-active.
- Uno o più Route Target, per tutte le EVI alle quali appartiene l’ES.
Gli annunci di tipo Ethernet A-D per ES vengono utilizzati per implementare il meccanismo dello Split Horizon e per la convergenza veloce. Per l’aliasing e il Backup Path, vengono utilizzati annunci sempre di tipo Ethernet A-D (quindi sempre di tipo 1), ma con una struttura diversa. Questi annunci, detti Ethernet A-D per EVI sono opzionali ma, almeno nelle implementazioni che ho visto finora, vengono comunque sempre inviati. In realtà nel caso di ESI = 0 (ossia, collegamenti single-homed), non sono necessari.
L’Ethernet A-D per EVI contiene come informazioni:
- Il valore dell’ESI.
- Una etichetta MPLS utilizzata per l’aliasing (aliasing label). L’utilizzo di questa etichetta è stato specificato nel post precedente.
- Il Route Target dell’EVI.
Quando un router PE “impara” da un CE multi-homed un indirizzo MAC, questo come più volte detto nel post precedente, invia un annuncio BGP EVPN del tipo MAC/IP Advertisement (tipo 2) che include l’indirizzo MAC, l’indirizzo IP associato (se noto), una etichetta MPLS e il valore di ESI che identifica l’ES da dove l’indirizzo MAC è stato appreso. Un PE remoto correla questo valore di ESI con quello presente nei due annunci Ethernet A-D (per ES e per EVI) e può così determinare l’insieme dei PE multi-homed, ai quali può trasmettere le trame Ethernet (incapsulate in qualche modo) dirette all’indirizzo MAC. Quando il PE remoto invia le trame Ethernet utilizzando come Next-Hop il PE che inviato l’annuncio di tipo MAC/IP Advertisement, incapsula le trame in un pacchetto MPLS utilizzando come etichetta interna (service label) l’etichetta associata all’annuncio MAC/IP Advertisement. Quando invece il PE remoto invia le trame Ethernet utilizzando come Next-Hop un PE che inviato gli annunci di tipo Ethernet A-D con il medesimo valore di ESI dell’annuncio MAC/IP Advertisement, utilizza l’aliasing label (a meno che il PE remoto non abbia ricevuto anche lui un MAC/IP Advertisement che annuncia lo stesso indirizzo MAC, nel qual caso utilizza anche lui la service label contenuta nell’annuncio).
TRASPORTO DEL TRAFFICO BUM
Nelle reti di Livello 2 il traffico BUM viene inoltrato attraverso un classico meccanismo di flooding, senza distinzione alcuna tra traffico multi-destinazione (multicast e broadcast) e traffico unicast ma diretto verso un indirizzo MAC sconosciuto.
Il modello EVPN introduce per la prima volta una distinzione tra traffico multi-destinazione (le lettere B e M dell’acronimo BUM) e il traffico diretto verso un indirizzo MAC sconosciuto (la lettera U dell’acronimo BUM). Infatti, mentre il traffico multi-destinazione segue il classico meccanismo del flooding, il traffico diretto verso un indirizzo MAC sconosciuto può seguire o no il classico meccanismo del flooding. La RFC 7432 a questo proposito è molto chiara. Nella sezione 12 “Processing of Unknown Unicast Packets”, così recita:
The procedures in this document do not require the PEs to flood unknown unicast traffic to other PEs. If PEs learn CE MAC addresses via a control-plane protocol, the PEs can then distribute MAC addresses via BGP, and all unicast MAC addresses will be learned prior to traffic to those destinations.
However, if a destination MAC address of a received packet is not known by the PE, the PE may have to flood the packet.
Traduciamo, per essere più chiari. La prima parte dice che la RFC 7432 non richiede tassativamente di utilizzare il meccanismo del flooding per le trame con MAC destinazione ignoto (NOTA: questo concetto non è nuovo nelle reti L2 ed è stato introdotto da Cisco nel suo protocollo OTV, Overlay Transport Virtualization, per l’interconnessione di Data Center). Poi dice che se i PE fossero in grado di “imparare” dai CE gli indirizzi MAC attraverso un meccanismo del piano di controllo (es. ARP/DHCP snooping, o qualche diavoleria tipo protocollo di routing che annunci gli indirizzi MAC raggiungibili dai CE), i PE possono distribuire la conoscenza degli indirizzi MAC (unicast) via BGP, prima che il traffico fluisca verso questi indirizzi MAC, ossia prima ancora che i MAC vengano appresi sul piano dati. Fermi tutti, ma questo non è lo stesso identico ragionamento che avviene a Livello 3, dove un PE “impara” dal piano di controllo via routing PE-CE (statico o dinamico) i prefissi raggiungibili dai CE, e quindi li annuncia agli altri PE via BGP ? Ebbene si, è esattamente lo stesso identico ragionamento. Allora vuol dire che tutti gli “esegeti” (NOTA: chiedo perdono per la forzatura nell'utilizzo di questa parola, che letteralmente significa "commentatore, interprete, critico di testi letterari, giuridici o sacri") delle reti Switched Ethernet, ossia tutti quelli che per anni ci hanno riempito la testa che le flat networks (basate sul flooding e non sui protocolli di routing) erano la soluzione di tutti i problemi del networking sono stati folgorati sulla via di Damasco e ci hanno ripensato ? Lascio a voi la conclusione.
La seconda parte dice che comunque in assenza di MAC learning PE-CE sul piano di controllo, i PE possono (= may) utilizzare il flooding. Si noti comunque che quanto detto riguarda solo il trasporto PE-PE. Il flooding a livello locale, ossia sulle interfacce lato CE, può comunque avvenire (e di solito avviene, lato CE il PE si comporta infatti come un classico L2 switch).
Bene, ciò premesso, come viene veicolato il traffico BUM nel modello EVPN ? A ben vedere, questo traffico origina da un particolare PE ed è diretto a tutti i PE della stessa EVI. Suona familiare ? Ebbene si, è lo stesso problema che si deve affrontare nel servizio L3VPN multicast o nell’inoltro del traffico BUM nelle VPLS. Per cui possono essere riciclate le stesse tecniche. I PE di una stessa EVI possono utilizzare come P-tunnel, LSP MPLS di tipo P2MP o MP2MP (trattati ampiamente in post precedenti) oppure Ingress Replication. La segnalazione di quale tipo di meccanismo utilizzare avviene attraverso annunci BGP EVPN del tipo Inclusive Multicast Ethernet Tag (tipo 3), i quali, oltre ai campi del NLRI (molto semplici, vedi la tabella sopra) contengono (obbligatoriamente) il nuovo attributo BGP PMSI Tunnel, esattamente identico a quello utilizzato nel modello NG-MVPN (vedi post precedente sull’argomento). Tra l’altro, lo stesso attributo è stato introdotto anche per il servizio VPLS che utilizza il BGP come protocollo di auto-discovery (vedi la recente RFC 7117, Multicast in Virtual Private LAN Service (VPLS)), per ottimizzare il flooding delle trame BUM.
Si noti che anche per il modello EVPN, per evitare loop interni del traffico, vale la regola dello Split Horizon utilizzata nel servizio VPLS, ossia che il traffico BUM ricevuto da un PE, non viene mai inoltrato agli altri PE della stessa EVI (NOTA: questa regola non ha niente a che vedere con la regola dello Split Horizon vista nel post precedente, tanto che la RFC 7432, per evitare confusione la indica come Split Horizon Forwarding).
Nel caso di P-tunnel di tipo Ingress Replication, ad oggi il metodo ancora preferito nelle implementazioni “primitive” del modello EVPN grazie alla sua semplicità, vengono utilizzati normali LSP MPLS di tipo P2P tra il PE di origine e tutti gli altri PE della stesa EVI. Le etichette MPLS da utilizzare vengono segnalate utilizzando il campo MPLS Label presente nell’attributo PMSI Tunnel. Queste etichette sono da considerarsi come downstream allocated, ossia devono essere utilizzate dal PE origine del traffico BUM come service label, per inviare il traffico BUM agli altri PE della stessa EVI. Per chiarire meglio concetto, illustrerò come avviene in questo caso la segnalazione e come avviene il trasporto del trasporto del traffico, ossia piano di controllo e piano dati.
La figura seguente illustra come avviene la segnalazione.
Per motivi di spazio ho evidenziato il solo annuncio EVPN generato da PE1-1. Ma ciascun PE di ciascuna istanza EVI, genera un annuncio simile. Come si può notare, l’annuncio contiene l’attributo PMSI Tunnel che definisce il tipo di P-tunnel da utilizzare (nell’esempio Ingress Replication) e ho evidenziato anche il valore di una etichetta MPLS (NOTA: il PMSI Tunnel contiene anche altri due campi, qui non evidenziati perché di minore importanza).
A questo punto vediamo il piano dati, illustrato nella figura seguente. Nella figura, le etichette segnalate dai router PEX-Y nel PMSI Tunnel sono indicate con LXY. Inoltre, nella figura compare anche la ESI-label annunciata da PE1-2 (= L12-SH) per lo Split Horizon.
Quando PE1-1 riceve una trama Ethernet con MAC destinazione BUM, replica la trama verso tutti i PE della stessa EVI (nella figura gli altri 3 PE). A ciascuna trama viene dapprima aggiunta, dove applicabile, la ESI-label (nella figura alla sola trama diretta verso PE1-2, poiché PE1-1 e PE1-2 fanno parte dello stesso ES e PE1-2 è il DF dell’ES), quindi la service label annunciata dai PE remoti attraverso l’attributo PMSI Tunnel e infine la PSN label, ossia l’etichetta MPLS per il trasporto PE-PE (indicata nella figura genericamente come PSN).
Qualora si utilizzino come P-tunnel i più efficienti LSP MPLS di tipo multipoint (P2MP o MP2MP), la segnalazione segue le logiche già viste nei post precedenti sui LSP MPLS di tipo multipoint. In questo caso l’etichetta MPLS presente nell’attributo PMSI Tunnel non viene utilizzata poiché la demultiplazione sui PE che ricevono il traffico, avviene sulla base dell’etichetta più esterna (per questo ricordo che in questa applicazione non è ammesso il Penultimate Hop Popping). Solo nel caso di aggregazione di più EVI su un singolo P-tunnel, allora viene utilizzata l’etichetta presente nell’attributo PMSI Tunnel per demultiplare a valle l’appartenenza alla particolare EVI all’interno del (singolo) P-tunnel (e il il Penultimate Hop Popping è ammesso). L’ etichetta annunciata nell’attributo PMSI Tunnel è da considerarsi in questo caso come upstream allocated, ossia segnalata e utilizzata dai PE che originano il traffico.
Come quasi sempre accade nel mondo delle tecnologie (non solo quelle del networking !) vi è sempre un compromesso nell’utilizzo di metodi differenti. Nel caso del trasporto del traffico BUM, la scelta del tipo di P-tunnel non si sottrae a questa regola. Infatti, l’utilizzo di LSP MPLS di tipo multipoint, se da un lato ottimizzano l’uso della banda (replica dei pacchetti MPLS solo nei punti di diramazione degli alberi utilizzati), dall’altro hanno lo svantaggio di richiedere degli stati aggiuntivi sui router interni alla rete IP/MPLS (router P), per la replica dei pacchetti sui punti di diramazione. E questo aspetto potrebbe creare problemi di scalabilità considerato l’elevato numero di LSP MPLS multipoint che potrebbero essere necessari (senza aggregazione,uno per EVI). Questo non accade nel caso di Ingress Replication, dove non sono necessari stati aggiuntivi perché non esistono punti di diramazione. Per contro lo svantaggio è che la replica dei pacchetti MPLS avviene a partire dal PE di ingresso, con conseguente spreco di banda.
TRASPORTO DEL TRAFFICO UNICAST
Gli aspetti fondamentali sulla segnalazione di indirizzi MAC unicast via annunci BGP EVPN sono già stati trattati, ma voglio in questa sezione, per maggiore chiarezza, fare un riepilogo complessivo, sul quale poi innestare come avviene il trasporto del traffico unicast, quando gli indirizzi MAC sono già stati appresi.
Quando un router PE “impara” (sul piano dati o con qualche meccanismo del piano di controllo) un nuovo indirizzo MAC da un CE, sul suo attachment circuit (AC) associato a una particolare EVI, aggiunge alla sua MAC table locale (o MAC-VRF) un nuovo entry del tipo <MAC; AC>. Il PE crea quindi un annuncio BGP EVPN del tipo MAC/IP Advertisement (tipo 2), che invia (direttamente o, come più sovente accade, con l’ausilio di Route Reflector), a tutti gli altri PE della stessa EVI (NOTA: in realtà, a meno di non implementare meccanismi di BGP route-target filtering sui Route Reflector, l’annuncio viene ricevuto da tutti i PE, i quali mediante il classico filtraggio basato sui Route Target provvedono o meno ad accettarlo). Questo è essenzialmente il processo di MAC learning remoto via BGP, già descritto nel post precedente sul modello EVPN, che è la novità principale introdotta dal modello EVPN.
Come già descritto nell’ultima sezione del post precedente sul modello EVPN, gli annunci BGP EVPN di tipo MAC/IP Advertisement includono le seguenti informazioni:
- L’indirizzo MAC da annunciare.
- L’Ethernet Tag, o VLAN ID, al quale l’indirizzo MAC appartiene.
- L’ESI del segmento Ethernet dal quale l’indirizzo MAC è stato appreso (fondamentale per applicare l’aliasing).
- Una etichetta MPLS che svolge il ruolo di service label.
Quando un PE inizialmente “impara” il solo indirizzo MAC, invia l’annuncio BGP EVPN di tipo MAC/IP Advertisement solo con queste informazioni. Qualora successivamente il PE “imparasse” con qualche “trucco” (es. ARP snooping) anche l’indirizzo IP associato all’indirizzo MAC e sul PE sia stata configurata una interfaccia IRB per la VLAN (interfaccia Integrated Routing and Bridging, spesso anche chiamata interfaccia VLAN), allora il PE invia un secondo annuncio MAC/IP Advertisement aggiungendo informazioni di livello 3 come l’indirizzo IP e il Default Gateway. Illustrerò nel prossimo post sul modello EVPN, i vantaggi che si ottengono dalla possibilità introdotta nel modello, di poter annunciare sia indirizzi MAC che indirizzi IP associati e Default Gateway.
Infine, per concludere questo breve “riassunto” del MAC learning sul piano di controllo, si noti che quando un indirizzo MAC scade (ebbene si, anche qui c’è il MAC aging !), l’entry corrispondente sulla MAC-VRF viene cancellato e l’indirizzo MAC ritirato attraverso un ritiro dell’annuncio BGP EVPN MAC/IP Advertisement inviato in precedenza. L’annuncio e il ritiro di un indirizzo MAC sono particolarmente importanti nel caso di MAC mobility, ossia quando un indirizzo MAC si muove da un ES a un altro. Illustrerò i principi che regolano la MAC mobility nella prossima sezione.
La figura seguente riassume quanto detto sulla segnalazione di un nuovo indirizzo MAC appreso da PE1-1 dal CE1 (indirizzo MAC-1). Ho anche evidenziato nella figura l’annuncio BGP EVPN di tipo Ethernet A-D per EVI, già visto sopra, e che ci servirà per capire meglio la funzionalità di aliasing sul piano dati.
La figura seguente riporta invece il piano dati. Nella figura sono evidenziate due trame Ethernet generate da Host attestati a CE2 e inviate da questo a PE2-1. Le due trame hanno identico MAC destinazione MAC-1, noto a PE2-1 attraverso l’annuncio MAC/IP Advertisement inviato da PE1-1. Nella propria MAC-VRF, PE2-1 ha come Next-Hop sia PE1-1 che PE1-2, quest’ultimo grazie all’annuncio BGP EVPN Ethernet A-D per EVI. PE2-1 ha così la possibilità di bilanciare il traffico tra i due Next-Hop. Quando sceglie di inoltrare una trama utilizzando come Next-Hop PE1-1, la incapsula con la service label annunciata da PE1-1 attraverso l’annuncio MAC/IP Advertisement mentre quando sceglie di inoltrare una trama utilizzando come Next-Hop PE1-2, la incapsula con l’aliasing label annunciata da PE1-2 attraverso l’annuncio Ethernet A-D per EVI. In entrambi i casi viene poi aggiunta come top label, la PSN label, ossia l’etichetta MPLS che consente di trasportare i pacchetti MPLS tra il PE d’ingresso (PE2-1) e i PE di uscita (PE1-1 e PE1-2). Per completare il quadro della situazione, manca un piccolo tassello, che comunque non riguarda il modello EVPN, ma è un aspetto generale del load balancing: con quale criterio PE2-1 sceglie il Next-Hop ? Bene, qui le possibilità sono molte, ci si può affidare semplicemente agli indirizzi MAC, oppure, se possibile, andare in profondità sul pacchetto trasportato. Ad esempio, se questo fosse un semplice pacchetto TCP/IP, come hash key per il load balancing si potrebbero utilizzare tutti o parte dei seguenti campi: indirizzo IP sorgente, indirizzo IP destinazione, porta TCP sorgente, porta TCP destinazione, ecc. .
MOBILITÀ DEGLI INDIRIZZI MAC(MAC MOBILITY)
Nelle applicazioni attuali nei moderni Data Center, è pratica comune muovere le macchine virtuali (VM, Virtual Machine) da un segmento Ethernet a un altro. Questo comporta che un indirizzo MAC annunciato in precedenza da un PE, venga anche annunciato dal (o dai) PE del nuovo segmento Ethernet. Se non gestito correttamente, questo processo può portare a perdita di traffico, qualora trame Ethernet dirette all’indirizzo MAC che ha cambiato ES, vengano instradate verso il PE “vecchio”.
Per permettere a tutti i PE di una stessa EVI di “localizzare” correttamente gli indirizzi MAC “in movimento”, deve accadere che:
- I PE dell’ES dove è “approdato” il MAC, ne annuncino la presenza, tramite annunci BGP EVPN di tipo MAC/IP Advertisement.
- Tutti gli annunci BGP EVPN di tipo MAC/IP Advertisement inviati dal o dai PE da dove era raggiungibile in precedenza l’indirizzo MAC, devono essere eliminati da tutti gli altri PE della EVI.
Per gestire correttamente situazioni transitorie che si potrebbero verificare a causa di rapidi e continui spostamenti di un indirizzo MAC tra due o più ES, negli annunci BGP EVPN di tipo MAC/IP Advertisement viene aggiunto l’attributo MAC Mobility Extended Community. Questo attributo contiene un numero di sequenza, che viene incrementato di una unità ogniqualvolta un PE invia un annuncio BGP EVPN di tipo MAC/IP Advertisement (NOTA: in realtà nel primo annuncio l’attributo non viene inserito, e ciò corrisponde di default a un numero di sequenza nullo). Quando un PE riceve un annuncio di tipo MAC/IP Advertisement con numero di sequenza più elevato di quello già in memoria, sostituisce quello presente in memoria con quello ricevuto con il numero di sequenza maggiore.
La figura seguente mostra un esempio di utilizzo dell’attributo MAC Mobility Extended Community. Nella figura si ipotizza che l’indirizzo MAC-1 si sia già mosso una volta da Ovest verso Est e che sia ritornato ad Ovest. PE1-1, una volta appreso di nuovo l’indirizzo MAC-1 (via MAC learning sul piano dati o di controllo), invia a tutti i PE della stessa EVI un annuncio MAC/IP Advertisement con l’attributo MAC Mobility Extended Community avente il numero di sequenza posto a 2.
La figura seguente mostra invece cosa avviene dopo un nuovo spostamento dell’indirizzo MAC-1 da Ovest verso Est (fase 1 nella figura). Il router PE2-1, una volta accortosi (sempre via MAC learning sul piano dati o di controllo) della presenza di MAC-1 sul proprio ES, genera un nuovo annuncio di tipo MAC/IP Advertisement con numero di sequenza 3 (ossia, uno in più del valore del numero di sequenza ricevuto), che viene inviato a tutti i PE dell’EVI (fase 2 nella figura). Quando PE1-1 riceve questo nuovo annuncio con numero di sequenza maggiore, esegue due operazioni:
- Sostituisce l’annuncio corrente dell’indirizzo MAC con quello più aggiornato (numero di sequenza maggiore).
- Ritira l’annuncio inviato in precedenza con numero di sequenza 2 (fase 3 nella figura).
CONCLUSIONI
In questo post ho illustrato molti dettagli di funzionamento del modello EVPN introdotto in un post precedente. Finora però mi sono limitato a trattare gli aspetti legati al Livello 2, ossia di annuncio degli indirizzi MAC, del trasporto del traffico BUM e unicast noto, della mobilità degli indirizzi MAC, oltre che alle problematiche della gestione dei collegamenti multi-homed e le soluzioni ai problemi principali.
Il modello EVPN ha però un’altra formidabile freccia nel suo arco, l’integrazione con il Livello 3 (questo grazie alla possibilità offerta dagli annunci BGP EVPN di tipo MAC/IP Advertisement, di trasportare anche informazioni su un indirizzo IP associato all’indirizzo MAC). E questo è uno degli aspetti più interessanti del modello EVPN che tratterò nei post successivi.
Ricordo infine quanto detto nelle conclusioni del post precedente sul modello EVPN, questo non sta solo nelle slide, nei documenti IETF o nelle chiacchiere del sottoscritto, ma è già implementato in varie piattaforme commerciali (es. Cisco ASR 9k, Nexus 7k/9k, Juniper MX/EX, Alcatel-Lucent 7750 SR).
Coming up next... EVPN come piano di controllo per le VXLAN.
Pubblicato in
ReissBlog
Etichettato sotto
Lunedì, 23 Novembre 2015 09:42
LIBRO "IS-IS:DALLA TEORIA ALLA PRATICA" : CAP. 9 + NUOVO INDICE
In questo post, il Capitolo 9 del libro su "IS-IS : dalla teoria alla pratica", che illustra gli aspetti di scalabilità, stabilità e sicurezza del protocollo.
Di tutte le funzionalità introdotte, saranno illustrate le configurazioni sia nelle piattaforme Cisco con IOS, IOS XE e IOS XR, che nelle piattaforme Juniper.
A grandi linee, il capitolo tratta:
- I principi generali che consentono una corretta partizione del dominio IS-IS in aree.
- I concetti base, gli scenari di applicazione e l’implementazione della sincronizzazione IS-IS/BGP e IS-IS/LDP.
- I concetti base, gli scenari di applicazione e l’implementazione della funzionalità Graceful Restart.
- Le procedure per l’autenticazione delle PDU IS-IS e la loro implementazione.
Nel frattempo il libro è cresciuto, ho aggiunto un nuovo capitolo. O meglio, ho diviso il capitolo 9 originario in due capitoli, lasciando per il Capitolo 10 tutta la parte sul Tuning della Convergenza (nella quale ho aggiunto molta roba rispetto al piano originale, tra cui la funzionalità LFA !). Per questo, il file .zip allegato contiene, oltre al Capitolo 9, anche il nuovo indice.
Buona lettura !!!
Coming up next ... considerata la buona accoglienza del primo post, in arrivo un post di approfondimento sul modello EVPN (che non sarà l'ultimo ...).
Pubblicato in
ReissBlog
Etichettato sotto
Sabato, 14 Novembre 2015 07:41
EVPN: L’EVOLUZIONE DEL SERVIZIO VPLS – PARTE I
Nel post precedente sul modello EVPN ho illustrato i concetti e le idee fondamentali, focalizzando l’attenzione soprattutto alle problematiche legate alla gestione dei collegamenti multi-homed e alle loro (eleganti) soluzioni. Ho tralasciato molti dettagli di funzionamento, che in questo post cercherò almeno in parte di colmare.
In particolare, illustrerò quali sono i nuovi BGP NLRI dell’address-family EVPN (AFI/SAFI = 25/70), e le nuove extended community introdotte. Poi farò vedere come viene eletto il Designated Forwarder e come viene trasportato il traffico, sia BUM che unicast. Infine illustrerò i principi generali del MAC mobility, ossia la possibilità che un indirizzo MAC si muova da un segmento Ethernet a un altro. Vi preannuncio che comunque le cose da dire sono ancora molte, per cui aspettatevi altri post sull’argomento.
DETERMINAZIONE DELL’ESI
Nel post precedente ho illustrato il ruolo fondamentale giocato dall’ESI (Ethernet Segment Identifier) nei collegamenti multi-homed. Ricordo che l’ESI è un identificativo dell’ES (Ethernet Segment), e come tale deve essere univoco all’interno della rete (non dell’istanza EVPN (EVI) !).
La RFC 7432 ha specificato per l’ESI una lunghezza di 10 byte, con un formato molto semplice riportato nella figura seguente (tratta direttamente dalla RFC 7432).
Il campo T identifica come può essere determinato dell’ESI. La RFC 7432 prevede una determinazione manuale, via configurazione, o una determinazione automatica.
Per valori di ESI configurati manualmente, T = 0x00. Per valori di ESI determinati automaticamente la RFC 7432 ha identificato ben 5 modalità diverse, identificate da T = 0x01, ..., T = 0x05. Non starò qui a illustrare tutte le 5 possibilità, farò solo vedere la prima, lasciando al lettore di “esplorare” le altre nella RFC 7432. Ma, faccio notare, non è un argomento di vitale importanza. Tanto, un ESI vale l’altro, purché sia verificata l’univocità su tutta la rete.
Quando T = 0x01, è previsto che i CE utilizzino nei loro collegamenti verso i PE, lo standard IEEE 802.1AX (LAG con LACP). Questo tipo di ESI indica un valore auto-generato, in cui i restanti 9 byte dell’ESI sono determinati dai parametri del protocollo LACP e così suddivisi (partendo dai byte più significativi):
Si noti che i due seguenti valori di ESI sono riservati:
SERVIZI EVPN E ETHERNET TAG
Nel post precedente ho introdotto, ma solo come terminologia, il concetto di Ethernet tag. Ricordo che l’Ethernet tag è un identificativo di un dominio broadcast (es. una VLAN). Una EVI consiste di uno o più domini broadcast. I valori di Ethernet tag assegnati ai domini broadcast di una data EVI, sono determinati dal tipo di servizio e assegnati dal service provider. L’Ethernet tag ha lunghezza di 32 bit, dei quali vengono utilizzati 12 o 24 bit. Nel caso in cui l’identificativo sia di 12 bit, l’Ethernet tag viene anche chiamato VLAN ID (VID) e coincide con i classici valori di VLAN ID. I valori di Ethernet tag sono utilizzati solo negli annunci BGP EVPN.
Una EVI è costituita da uno o più domini di broadcast (VLAN). Una data VLAN può a sua volta essere rappresentata da più VID (su diversi PE). In tali casi, i PE che partecipano a quella VLAN per una determinata EVI, sono responsabili della traduzione dei VID da/verso i CE collegati localmente. Se una VLAN è rappresentata da un singolo VID su tutti i PE che partecipano a quella VLAN, per quella determinata EVI, allora viene meno la necessità della traduzione dei VID da parte dei PE.
Un problema interessante a questo punto è il seguente: quale è la relazione tra i domini di broadcast (identificati ad esempio da VID), l’Ethernet tag e le MAC-VRF di ciascuna EVI ? In altre parole, quando un PE riceve un annuncio BGP EVPN contenente un dato valore di Ethernet tag, a fronte di questo annuncio il PE deve stabilire una relazione tra il valore dei VID lato CE e le EVI. Il tipo di relazione dipende dal tipo di servizio EVPN. Bene, il modello EVPN ha tre tipi di servizi a questo riguardo, che specificano quale sia questa relazione (riporto i nomi così come appaiono nella RFC 7432) e di cui voglio dare una breve descrizione:
LA NUOVA ADDRESS-FAMILY BGP EVPN (AFI/SAFI = 25/70)
Come più volte detto, uno degli aspetti più innovativi del modello EVPN, è che il MAC learning remoto avviene sul piano di controllo, utilizzando annunci BGP. Per questo è stata definita una nuova address-family BGP, caratterizzata dai codici AFI/SAFI = 25/70.
Il formato generale della nuova EVPN NLRI è del classico tipo TLV (Type-Length-Value) ed è riportato nella figura seguente, dove il campo Route Type rappresenta il tipo di codifica presente nel campo Route Type Specific, il campo Length la lunghezza in byte del campo successivo, e infine il campo Route Type Specific la codifica vera e propria del NLRI.
La RFC 7432 ha definito 4 tipi diversi di NLRI, riportati nella tabella seguente.
Del secondo tipo abbiamo dato ampiamente conto nel post precedente. Degli altri, finora non abbiamo mai parlato del terzo. Sarà trattato nella sezione sotto sul trasporto del traffico BUM.
Piuttosto che dare per ciascun tipo il formato e il significato dei vari campi, preferisco riassumere in una tabella i campi più importanti e soprattutto l’utilizzo (in parte già visto nel post precedente). I lettori più curiosi possono far riferimento alla RFC 7432 per il formato completo.
In tutti i tipi di NLRI è inoltre presente un valore di Route Distinguisher (RD), il cui formato e significato è identico a quello delle L3VPN, ossia è un valore che serve a distinguere eventuali NLRI identiche, ma generate da Clienti diversi. Si noti che la RFC 7432 impone per il RD il formato “IP-PE : valore”, dove “IP-PE” è un indirizzo IP del PE (tipicamente una interfaccia di Loopback) e “valore” è un numero arbitrario assegnato dall’amministratore del servizio.
LE NUOVE EXTENDED COMMUNITY
Il modello EVPN utilizza delle nuove BGP Extended Community, alcune delle quali già citate nel post precedente. Anche qui, piuttosto che dare per ciascuna nuova Extended Community il formato e il significato dei vari campi, preferisco riassumere in una tabella l’utilizzo (in parte già visto nel post precedente) e a quali EVPN NLRI vanno associate.
Su alcune di cui finora non abbiamo ancora visto l’utilizzo (ad esempio MAC mobility e Default Gateway), torneremo a tempo debito. Per ora è sufficiente sapere che esistono.
Oltre a queste nuove Extended Community, vi è poi il classico Route Target, utilizzato allo stesso modo e con le stesse identiche regole del servizio L3VPN e dell’auto-discovery via BGP nel servizio VPLS.
DETERMINAZIONE DEL DESIGNATED FORWARDER
Nel post precedente sul modello EVPN è stato evidenziato il ruolo chiave, nei collegamenti multi-homed, giocato dai Designated Forwarder (DF), che ricordiamo, sono quei PE multi-homed responsabili di inviare ai CE il traffico BUM. L’elezione di un DF è essenziale per risolvere problemi come ad esempio la duplicazione delle trame BUM e del ritorno del traffico BUM nei CE che lo hanno generato (Split Horizon).
L’elezione del DF avviene a valle della scoperta dei PE che sono multi-homed allo stesso ES. Per distribuire la funzione di DF tra i PE di un ES, la RFC 7432 definisce una procedura di default denominata service carving, che consente di eleggere un DF per ciascuna coppia <ES, VLAN> del caso dei servizi VLAN-based e per ciascuna coppia <ES, VLAN bundle> per i servizi VLAN bundle e VLAN-aware bundle. Con il metodo del service carving è quindi possibile l’elezione di più DF per ES, consentendo così di eseguire un Load Balancing per il traffico BUM destinato ai CE di un ES.
La procedura di service carving è basata sui seguenti passi:
Il servizio della EVI-1 è di tipo VLAN-based mentre il servizio della EVI-2 è di tipo VLAN bundle (o VLAN-aware bundle, fa lo stesso). Il primo passo da eseguire, a valle della scoperta da parte di un PE di quali sono gli altri PE multi-homed, è l’associazione del numero intero sequenziale. Poiché l’indirizzo 1.1.1.1 è (numericamente) più basso dell’indirizzo 2.2.2.2, il PE1 ha associato il valore 0 e il PE2 il valore 1. Per determinare il DF per la EVI-1, ossia per la coppia <ES, VID = 100>, si esegue l’operazione “100 mod 2”, che da come risultato 0 (ossia, il resto della divisione tra 100 e 2). Ne consegue che il PE1 è il DF per l’EVI-1 poiché ha associato il numero intero sequenziale 0. Per determinare il DF per l’EVI-2 si esegue la stessa operazione, prendendo come valore di riferimento per il VID il minimo tra tutti VID associati all’EVI-2, ossia 101 = min [101, 102, 103]. L’operazione “V mod N” = “101 mod 2” da come risultato 1, e quindi il DF per l’EVI-2 è il PE2. “Elementare Watson”, avrebbe detto Sherlock Holmes !
ETHERNET A-D PER ES E EHTERNET A-D PER EVI
Una volta che ciascun PE ha scoperto gli altri PE multi-homed allo stesso ES, attraverso gli annunci BGP EVPN di tipo Ethernet Segment (tipo 4) e il filtraggio attraverso l’ES-import, ed eletti i DF per ciascun ES, la fase successiva nella sequenza di startup del modello EVPN, è l’annuncio degli ES. Questa fase è fondamentale per risolvere i problemi del possibile ritorno delle trame BUM sul CE che le ha generate, della convergenza veloce e dell’aliasing.
L’annuncio degli ES avviene attraverso NLRI di tipo Ethernet A-D (tipo 1). Il modello EVPN utilizza due tipi di Ethernet A-D: Ethernet A-D per ES e Ethernet A-D per EVI.
L’Ethernet A-D per ES viene sempre annunciato da ciascun PE di un ES multi-homed e contiene come informazioni:
Gli annunci di tipo Ethernet A-D per ES vengono utilizzati per implementare il meccanismo dello Split Horizon e per la convergenza veloce. Per l’aliasing e il Backup Path, vengono utilizzati annunci sempre di tipo Ethernet A-D (quindi sempre di tipo 1), ma con una struttura diversa. Questi annunci, detti Ethernet A-D per EVI sono opzionali ma, almeno nelle implementazioni che ho visto finora, vengono comunque sempre inviati. In realtà nel caso di ESI = 0 (ossia, collegamenti single-homed), non sono necessari.
L’Ethernet A-D per EVI contiene come informazioni:
Quando un router PE “impara” da un CE multi-homed un indirizzo MAC, questo come più volte detto nel post precedente, invia un annuncio BGP EVPN del tipo MAC/IP Advertisement (tipo 2) che include l’indirizzo MAC, l’indirizzo IP associato (se noto), una etichetta MPLS e il valore di ESI che identifica l’ES da dove l’indirizzo MAC è stato appreso. Un PE remoto correla questo valore di ESI con quello presente nei due annunci Ethernet A-D (per ES e per EVI) e può così determinare l’insieme dei PE multi-homed, ai quali può trasmettere le trame Ethernet (incapsulate in qualche modo) dirette all’indirizzo MAC. Quando il PE remoto invia le trame Ethernet utilizzando come Next-Hop il PE che inviato l’annuncio di tipo MAC/IP Advertisement, incapsula le trame in un pacchetto MPLS utilizzando come etichetta interna (service label) l’etichetta associata all’annuncio MAC/IP Advertisement. Quando invece il PE remoto invia le trame Ethernet utilizzando come Next-Hop un PE che inviato gli annunci di tipo Ethernet A-D con il medesimo valore di ESI dell’annuncio MAC/IP Advertisement, utilizza l’aliasing label (a meno che il PE remoto non abbia ricevuto anche lui un MAC/IP Advertisement che annuncia lo stesso indirizzo MAC, nel qual caso utilizza anche lui la service label contenuta nell’annuncio).
TRASPORTO DEL TRAFFICO BUM
Nelle reti di Livello 2 il traffico BUM viene inoltrato attraverso un classico meccanismo di flooding, senza distinzione alcuna tra traffico multi-destinazione (multicast e broadcast) e traffico unicast ma diretto verso un indirizzo MAC sconosciuto.
Il modello EVPN introduce per la prima volta una distinzione tra traffico multi-destinazione (le lettere B e M dell’acronimo BUM) e il traffico diretto verso un indirizzo MAC sconosciuto (la lettera U dell’acronimo BUM). Infatti, mentre il traffico multi-destinazione segue il classico meccanismo del flooding, il traffico diretto verso un indirizzo MAC sconosciuto può seguire o no il classico meccanismo del flooding. La RFC 7432 a questo proposito è molto chiara. Nella sezione 12 “Processing of Unknown Unicast Packets”, così recita:
The procedures in this document do not require the PEs to flood unknown unicast traffic to other PEs. If PEs learn CE MAC addresses via a control-plane protocol, the PEs can then distribute MAC addresses via BGP, and all unicast MAC addresses will be learned prior to traffic to those destinations.
However, if a destination MAC address of a received packet is not known by the PE, the PE may have to flood the packet.
Traduciamo, per essere più chiari. La prima parte dice che la RFC 7432 non richiede tassativamente di utilizzare il meccanismo del flooding per le trame con MAC destinazione ignoto (NOTA: questo concetto non è nuovo nelle reti L2 ed è stato introdotto da Cisco nel suo protocollo OTV, Overlay Transport Virtualization, per l’interconnessione di Data Center). Poi dice che se i PE fossero in grado di “imparare” dai CE gli indirizzi MAC attraverso un meccanismo del piano di controllo (es. ARP/DHCP snooping, o qualche diavoleria tipo protocollo di routing che annunci gli indirizzi MAC raggiungibili dai CE), i PE possono distribuire la conoscenza degli indirizzi MAC (unicast) via BGP, prima che il traffico fluisca verso questi indirizzi MAC, ossia prima ancora che i MAC vengano appresi sul piano dati. Fermi tutti, ma questo non è lo stesso identico ragionamento che avviene a Livello 3, dove un PE “impara” dal piano di controllo via routing PE-CE (statico o dinamico) i prefissi raggiungibili dai CE, e quindi li annuncia agli altri PE via BGP ? Ebbene si, è esattamente lo stesso identico ragionamento. Allora vuol dire che tutti gli “esegeti” (NOTA: chiedo perdono per la forzatura nell'utilizzo di questa parola, che letteralmente significa "commentatore, interprete, critico di testi letterari, giuridici o sacri") delle reti Switched Ethernet, ossia tutti quelli che per anni ci hanno riempito la testa che le flat networks (basate sul flooding e non sui protocolli di routing) erano la soluzione di tutti i problemi del networking sono stati folgorati sulla via di Damasco e ci hanno ripensato ? Lascio a voi la conclusione.
La seconda parte dice che comunque in assenza di MAC learning PE-CE sul piano di controllo, i PE possono (= may) utilizzare il flooding. Si noti comunque che quanto detto riguarda solo il trasporto PE-PE. Il flooding a livello locale, ossia sulle interfacce lato CE, può comunque avvenire (e di solito avviene, lato CE il PE si comporta infatti come un classico L2 switch).
Bene, ciò premesso, come viene veicolato il traffico BUM nel modello EVPN ? A ben vedere, questo traffico origina da un particolare PE ed è diretto a tutti i PE della stessa EVI. Suona familiare ? Ebbene si, è lo stesso problema che si deve affrontare nel servizio L3VPN multicast o nell’inoltro del traffico BUM nelle VPLS. Per cui possono essere riciclate le stesse tecniche. I PE di una stessa EVI possono utilizzare come P-tunnel, LSP MPLS di tipo P2MP o MP2MP (trattati ampiamente in post precedenti) oppure Ingress Replication. La segnalazione di quale tipo di meccanismo utilizzare avviene attraverso annunci BGP EVPN del tipo Inclusive Multicast Ethernet Tag (tipo 3), i quali, oltre ai campi del NLRI (molto semplici, vedi la tabella sopra) contengono (obbligatoriamente) il nuovo attributo BGP PMSI Tunnel, esattamente identico a quello utilizzato nel modello NG-MVPN (vedi post precedente sull’argomento). Tra l’altro, lo stesso attributo è stato introdotto anche per il servizio VPLS che utilizza il BGP come protocollo di auto-discovery (vedi la recente RFC 7117, Multicast in Virtual Private LAN Service (VPLS)), per ottimizzare il flooding delle trame BUM.
Si noti che anche per il modello EVPN, per evitare loop interni del traffico, vale la regola dello Split Horizon utilizzata nel servizio VPLS, ossia che il traffico BUM ricevuto da un PE, non viene mai inoltrato agli altri PE della stessa EVI (NOTA: questa regola non ha niente a che vedere con la regola dello Split Horizon vista nel post precedente, tanto che la RFC 7432, per evitare confusione la indica come Split Horizon Forwarding).
Nel caso di P-tunnel di tipo Ingress Replication, ad oggi il metodo ancora preferito nelle implementazioni “primitive” del modello EVPN grazie alla sua semplicità, vengono utilizzati normali LSP MPLS di tipo P2P tra il PE di origine e tutti gli altri PE della stesa EVI. Le etichette MPLS da utilizzare vengono segnalate utilizzando il campo MPLS Label presente nell’attributo PMSI Tunnel. Queste etichette sono da considerarsi come downstream allocated, ossia devono essere utilizzate dal PE origine del traffico BUM come service label, per inviare il traffico BUM agli altri PE della stessa EVI. Per chiarire meglio concetto, illustrerò come avviene in questo caso la segnalazione e come avviene il trasporto del trasporto del traffico, ossia piano di controllo e piano dati.
La figura seguente illustra come avviene la segnalazione.
Per motivi di spazio ho evidenziato il solo annuncio EVPN generato da PE1-1. Ma ciascun PE di ciascuna istanza EVI, genera un annuncio simile. Come si può notare, l’annuncio contiene l’attributo PMSI Tunnel che definisce il tipo di P-tunnel da utilizzare (nell’esempio Ingress Replication) e ho evidenziato anche il valore di una etichetta MPLS (NOTA: il PMSI Tunnel contiene anche altri due campi, qui non evidenziati perché di minore importanza).
A questo punto vediamo il piano dati, illustrato nella figura seguente. Nella figura, le etichette segnalate dai router PEX-Y nel PMSI Tunnel sono indicate con LXY. Inoltre, nella figura compare anche la ESI-label annunciata da PE1-2 (= L12-SH) per lo Split Horizon.
Quando PE1-1 riceve una trama Ethernet con MAC destinazione BUM, replica la trama verso tutti i PE della stessa EVI (nella figura gli altri 3 PE). A ciascuna trama viene dapprima aggiunta, dove applicabile, la ESI-label (nella figura alla sola trama diretta verso PE1-2, poiché PE1-1 e PE1-2 fanno parte dello stesso ES e PE1-2 è il DF dell’ES), quindi la service label annunciata dai PE remoti attraverso l’attributo PMSI Tunnel e infine la PSN label, ossia l’etichetta MPLS per il trasporto PE-PE (indicata nella figura genericamente come PSN).
Qualora si utilizzino come P-tunnel i più efficienti LSP MPLS di tipo multipoint (P2MP o MP2MP), la segnalazione segue le logiche già viste nei post precedenti sui LSP MPLS di tipo multipoint. In questo caso l’etichetta MPLS presente nell’attributo PMSI Tunnel non viene utilizzata poiché la demultiplazione sui PE che ricevono il traffico, avviene sulla base dell’etichetta più esterna (per questo ricordo che in questa applicazione non è ammesso il Penultimate Hop Popping). Solo nel caso di aggregazione di più EVI su un singolo P-tunnel, allora viene utilizzata l’etichetta presente nell’attributo PMSI Tunnel per demultiplare a valle l’appartenenza alla particolare EVI all’interno del (singolo) P-tunnel (e il il Penultimate Hop Popping è ammesso). L’ etichetta annunciata nell’attributo PMSI Tunnel è da considerarsi in questo caso come upstream allocated, ossia segnalata e utilizzata dai PE che originano il traffico.
Come quasi sempre accade nel mondo delle tecnologie (non solo quelle del networking !) vi è sempre un compromesso nell’utilizzo di metodi differenti. Nel caso del trasporto del traffico BUM, la scelta del tipo di P-tunnel non si sottrae a questa regola. Infatti, l’utilizzo di LSP MPLS di tipo multipoint, se da un lato ottimizzano l’uso della banda (replica dei pacchetti MPLS solo nei punti di diramazione degli alberi utilizzati), dall’altro hanno lo svantaggio di richiedere degli stati aggiuntivi sui router interni alla rete IP/MPLS (router P), per la replica dei pacchetti sui punti di diramazione. E questo aspetto potrebbe creare problemi di scalabilità considerato l’elevato numero di LSP MPLS multipoint che potrebbero essere necessari (senza aggregazione,uno per EVI). Questo non accade nel caso di Ingress Replication, dove non sono necessari stati aggiuntivi perché non esistono punti di diramazione. Per contro lo svantaggio è che la replica dei pacchetti MPLS avviene a partire dal PE di ingresso, con conseguente spreco di banda.
TRASPORTO DEL TRAFFICO UNICAST
Gli aspetti fondamentali sulla segnalazione di indirizzi MAC unicast via annunci BGP EVPN sono già stati trattati, ma voglio in questa sezione, per maggiore chiarezza, fare un riepilogo complessivo, sul quale poi innestare come avviene il trasporto del traffico unicast, quando gli indirizzi MAC sono già stati appresi.
Quando un router PE “impara” (sul piano dati o con qualche meccanismo del piano di controllo) un nuovo indirizzo MAC da un CE, sul suo attachment circuit (AC) associato a una particolare EVI, aggiunge alla sua MAC table locale (o MAC-VRF) un nuovo entry del tipo <MAC; AC>. Il PE crea quindi un annuncio BGP EVPN del tipo MAC/IP Advertisement (tipo 2), che invia (direttamente o, come più sovente accade, con l’ausilio di Route Reflector), a tutti gli altri PE della stessa EVI (NOTA: in realtà, a meno di non implementare meccanismi di BGP route-target filtering sui Route Reflector, l’annuncio viene ricevuto da tutti i PE, i quali mediante il classico filtraggio basato sui Route Target provvedono o meno ad accettarlo). Questo è essenzialmente il processo di MAC learning remoto via BGP, già descritto nel post precedente sul modello EVPN, che è la novità principale introdotta dal modello EVPN.
Come già descritto nell’ultima sezione del post precedente sul modello EVPN, gli annunci BGP EVPN di tipo MAC/IP Advertisement includono le seguenti informazioni:
Quando un PE inizialmente “impara” il solo indirizzo MAC, invia l’annuncio BGP EVPN di tipo MAC/IP Advertisement solo con queste informazioni. Qualora successivamente il PE “imparasse” con qualche “trucco” (es. ARP snooping) anche l’indirizzo IP associato all’indirizzo MAC e sul PE sia stata configurata una interfaccia IRB per la VLAN (interfaccia Integrated Routing and Bridging, spesso anche chiamata interfaccia VLAN), allora il PE invia un secondo annuncio MAC/IP Advertisement aggiungendo informazioni di livello 3 come l’indirizzo IP e il Default Gateway. Illustrerò nel prossimo post sul modello EVPN, i vantaggi che si ottengono dalla possibilità introdotta nel modello, di poter annunciare sia indirizzi MAC che indirizzi IP associati e Default Gateway.
Infine, per concludere questo breve “riassunto” del MAC learning sul piano di controllo, si noti che quando un indirizzo MAC scade (ebbene si, anche qui c’è il MAC aging !), l’entry corrispondente sulla MAC-VRF viene cancellato e l’indirizzo MAC ritirato attraverso un ritiro dell’annuncio BGP EVPN MAC/IP Advertisement inviato in precedenza. L’annuncio e il ritiro di un indirizzo MAC sono particolarmente importanti nel caso di MAC mobility, ossia quando un indirizzo MAC si muove da un ES a un altro. Illustrerò i principi che regolano la MAC mobility nella prossima sezione.
La figura seguente riassume quanto detto sulla segnalazione di un nuovo indirizzo MAC appreso da PE1-1 dal CE1 (indirizzo MAC-1). Ho anche evidenziato nella figura l’annuncio BGP EVPN di tipo Ethernet A-D per EVI, già visto sopra, e che ci servirà per capire meglio la funzionalità di aliasing sul piano dati.
La figura seguente riporta invece il piano dati. Nella figura sono evidenziate due trame Ethernet generate da Host attestati a CE2 e inviate da questo a PE2-1. Le due trame hanno identico MAC destinazione MAC-1, noto a PE2-1 attraverso l’annuncio MAC/IP Advertisement inviato da PE1-1. Nella propria MAC-VRF, PE2-1 ha come Next-Hop sia PE1-1 che PE1-2, quest’ultimo grazie all’annuncio BGP EVPN Ethernet A-D per EVI. PE2-1 ha così la possibilità di bilanciare il traffico tra i due Next-Hop. Quando sceglie di inoltrare una trama utilizzando come Next-Hop PE1-1, la incapsula con la service label annunciata da PE1-1 attraverso l’annuncio MAC/IP Advertisement mentre quando sceglie di inoltrare una trama utilizzando come Next-Hop PE1-2, la incapsula con l’aliasing label annunciata da PE1-2 attraverso l’annuncio Ethernet A-D per EVI. In entrambi i casi viene poi aggiunta come top label, la PSN label, ossia l’etichetta MPLS che consente di trasportare i pacchetti MPLS tra il PE d’ingresso (PE2-1) e i PE di uscita (PE1-1 e PE1-2). Per completare il quadro della situazione, manca un piccolo tassello, che comunque non riguarda il modello EVPN, ma è un aspetto generale del load balancing: con quale criterio PE2-1 sceglie il Next-Hop ? Bene, qui le possibilità sono molte, ci si può affidare semplicemente agli indirizzi MAC, oppure, se possibile, andare in profondità sul pacchetto trasportato. Ad esempio, se questo fosse un semplice pacchetto TCP/IP, come hash key per il load balancing si potrebbero utilizzare tutti o parte dei seguenti campi: indirizzo IP sorgente, indirizzo IP destinazione, porta TCP sorgente, porta TCP destinazione, ecc. .
MOBILITÀ DEGLI INDIRIZZI MAC(MAC MOBILITY)
Nelle applicazioni attuali nei moderni Data Center, è pratica comune muovere le macchine virtuali (VM, Virtual Machine) da un segmento Ethernet a un altro. Questo comporta che un indirizzo MAC annunciato in precedenza da un PE, venga anche annunciato dal (o dai) PE del nuovo segmento Ethernet. Se non gestito correttamente, questo processo può portare a perdita di traffico, qualora trame Ethernet dirette all’indirizzo MAC che ha cambiato ES, vengano instradate verso il PE “vecchio”.
Per permettere a tutti i PE di una stessa EVI di “localizzare” correttamente gli indirizzi MAC “in movimento”, deve accadere che:
Per gestire correttamente situazioni transitorie che si potrebbero verificare a causa di rapidi e continui spostamenti di un indirizzo MAC tra due o più ES, negli annunci BGP EVPN di tipo MAC/IP Advertisement viene aggiunto l’attributo MAC Mobility Extended Community. Questo attributo contiene un numero di sequenza, che viene incrementato di una unità ogniqualvolta un PE invia un annuncio BGP EVPN di tipo MAC/IP Advertisement (NOTA: in realtà nel primo annuncio l’attributo non viene inserito, e ciò corrisponde di default a un numero di sequenza nullo). Quando un PE riceve un annuncio di tipo MAC/IP Advertisement con numero di sequenza più elevato di quello già in memoria, sostituisce quello presente in memoria con quello ricevuto con il numero di sequenza maggiore.
La figura seguente mostra un esempio di utilizzo dell’attributo MAC Mobility Extended Community. Nella figura si ipotizza che l’indirizzo MAC-1 si sia già mosso una volta da Ovest verso Est e che sia ritornato ad Ovest. PE1-1, una volta appreso di nuovo l’indirizzo MAC-1 (via MAC learning sul piano dati o di controllo), invia a tutti i PE della stessa EVI un annuncio MAC/IP Advertisement con l’attributo MAC Mobility Extended Community avente il numero di sequenza posto a 2.
La figura seguente mostra invece cosa avviene dopo un nuovo spostamento dell’indirizzo MAC-1 da Ovest verso Est (fase 1 nella figura). Il router PE2-1, una volta accortosi (sempre via MAC learning sul piano dati o di controllo) della presenza di MAC-1 sul proprio ES, genera un nuovo annuncio di tipo MAC/IP Advertisement con numero di sequenza 3 (ossia, uno in più del valore del numero di sequenza ricevuto), che viene inviato a tutti i PE dell’EVI (fase 2 nella figura). Quando PE1-1 riceve questo nuovo annuncio con numero di sequenza maggiore, esegue due operazioni:
CONCLUSIONI
In questo post ho illustrato molti dettagli di funzionamento del modello EVPN introdotto in un post precedente. Finora però mi sono limitato a trattare gli aspetti legati al Livello 2, ossia di annuncio degli indirizzi MAC, del trasporto del traffico BUM e unicast noto, della mobilità degli indirizzi MAC, oltre che alle problematiche della gestione dei collegamenti multi-homed e le soluzioni ai problemi principali.
Il modello EVPN ha però un’altra formidabile freccia nel suo arco, l’integrazione con il Livello 3 (questo grazie alla possibilità offerta dagli annunci BGP EVPN di tipo MAC/IP Advertisement, di trasportare anche informazioni su un indirizzo IP associato all’indirizzo MAC). E questo è uno degli aspetti più interessanti del modello EVPN che tratterò nei post successivi.
Ricordo infine quanto detto nelle conclusioni del post precedente sul modello EVPN, questo non sta solo nelle slide, nei documenti IETF o nelle chiacchiere del sottoscritto, ma è già implementato in varie piattaforme commerciali (es. Cisco ASR 9k, Nexus 7k/9k, Juniper MX/EX, Alcatel-Lucent 7750 SR).
Coming up next... EVPN come piano di controllo per le VXLAN.
In particolare, illustrerò quali sono i nuovi BGP NLRI dell’address-family EVPN (AFI/SAFI = 25/70), e le nuove extended community introdotte. Poi farò vedere come viene eletto il Designated Forwarder e come viene trasportato il traffico, sia BUM che unicast. Infine illustrerò i principi generali del MAC mobility, ossia la possibilità che un indirizzo MAC si muova da un segmento Ethernet a un altro. Vi preannuncio che comunque le cose da dire sono ancora molte, per cui aspettatevi altri post sull’argomento.
DETERMINAZIONE DELL’ESI
Nel post precedente ho illustrato il ruolo fondamentale giocato dall’ESI (Ethernet Segment Identifier) nei collegamenti multi-homed. Ricordo che l’ESI è un identificativo dell’ES (Ethernet Segment), e come tale deve essere univoco all’interno della rete (non dell’istanza EVPN (EVI) !).
La RFC 7432 ha specificato per l’ESI una lunghezza di 10 byte, con un formato molto semplice riportato nella figura seguente (tratta direttamente dalla RFC 7432).
Il campo T identifica come può essere determinato dell’ESI. La RFC 7432 prevede una determinazione manuale, via configurazione, o una determinazione automatica.
Per valori di ESI configurati manualmente, T = 0x00. Per valori di ESI determinati automaticamente la RFC 7432 ha identificato ben 5 modalità diverse, identificate da T = 0x01, ..., T = 0x05. Non starò qui a illustrare tutte le 5 possibilità, farò solo vedere la prima, lasciando al lettore di “esplorare” le altre nella RFC 7432. Ma, faccio notare, non è un argomento di vitale importanza. Tanto, un ESI vale l’altro, purché sia verificata l’univocità su tutta la rete.
Quando T = 0x01, è previsto che i CE utilizzino nei loro collegamenti verso i PE, lo standard IEEE 802.1AX (LAG con LACP). Questo tipo di ESI indica un valore auto-generato, in cui i restanti 9 byte dell’ESI sono determinati dai parametri del protocollo LACP e così suddivisi (partendo dai byte più significativi):
- CE LACP System MAC address (6 byte).
- CE LACP Port Key (2 byte).
- Ultimo byte = 0x00.
Si noti che i due seguenti valori di ESI sono riservati:
- ESI = 0 : valore riservato ai collegamenti single-homed.
- ESI = 0xFF (ripetuto 10 volte) : valore definito nella RFC 7432 come MAX-ESI.
SERVIZI EVPN E ETHERNET TAG
Nel post precedente ho introdotto, ma solo come terminologia, il concetto di Ethernet tag. Ricordo che l’Ethernet tag è un identificativo di un dominio broadcast (es. una VLAN). Una EVI consiste di uno o più domini broadcast. I valori di Ethernet tag assegnati ai domini broadcast di una data EVI, sono determinati dal tipo di servizio e assegnati dal service provider. L’Ethernet tag ha lunghezza di 32 bit, dei quali vengono utilizzati 12 o 24 bit. Nel caso in cui l’identificativo sia di 12 bit, l’Ethernet tag viene anche chiamato VLAN ID (VID) e coincide con i classici valori di VLAN ID. I valori di Ethernet tag sono utilizzati solo negli annunci BGP EVPN.
Una EVI è costituita da uno o più domini di broadcast (VLAN). Una data VLAN può a sua volta essere rappresentata da più VID (su diversi PE). In tali casi, i PE che partecipano a quella VLAN per una determinata EVI, sono responsabili della traduzione dei VID da/verso i CE collegati localmente. Se una VLAN è rappresentata da un singolo VID su tutti i PE che partecipano a quella VLAN, per quella determinata EVI, allora viene meno la necessità della traduzione dei VID da parte dei PE.
Un problema interessante a questo punto è il seguente: quale è la relazione tra i domini di broadcast (identificati ad esempio da VID), l’Ethernet tag e le MAC-VRF di ciascuna EVI ? In altre parole, quando un PE riceve un annuncio BGP EVPN contenente un dato valore di Ethernet tag, a fronte di questo annuncio il PE deve stabilire una relazione tra il valore dei VID lato CE e le EVI. Il tipo di relazione dipende dal tipo di servizio EVPN. Bene, il modello EVPN ha tre tipi di servizi a questo riguardo, che specificano quale sia questa relazione (riporto i nomi così come appaiono nella RFC 7432) e di cui voglio dare una breve descrizione:
- VLAN-based Service Interface: in questo servizio, vi è una coincidenza 1:1 tra EVI e domini broadcast (VLAN). Le MAC-VRF di ciascuna EVI hanno quindi una singola tabella di bridging corrispondente a quella determinata VLAN. Se la VLAN è rappresentata da più VID (ad esempio, un VID diverso per ogni segmento Ethernet per PE), ogni PE ha bisogno di eseguire la traduzione tra i VID (VLAN rewrite) utilizzati per le trame destinate ai suoi Ethernet Segment. Il valore di Ethernet tag presente nei vari annunci BGP EVPN, per questo servizio, viene impostato a 0.
- VLAN Bundle Service Interface: in questo servizio, a ogni EVI sono associati più domini broadcast. Le MAC-VRF di ciascuna EVI hanno comunque una unica tabella di bridging corrispondente a tutte le VLAN che identificano i domini di broadcast. Ciò implica che gli indirizzi MAC devono essere univoci in tutte le VLAN per quella EVI. In questo servizio ogni VLAN è rappresentata da un VID univoco, ciò significa che la traduzione di VID non è ammessa. Anche per questo servizio, il valore di Ethernet tag presente nei vari annunci BGP EVPN viene impostato a 0. Un caso particolare di questo servizio è il Port-based Service Interface, dove tutte le VLAN definite su una particolare porta, sono parte della medesima EVI.
- VLAN-aware Bundle Service Interface: come il servizio precedente, a ogni EVI sono associati più domini broadcast. La differenza è però che le MAC-VRF di ciascuna EVI hanno più tabelle di bridging , una per ciascuna VLAN (ed è quindi possibile la sovrapposizione di indirizzi MAC tra le VLAN). Il traffico BUM viene inviato in questo caso ai soli CE di un determinato dominio broadcast. I VID per ciascuna VLAN possono essere identici su tutti i PE o possono essere diversi. In quest’ultimo caso è necessario implementare sui PE una funzione di VLAN rewrite. Per questo servizio, il valore di Ethernet tag presente nei vari annunci BGP EVPN viene impostato dal service provider. Come nel servizio precedente, un caso particolare di questo servizio è il Port-Based VLAN-aware Service Interface, dove tutte le VLAN definite su una particolare porta sono parte della medesima EVI, ma ciascuna VLAN ha la sua unica tabella di bridging.
LA NUOVA ADDRESS-FAMILY BGP EVPN (AFI/SAFI = 25/70)
Come più volte detto, uno degli aspetti più innovativi del modello EVPN, è che il MAC learning remoto avviene sul piano di controllo, utilizzando annunci BGP. Per questo è stata definita una nuova address-family BGP, caratterizzata dai codici AFI/SAFI = 25/70.
Il formato generale della nuova EVPN NLRI è del classico tipo TLV (Type-Length-Value) ed è riportato nella figura seguente, dove il campo Route Type rappresenta il tipo di codifica presente nel campo Route Type Specific, il campo Length la lunghezza in byte del campo successivo, e infine il campo Route Type Specific la codifica vera e propria del NLRI.
La RFC 7432 ha definito 4 tipi diversi di NLRI, riportati nella tabella seguente.
Del secondo tipo abbiamo dato ampiamente conto nel post precedente. Degli altri, finora non abbiamo mai parlato del terzo. Sarà trattato nella sezione sotto sul trasporto del traffico BUM.
Piuttosto che dare per ciascun tipo il formato e il significato dei vari campi, preferisco riassumere in una tabella i campi più importanti e soprattutto l’utilizzo (in parte già visto nel post precedente). I lettori più curiosi possono far riferimento alla RFC 7432 per il formato completo.
In tutti i tipi di NLRI è inoltre presente un valore di Route Distinguisher (RD), il cui formato e significato è identico a quello delle L3VPN, ossia è un valore che serve a distinguere eventuali NLRI identiche, ma generate da Clienti diversi. Si noti che la RFC 7432 impone per il RD il formato “IP-PE : valore”, dove “IP-PE” è un indirizzo IP del PE (tipicamente una interfaccia di Loopback) e “valore” è un numero arbitrario assegnato dall’amministratore del servizio.
LE NUOVE EXTENDED COMMUNITY
Il modello EVPN utilizza delle nuove BGP Extended Community, alcune delle quali già citate nel post precedente. Anche qui, piuttosto che dare per ciascuna nuova Extended Community il formato e il significato dei vari campi, preferisco riassumere in una tabella l’utilizzo (in parte già visto nel post precedente) e a quali EVPN NLRI vanno associate.
Su alcune di cui finora non abbiamo ancora visto l’utilizzo (ad esempio MAC mobility e Default Gateway), torneremo a tempo debito. Per ora è sufficiente sapere che esistono.
Oltre a queste nuove Extended Community, vi è poi il classico Route Target, utilizzato allo stesso modo e con le stesse identiche regole del servizio L3VPN e dell’auto-discovery via BGP nel servizio VPLS.
DETERMINAZIONE DEL DESIGNATED FORWARDER
Nel post precedente sul modello EVPN è stato evidenziato il ruolo chiave, nei collegamenti multi-homed, giocato dai Designated Forwarder (DF), che ricordiamo, sono quei PE multi-homed responsabili di inviare ai CE il traffico BUM. L’elezione di un DF è essenziale per risolvere problemi come ad esempio la duplicazione delle trame BUM e del ritorno del traffico BUM nei CE che lo hanno generato (Split Horizon).
L’elezione del DF avviene a valle della scoperta dei PE che sono multi-homed allo stesso ES. Per distribuire la funzione di DF tra i PE di un ES, la RFC 7432 definisce una procedura di default denominata service carving, che consente di eleggere un DF per ciascuna coppia <ES, VLAN> del caso dei servizi VLAN-based e per ciascuna coppia <ES, VLAN bundle> per i servizi VLAN bundle e VLAN-aware bundle. Con il metodo del service carving è quindi possibile l’elezione di più DF per ES, consentendo così di eseguire un Load Balancing per il traffico BUM destinato ai CE di un ES.
La procedura di service carving è basata sui seguenti passi:
- Quando un PE multi-homed scopre (via configurazione manuale o attraverso un qualche meccanismo di auto sensing tipo quello descritto sopra nella sezione “Determinazione dell’ESI”, basato sui parametri del protocollo LACP) il valore di ESI dell’ES a cui è (fisicamente) connesso, invia un annuncio BGP EVPN con NLRI di tipo Ethernet Segment (tipo 4), con associata una ES-import Extended Community. Il valore di ES-import è costituito da 6 dei 9 byte utili dell’ESI.
- Il PE fa quindi partire un timer, la cui durata è di 3 sec (default), per consentire la ricezione degli annunci BGP EVPN con NLRI di tipo Ethernet Segment da parte degli altri PE multi-homed allo stesso ES. Questo timer è identico per tutti i altri PE multi-homed allo stesso ES.
- Allo scadere del timer, ciascun PE crea una lista ordinata in senso crescente, degli indirizzi IP contenuti negli annunci di tipo Ethernet Segment (incluso il proprio) nel campo Originating Router’s IP address (tipicamente una interfaccia di Loopback).
- Nel caso di servizi VLAN-based il DF è il PE che ha il numero definito dall’operazione “V mod N”, dove V è il VID (NOTA: ricordo a chi non è avvezzo alle notazioni matematiche, che l’operazione “V mod N” corrisponde al banale resto della divisione tra V ed N; ad esempio “11 mod 3” = 2, “14 mod 2” = 0, ecc.).
- Nel caso invece di servizi VLAN bundle e VLAN-aware bundle, dove a ciascuna EVI corrispondono più VID, l’operazione da eseguire è identica, prendendo come valore di V il minimo VID.
Il servizio della EVI-1 è di tipo VLAN-based mentre il servizio della EVI-2 è di tipo VLAN bundle (o VLAN-aware bundle, fa lo stesso). Il primo passo da eseguire, a valle della scoperta da parte di un PE di quali sono gli altri PE multi-homed, è l’associazione del numero intero sequenziale. Poiché l’indirizzo 1.1.1.1 è (numericamente) più basso dell’indirizzo 2.2.2.2, il PE1 ha associato il valore 0 e il PE2 il valore 1. Per determinare il DF per la EVI-1, ossia per la coppia <ES, VID = 100>, si esegue l’operazione “100 mod 2”, che da come risultato 0 (ossia, il resto della divisione tra 100 e 2). Ne consegue che il PE1 è il DF per l’EVI-1 poiché ha associato il numero intero sequenziale 0. Per determinare il DF per l’EVI-2 si esegue la stessa operazione, prendendo come valore di riferimento per il VID il minimo tra tutti VID associati all’EVI-2, ossia 101 = min [101, 102, 103]. L’operazione “V mod N” = “101 mod 2” da come risultato 1, e quindi il DF per l’EVI-2 è il PE2. “Elementare Watson”, avrebbe detto Sherlock Holmes !
ETHERNET A-D PER ES E EHTERNET A-D PER EVI
Una volta che ciascun PE ha scoperto gli altri PE multi-homed allo stesso ES, attraverso gli annunci BGP EVPN di tipo Ethernet Segment (tipo 4) e il filtraggio attraverso l’ES-import, ed eletti i DF per ciascun ES, la fase successiva nella sequenza di startup del modello EVPN, è l’annuncio degli ES. Questa fase è fondamentale per risolvere i problemi del possibile ritorno delle trame BUM sul CE che le ha generate, della convergenza veloce e dell’aliasing.
L’annuncio degli ES avviene attraverso NLRI di tipo Ethernet A-D (tipo 1). Il modello EVPN utilizza due tipi di Ethernet A-D: Ethernet A-D per ES e Ethernet A-D per EVI.
L’Ethernet A-D per ES viene sempre annunciato da ciascun PE di un ES multi-homed e contiene come informazioni:
- Il valore dell’ESI.
- La ESI-label Extended Community utilizzata nel meccanismo dello Split Horizon, che, ricordo dal precedente post, consente di evitare il possibile ritorno delle trame BUM sul CE che le ha generate. Questa Extended Community contiene anche la flag che definisce la modalità di funzionamento dell’ES: flag = 0 se la modalità è active-active, flag = 1 se la modalità è single-active.
- Uno o più Route Target, per tutte le EVI alle quali appartiene l’ES.
Gli annunci di tipo Ethernet A-D per ES vengono utilizzati per implementare il meccanismo dello Split Horizon e per la convergenza veloce. Per l’aliasing e il Backup Path, vengono utilizzati annunci sempre di tipo Ethernet A-D (quindi sempre di tipo 1), ma con una struttura diversa. Questi annunci, detti Ethernet A-D per EVI sono opzionali ma, almeno nelle implementazioni che ho visto finora, vengono comunque sempre inviati. In realtà nel caso di ESI = 0 (ossia, collegamenti single-homed), non sono necessari.
L’Ethernet A-D per EVI contiene come informazioni:
- Il valore dell’ESI.
- Una etichetta MPLS utilizzata per l’aliasing (aliasing label). L’utilizzo di questa etichetta è stato specificato nel post precedente.
- Il Route Target dell’EVI.
Quando un router PE “impara” da un CE multi-homed un indirizzo MAC, questo come più volte detto nel post precedente, invia un annuncio BGP EVPN del tipo MAC/IP Advertisement (tipo 2) che include l’indirizzo MAC, l’indirizzo IP associato (se noto), una etichetta MPLS e il valore di ESI che identifica l’ES da dove l’indirizzo MAC è stato appreso. Un PE remoto correla questo valore di ESI con quello presente nei due annunci Ethernet A-D (per ES e per EVI) e può così determinare l’insieme dei PE multi-homed, ai quali può trasmettere le trame Ethernet (incapsulate in qualche modo) dirette all’indirizzo MAC. Quando il PE remoto invia le trame Ethernet utilizzando come Next-Hop il PE che inviato l’annuncio di tipo MAC/IP Advertisement, incapsula le trame in un pacchetto MPLS utilizzando come etichetta interna (service label) l’etichetta associata all’annuncio MAC/IP Advertisement. Quando invece il PE remoto invia le trame Ethernet utilizzando come Next-Hop un PE che inviato gli annunci di tipo Ethernet A-D con il medesimo valore di ESI dell’annuncio MAC/IP Advertisement, utilizza l’aliasing label (a meno che il PE remoto non abbia ricevuto anche lui un MAC/IP Advertisement che annuncia lo stesso indirizzo MAC, nel qual caso utilizza anche lui la service label contenuta nell’annuncio).
TRASPORTO DEL TRAFFICO BUM
Nelle reti di Livello 2 il traffico BUM viene inoltrato attraverso un classico meccanismo di flooding, senza distinzione alcuna tra traffico multi-destinazione (multicast e broadcast) e traffico unicast ma diretto verso un indirizzo MAC sconosciuto.
Il modello EVPN introduce per la prima volta una distinzione tra traffico multi-destinazione (le lettere B e M dell’acronimo BUM) e il traffico diretto verso un indirizzo MAC sconosciuto (la lettera U dell’acronimo BUM). Infatti, mentre il traffico multi-destinazione segue il classico meccanismo del flooding, il traffico diretto verso un indirizzo MAC sconosciuto può seguire o no il classico meccanismo del flooding. La RFC 7432 a questo proposito è molto chiara. Nella sezione 12 “Processing of Unknown Unicast Packets”, così recita:
The procedures in this document do not require the PEs to flood unknown unicast traffic to other PEs. If PEs learn CE MAC addresses via a control-plane protocol, the PEs can then distribute MAC addresses via BGP, and all unicast MAC addresses will be learned prior to traffic to those destinations.
However, if a destination MAC address of a received packet is not known by the PE, the PE may have to flood the packet.
Traduciamo, per essere più chiari. La prima parte dice che la RFC 7432 non richiede tassativamente di utilizzare il meccanismo del flooding per le trame con MAC destinazione ignoto (NOTA: questo concetto non è nuovo nelle reti L2 ed è stato introdotto da Cisco nel suo protocollo OTV, Overlay Transport Virtualization, per l’interconnessione di Data Center). Poi dice che se i PE fossero in grado di “imparare” dai CE gli indirizzi MAC attraverso un meccanismo del piano di controllo (es. ARP/DHCP snooping, o qualche diavoleria tipo protocollo di routing che annunci gli indirizzi MAC raggiungibili dai CE), i PE possono distribuire la conoscenza degli indirizzi MAC (unicast) via BGP, prima che il traffico fluisca verso questi indirizzi MAC, ossia prima ancora che i MAC vengano appresi sul piano dati. Fermi tutti, ma questo non è lo stesso identico ragionamento che avviene a Livello 3, dove un PE “impara” dal piano di controllo via routing PE-CE (statico o dinamico) i prefissi raggiungibili dai CE, e quindi li annuncia agli altri PE via BGP ? Ebbene si, è esattamente lo stesso identico ragionamento. Allora vuol dire che tutti gli “esegeti” (NOTA: chiedo perdono per la forzatura nell'utilizzo di questa parola, che letteralmente significa "commentatore, interprete, critico di testi letterari, giuridici o sacri") delle reti Switched Ethernet, ossia tutti quelli che per anni ci hanno riempito la testa che le flat networks (basate sul flooding e non sui protocolli di routing) erano la soluzione di tutti i problemi del networking sono stati folgorati sulla via di Damasco e ci hanno ripensato ? Lascio a voi la conclusione.
La seconda parte dice che comunque in assenza di MAC learning PE-CE sul piano di controllo, i PE possono (= may) utilizzare il flooding. Si noti comunque che quanto detto riguarda solo il trasporto PE-PE. Il flooding a livello locale, ossia sulle interfacce lato CE, può comunque avvenire (e di solito avviene, lato CE il PE si comporta infatti come un classico L2 switch).
Bene, ciò premesso, come viene veicolato il traffico BUM nel modello EVPN ? A ben vedere, questo traffico origina da un particolare PE ed è diretto a tutti i PE della stessa EVI. Suona familiare ? Ebbene si, è lo stesso problema che si deve affrontare nel servizio L3VPN multicast o nell’inoltro del traffico BUM nelle VPLS. Per cui possono essere riciclate le stesse tecniche. I PE di una stessa EVI possono utilizzare come P-tunnel, LSP MPLS di tipo P2MP o MP2MP (trattati ampiamente in post precedenti) oppure Ingress Replication. La segnalazione di quale tipo di meccanismo utilizzare avviene attraverso annunci BGP EVPN del tipo Inclusive Multicast Ethernet Tag (tipo 3), i quali, oltre ai campi del NLRI (molto semplici, vedi la tabella sopra) contengono (obbligatoriamente) il nuovo attributo BGP PMSI Tunnel, esattamente identico a quello utilizzato nel modello NG-MVPN (vedi post precedente sull’argomento). Tra l’altro, lo stesso attributo è stato introdotto anche per il servizio VPLS che utilizza il BGP come protocollo di auto-discovery (vedi la recente RFC 7117, Multicast in Virtual Private LAN Service (VPLS)), per ottimizzare il flooding delle trame BUM.
Si noti che anche per il modello EVPN, per evitare loop interni del traffico, vale la regola dello Split Horizon utilizzata nel servizio VPLS, ossia che il traffico BUM ricevuto da un PE, non viene mai inoltrato agli altri PE della stessa EVI (NOTA: questa regola non ha niente a che vedere con la regola dello Split Horizon vista nel post precedente, tanto che la RFC 7432, per evitare confusione la indica come Split Horizon Forwarding).
Nel caso di P-tunnel di tipo Ingress Replication, ad oggi il metodo ancora preferito nelle implementazioni “primitive” del modello EVPN grazie alla sua semplicità, vengono utilizzati normali LSP MPLS di tipo P2P tra il PE di origine e tutti gli altri PE della stesa EVI. Le etichette MPLS da utilizzare vengono segnalate utilizzando il campo MPLS Label presente nell’attributo PMSI Tunnel. Queste etichette sono da considerarsi come downstream allocated, ossia devono essere utilizzate dal PE origine del traffico BUM come service label, per inviare il traffico BUM agli altri PE della stessa EVI. Per chiarire meglio concetto, illustrerò come avviene in questo caso la segnalazione e come avviene il trasporto del trasporto del traffico, ossia piano di controllo e piano dati.
La figura seguente illustra come avviene la segnalazione.
Per motivi di spazio ho evidenziato il solo annuncio EVPN generato da PE1-1. Ma ciascun PE di ciascuna istanza EVI, genera un annuncio simile. Come si può notare, l’annuncio contiene l’attributo PMSI Tunnel che definisce il tipo di P-tunnel da utilizzare (nell’esempio Ingress Replication) e ho evidenziato anche il valore di una etichetta MPLS (NOTA: il PMSI Tunnel contiene anche altri due campi, qui non evidenziati perché di minore importanza).
A questo punto vediamo il piano dati, illustrato nella figura seguente. Nella figura, le etichette segnalate dai router PEX-Y nel PMSI Tunnel sono indicate con LXY. Inoltre, nella figura compare anche la ESI-label annunciata da PE1-2 (= L12-SH) per lo Split Horizon.
Quando PE1-1 riceve una trama Ethernet con MAC destinazione BUM, replica la trama verso tutti i PE della stessa EVI (nella figura gli altri 3 PE). A ciascuna trama viene dapprima aggiunta, dove applicabile, la ESI-label (nella figura alla sola trama diretta verso PE1-2, poiché PE1-1 e PE1-2 fanno parte dello stesso ES e PE1-2 è il DF dell’ES), quindi la service label annunciata dai PE remoti attraverso l’attributo PMSI Tunnel e infine la PSN label, ossia l’etichetta MPLS per il trasporto PE-PE (indicata nella figura genericamente come PSN).
Qualora si utilizzino come P-tunnel i più efficienti LSP MPLS di tipo multipoint (P2MP o MP2MP), la segnalazione segue le logiche già viste nei post precedenti sui LSP MPLS di tipo multipoint. In questo caso l’etichetta MPLS presente nell’attributo PMSI Tunnel non viene utilizzata poiché la demultiplazione sui PE che ricevono il traffico, avviene sulla base dell’etichetta più esterna (per questo ricordo che in questa applicazione non è ammesso il Penultimate Hop Popping). Solo nel caso di aggregazione di più EVI su un singolo P-tunnel, allora viene utilizzata l’etichetta presente nell’attributo PMSI Tunnel per demultiplare a valle l’appartenenza alla particolare EVI all’interno del (singolo) P-tunnel (e il il Penultimate Hop Popping è ammesso). L’ etichetta annunciata nell’attributo PMSI Tunnel è da considerarsi in questo caso come upstream allocated, ossia segnalata e utilizzata dai PE che originano il traffico.
Come quasi sempre accade nel mondo delle tecnologie (non solo quelle del networking !) vi è sempre un compromesso nell’utilizzo di metodi differenti. Nel caso del trasporto del traffico BUM, la scelta del tipo di P-tunnel non si sottrae a questa regola. Infatti, l’utilizzo di LSP MPLS di tipo multipoint, se da un lato ottimizzano l’uso della banda (replica dei pacchetti MPLS solo nei punti di diramazione degli alberi utilizzati), dall’altro hanno lo svantaggio di richiedere degli stati aggiuntivi sui router interni alla rete IP/MPLS (router P), per la replica dei pacchetti sui punti di diramazione. E questo aspetto potrebbe creare problemi di scalabilità considerato l’elevato numero di LSP MPLS multipoint che potrebbero essere necessari (senza aggregazione,uno per EVI). Questo non accade nel caso di Ingress Replication, dove non sono necessari stati aggiuntivi perché non esistono punti di diramazione. Per contro lo svantaggio è che la replica dei pacchetti MPLS avviene a partire dal PE di ingresso, con conseguente spreco di banda.
TRASPORTO DEL TRAFFICO UNICAST
Gli aspetti fondamentali sulla segnalazione di indirizzi MAC unicast via annunci BGP EVPN sono già stati trattati, ma voglio in questa sezione, per maggiore chiarezza, fare un riepilogo complessivo, sul quale poi innestare come avviene il trasporto del traffico unicast, quando gli indirizzi MAC sono già stati appresi.
Quando un router PE “impara” (sul piano dati o con qualche meccanismo del piano di controllo) un nuovo indirizzo MAC da un CE, sul suo attachment circuit (AC) associato a una particolare EVI, aggiunge alla sua MAC table locale (o MAC-VRF) un nuovo entry del tipo <MAC; AC>. Il PE crea quindi un annuncio BGP EVPN del tipo MAC/IP Advertisement (tipo 2), che invia (direttamente o, come più sovente accade, con l’ausilio di Route Reflector), a tutti gli altri PE della stessa EVI (NOTA: in realtà, a meno di non implementare meccanismi di BGP route-target filtering sui Route Reflector, l’annuncio viene ricevuto da tutti i PE, i quali mediante il classico filtraggio basato sui Route Target provvedono o meno ad accettarlo). Questo è essenzialmente il processo di MAC learning remoto via BGP, già descritto nel post precedente sul modello EVPN, che è la novità principale introdotta dal modello EVPN.
Come già descritto nell’ultima sezione del post precedente sul modello EVPN, gli annunci BGP EVPN di tipo MAC/IP Advertisement includono le seguenti informazioni:
- L’indirizzo MAC da annunciare.
- L’Ethernet Tag, o VLAN ID, al quale l’indirizzo MAC appartiene.
- L’ESI del segmento Ethernet dal quale l’indirizzo MAC è stato appreso (fondamentale per applicare l’aliasing).
- Una etichetta MPLS che svolge il ruolo di service label.
Quando un PE inizialmente “impara” il solo indirizzo MAC, invia l’annuncio BGP EVPN di tipo MAC/IP Advertisement solo con queste informazioni. Qualora successivamente il PE “imparasse” con qualche “trucco” (es. ARP snooping) anche l’indirizzo IP associato all’indirizzo MAC e sul PE sia stata configurata una interfaccia IRB per la VLAN (interfaccia Integrated Routing and Bridging, spesso anche chiamata interfaccia VLAN), allora il PE invia un secondo annuncio MAC/IP Advertisement aggiungendo informazioni di livello 3 come l’indirizzo IP e il Default Gateway. Illustrerò nel prossimo post sul modello EVPN, i vantaggi che si ottengono dalla possibilità introdotta nel modello, di poter annunciare sia indirizzi MAC che indirizzi IP associati e Default Gateway.
Infine, per concludere questo breve “riassunto” del MAC learning sul piano di controllo, si noti che quando un indirizzo MAC scade (ebbene si, anche qui c’è il MAC aging !), l’entry corrispondente sulla MAC-VRF viene cancellato e l’indirizzo MAC ritirato attraverso un ritiro dell’annuncio BGP EVPN MAC/IP Advertisement inviato in precedenza. L’annuncio e il ritiro di un indirizzo MAC sono particolarmente importanti nel caso di MAC mobility, ossia quando un indirizzo MAC si muove da un ES a un altro. Illustrerò i principi che regolano la MAC mobility nella prossima sezione.
La figura seguente riassume quanto detto sulla segnalazione di un nuovo indirizzo MAC appreso da PE1-1 dal CE1 (indirizzo MAC-1). Ho anche evidenziato nella figura l’annuncio BGP EVPN di tipo Ethernet A-D per EVI, già visto sopra, e che ci servirà per capire meglio la funzionalità di aliasing sul piano dati.
La figura seguente riporta invece il piano dati. Nella figura sono evidenziate due trame Ethernet generate da Host attestati a CE2 e inviate da questo a PE2-1. Le due trame hanno identico MAC destinazione MAC-1, noto a PE2-1 attraverso l’annuncio MAC/IP Advertisement inviato da PE1-1. Nella propria MAC-VRF, PE2-1 ha come Next-Hop sia PE1-1 che PE1-2, quest’ultimo grazie all’annuncio BGP EVPN Ethernet A-D per EVI. PE2-1 ha così la possibilità di bilanciare il traffico tra i due Next-Hop. Quando sceglie di inoltrare una trama utilizzando come Next-Hop PE1-1, la incapsula con la service label annunciata da PE1-1 attraverso l’annuncio MAC/IP Advertisement mentre quando sceglie di inoltrare una trama utilizzando come Next-Hop PE1-2, la incapsula con l’aliasing label annunciata da PE1-2 attraverso l’annuncio Ethernet A-D per EVI. In entrambi i casi viene poi aggiunta come top label, la PSN label, ossia l’etichetta MPLS che consente di trasportare i pacchetti MPLS tra il PE d’ingresso (PE2-1) e i PE di uscita (PE1-1 e PE1-2). Per completare il quadro della situazione, manca un piccolo tassello, che comunque non riguarda il modello EVPN, ma è un aspetto generale del load balancing: con quale criterio PE2-1 sceglie il Next-Hop ? Bene, qui le possibilità sono molte, ci si può affidare semplicemente agli indirizzi MAC, oppure, se possibile, andare in profondità sul pacchetto trasportato. Ad esempio, se questo fosse un semplice pacchetto TCP/IP, come hash key per il load balancing si potrebbero utilizzare tutti o parte dei seguenti campi: indirizzo IP sorgente, indirizzo IP destinazione, porta TCP sorgente, porta TCP destinazione, ecc. .
MOBILITÀ DEGLI INDIRIZZI MAC(MAC MOBILITY)
Nelle applicazioni attuali nei moderni Data Center, è pratica comune muovere le macchine virtuali (VM, Virtual Machine) da un segmento Ethernet a un altro. Questo comporta che un indirizzo MAC annunciato in precedenza da un PE, venga anche annunciato dal (o dai) PE del nuovo segmento Ethernet. Se non gestito correttamente, questo processo può portare a perdita di traffico, qualora trame Ethernet dirette all’indirizzo MAC che ha cambiato ES, vengano instradate verso il PE “vecchio”.
Per permettere a tutti i PE di una stessa EVI di “localizzare” correttamente gli indirizzi MAC “in movimento”, deve accadere che:
- I PE dell’ES dove è “approdato” il MAC, ne annuncino la presenza, tramite annunci BGP EVPN di tipo MAC/IP Advertisement.
- Tutti gli annunci BGP EVPN di tipo MAC/IP Advertisement inviati dal o dai PE da dove era raggiungibile in precedenza l’indirizzo MAC, devono essere eliminati da tutti gli altri PE della EVI.
Per gestire correttamente situazioni transitorie che si potrebbero verificare a causa di rapidi e continui spostamenti di un indirizzo MAC tra due o più ES, negli annunci BGP EVPN di tipo MAC/IP Advertisement viene aggiunto l’attributo MAC Mobility Extended Community. Questo attributo contiene un numero di sequenza, che viene incrementato di una unità ogniqualvolta un PE invia un annuncio BGP EVPN di tipo MAC/IP Advertisement (NOTA: in realtà nel primo annuncio l’attributo non viene inserito, e ciò corrisponde di default a un numero di sequenza nullo). Quando un PE riceve un annuncio di tipo MAC/IP Advertisement con numero di sequenza più elevato di quello già in memoria, sostituisce quello presente in memoria con quello ricevuto con il numero di sequenza maggiore.
La figura seguente mostra un esempio di utilizzo dell’attributo MAC Mobility Extended Community. Nella figura si ipotizza che l’indirizzo MAC-1 si sia già mosso una volta da Ovest verso Est e che sia ritornato ad Ovest. PE1-1, una volta appreso di nuovo l’indirizzo MAC-1 (via MAC learning sul piano dati o di controllo), invia a tutti i PE della stessa EVI un annuncio MAC/IP Advertisement con l’attributo MAC Mobility Extended Community avente il numero di sequenza posto a 2.
La figura seguente mostra invece cosa avviene dopo un nuovo spostamento dell’indirizzo MAC-1 da Ovest verso Est (fase 1 nella figura). Il router PE2-1, una volta accortosi (sempre via MAC learning sul piano dati o di controllo) della presenza di MAC-1 sul proprio ES, genera un nuovo annuncio di tipo MAC/IP Advertisement con numero di sequenza 3 (ossia, uno in più del valore del numero di sequenza ricevuto), che viene inviato a tutti i PE dell’EVI (fase 2 nella figura). Quando PE1-1 riceve questo nuovo annuncio con numero di sequenza maggiore, esegue due operazioni:
- Sostituisce l’annuncio corrente dell’indirizzo MAC con quello più aggiornato (numero di sequenza maggiore).
- Ritira l’annuncio inviato in precedenza con numero di sequenza 2 (fase 3 nella figura).
CONCLUSIONI
In questo post ho illustrato molti dettagli di funzionamento del modello EVPN introdotto in un post precedente. Finora però mi sono limitato a trattare gli aspetti legati al Livello 2, ossia di annuncio degli indirizzi MAC, del trasporto del traffico BUM e unicast noto, della mobilità degli indirizzi MAC, oltre che alle problematiche della gestione dei collegamenti multi-homed e le soluzioni ai problemi principali.
Il modello EVPN ha però un’altra formidabile freccia nel suo arco, l’integrazione con il Livello 3 (questo grazie alla possibilità offerta dagli annunci BGP EVPN di tipo MAC/IP Advertisement, di trasportare anche informazioni su un indirizzo IP associato all’indirizzo MAC). E questo è uno degli aspetti più interessanti del modello EVPN che tratterò nei post successivi.
Ricordo infine quanto detto nelle conclusioni del post precedente sul modello EVPN, questo non sta solo nelle slide, nei documenti IETF o nelle chiacchiere del sottoscritto, ma è già implementato in varie piattaforme commerciali (es. Cisco ASR 9k, Nexus 7k/9k, Juniper MX/EX, Alcatel-Lucent 7750 SR).
Coming up next... EVPN come piano di controllo per le VXLAN.
Pubblicato in
ReissBlog
Etichettato sotto
Giovedì, 29 Ottobre 2015 14:16
VXLAN: DAL MONDO FISICO A QUELLO VIRTUALE
Uno dei primi concetti che si apprendono quando si percorrono i primi passi nel mondo del Networking, è quello delle VLAN. In un’era dove il concetto di virtualizzazione sta diventando pervasivo, le VLAN possono essere considerate come un precursore dell’idea stessa di virtualizzazione.
L’idea di base delle VLAN, come ben noto, è legata al concetto di separazione del traffico di Livello 2 (L2 traffic isolation), ossia della creazione di tante LAN virtualmente separate, definite sulla stessa infrastruttura fisica, con gli host appartenenti a VLAN diverse che non possono comunicare direttamente. L’infrastruttura fisica può essere costituita sia da un singolo switch Ethernet che da vari switch Ethernet interconnessi tra loro. In ogni caso, i dispositivi fisici dove vengono realizzate le VLAN sono dispositivi di Livello 2.
Lo sviluppo dei Data Center e delle tecnologie correlate, come ad esempio la possibilità di creare su un server fisico più “macchine virtuali” (da qui in poi abbreviate con l’acronimo VM, Virtual Machine) hanno messo a nudo le limitazioni del concetto di VLAN, primo fra tutti il fatto che il VLAN tag è di soli 12 bit, sicuramente insufficienti per le moderne applicazioni di tipo cloud pubblico, dove i clienti (detti tenant nella documentazione in inglese) sono in genere dell’ordine delle centinaia di migliaia, con ciascun cliente che potrebbe aver bisogno a sua volta di svariate VLAN.
Un altro limite, non però direttamente legato al concetto di VLAN, è che le VLAN realizzate su reti switched Ethernet utilizzano come protocollo per prevenire i loop L2 e i cosiddetti broadcast storm, il protocollo Spanning Tree (STP), di cui esistono delle varianti che ne hanno migliorato alcuni aspetti (es. velocità di convergenza, distribuzione del traffico, ecc.) ma che hanno lasciato inalterato il difetto fondamentale, che il protocollo funziona sul blocco di alcune porte, che così non possono essere utilizzate, sottraendo di fatto banda alla rete.
Chi mi conosce sa che penso tutto il male possibile dell’STP e in generale delle reti switched Ehternet, anzi, secondo me Ethernet sarebbe dovuto esistere solo come standard di livello fisico, dove ha avuto e ha i suoi indubbi meriti. Per il resto credo sia stata una iattura di proporzioni storiche per il mondo del Networking IP. E l’introduzione di recenti tecnologie, che ne stanno decretando la morte (finalmente !) mi stanno dando ragione (una di queste è proprio il concetto di VXLAN che vedremo in questo post). Ma argomentare su questo mi porterebbe facilmente a “partire per la tangente”, magari lo farò in post futuro.
Ciò premesso, un gruppo di note aziende del settore, tra cui Cisco, WMware, Red Hat, Citrix, e altre nel seguito, ha dato vita a una nuova tecnica di virtual overlay networking che consente di eliminare i due principali difetti delle VLAN così come le conosciamo oggi. Questa nuova tecnica, nota come VXLAN (Virtual eXtensible LAN), è stata standardizzata poco più di un anno fa (Agosto 2014) attraverso una RFC di tipo informational: RFC 7348 - Virtual eXtensible Local Area Network (VXLAN): A Framework for Overlaying Virtualized Layer 2 Networks over Layer 3 Networks, ed è supportata da molte piattaforme, fisiche e virtuali.
Esistono altri tipi di tecniche di overlay networking alternative a VXLAN, come ad esempio NVGRE (Network Virtualization using Generic Routing Encapsulation) e STT (Stateless Transport Tunneling). Ma VXLAN è quella che sta ricevendo più consenso ed è implementata da tutti i principali costruttori di apparati di networking (es. Cisco, Juniper) ed in molti hypervisor (VMware ESX/NSX, KVM, ecc.).
FUNZIONAMENTO DI BASE
L’idea di base delle VXLAN è quella ben nota delle overlay virtual networks, ossia la possibilità di realizzare una rete logica (virtuale) sopra una rete fisica esistente. La rete fisica esistente (la rete underlay !) è in questo caso una banale rete IP (v4 o v6, non fa differenza), ma potrebbe essere anche un altro tipo di rete. La convenienza che la rete underlay sia una rete IP è dovuta alla diffusione pervasiva di questo tipo di reti, ormai diventate a tutti gli effetti vere e proprie reti multiservizio.
La rete logica è in questo caso un semplice segmento LAN, denominato da qui in poi segmento VXLAN. Le trame Ethernet generate dagli host (fisici o virtuali) appartenenti a un particolare segmento VXLAN, vengono trasportate da host a host utilizzando un incapsulamento di tipo MAC-in-UDP, i cui dettagli saranno visti in una prossima sezione. In pratica ciò che avviene è la sostituzione, per il trasporto delle trame Ethernet, della rete switched Ethernet con una semplice rete IP. I vantaggi che ne conseguono sono enormi:
La figura seguente illustra l’idea di base.
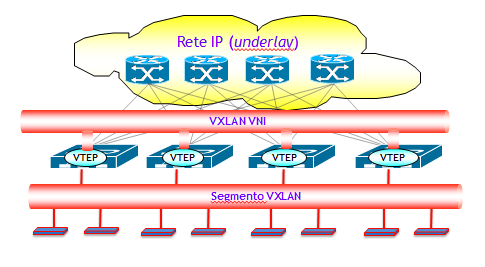
Nella figura compaiono due concetti chiave nel funzionamento delle VXLAN:
Poiché le trame Ethernet generate dagli host vengono incapsulate dalla funzione VTEP in pacchetti UDP/IP e a destinazione, sempre da una funzione VTEP vengono decapsulate, una VXLAN può anche essere pensata come uno schema di tunneling di trame di Livello 2 (trame Ethernet) su una rete di Livello 3 (la rete IP underlay). I tunnel sono di tipo stateless, che significa che ciascuna trama L2 viene incapsulata seguendo certe regole, e i router della rete underlay non hanno bisogno di alcuno stato aggiuntivo per espletare la funzione di trasporto. Inoltre, gli host si comportano come normali host connessi a un normale switch L2, e sono totalmente ignari della modalità di trasporto. La gestione dei VNI e dell’incapsulamento e decapsulamento delle trame L2 è demandata interamente alla funzione VTEP.
TRASPORTO DELLE TRAME L2 UNICAST
Vediamo ora con un esempio, come avviene il trasporto host-to-host (o VM-to-VM) delle trame Ethernet. La figura seguente riporta l’architettura generale di rete e il flusso delle trame e pacchetti IP scambiati.
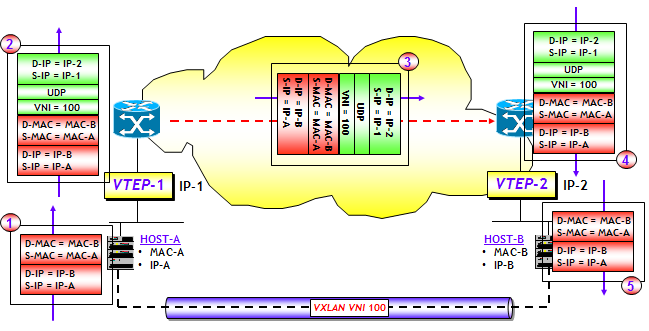
Nella figura, i due host HOST-A e HOST-B, entrambi parte del segmento VXLAN 100, comunicano tra loro attraverso il tunnel VXLAN realizzato tramite le due interfacce VTEP-1 e VTEP-2. I due host appartengono allo stesso segmento VXLAN identificato da VNI = 100, e alla stessa subnet IP. L’esempio assume che il MAC learning sia già avvenuto e le corrispondenti mappe MAC-to-VTEP esistano già su entrambe le VTEP. Questo è ovviamente un aspetto chiave del funzionamento sul quale nel seguito dovremo necessariamente far luce.
Per semplicità vedremo solo il “viaggio” di una trama Ethernet generata da HOST-A e diretta verso HOST-B. I passi evidenziati nella figura sono i seguenti:
TRASPORTO DEL TRAFFICO BUM
Supponiamo che l’HOST-A della figura sopra non conosca l’indirizzo MAC dell’HOST-B. Come avviene nelle classiche reti switched Ethernet, per scoprirlo, HOST-A utilizza il protocollo ARP. HOST-A invia quindi un classico ARP request all’interfaccia VTEP. Il messaggio ARP request, come noto, ha indirizzo MAC destinazione broadcast (= ffff.ffff.ffff). In uno scenario non-VXLAN, il messaggio ARP verrebbe veicolato dalla rete switched Ethernet a tutti gli host della stessa VLAN. In uno scenario VXLAN, il messaggio ARP request viene incapsulato in un pacchetto VXLAN con VNI = 100, indirizzo IP sorgente quello dell’interfaccia VTEP-1 e indirizzo IP destinazione un indirizzo multicast preconfigurato, associato al segmento VXLAN identificato dal VNI = 100. L’indirizzo multicast consente di inviare il pacchetto VXLAN contenente il messaggio ARP request a tutte le interfacce VTEP dove sono collocati host del segmento VXLAN identificato dal VNI = 100.
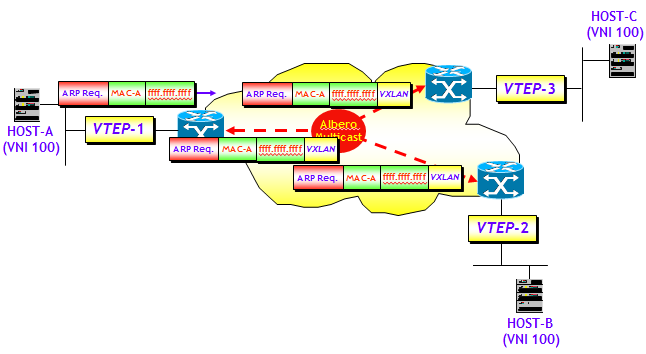
Tutto questo presuppone che all’interno della rete IP sia attivo un protocollo di routing multicast, e che le interfacce VTEP siano in grado di generare messaggi IGMP membership report per effettuare il join/leave dell’albero multicast. Anche se in teoria è possibile utilizzare un qualsiasi protocollo di routing multicast, è noto che “de facto” l’unico protocollo utilizzato nella quasi totalità delle applicazioni pratiche è il protocollo PIM. Una nota a latere è poi che, poiché ciascuna VTEP può essere sia sorgente che destinazione dei pacchetti multicast, è conveniente e raccomandato utilizzare il modello PIM-BiDir (vedi post precedente su mLDP).
Si noti che non è necessario avere un albero multicast per VXLAN, aspetto che potrebbe portare a seri problemi di scalabilità, potendo essere le VXLAN dell’ordine delle centinaia di migliaia (in teoria, come detto sopra, fino a più di 16 Milioni). Possono essere utilizzati tranquillamente alberi multicast condivisi da più VXLAN, comunque la segregazione del traffico tra VXLAN non ne viene influenzata poiché questa dipende esclusivamente dal valore del VNI. Il rovescio della medaglia nell’utilizzo di alberi multicast condivisi, è che il traffico BUM può arrivare anche a VTEP che non hanno host di una particolare VNI, con conseguente spreco di banda.
L’utilizzo del routing multicast per il traffico BUM è quanto prescritto nella versione originale della RFC 7348, ma questo ha costituito un forte freno all'introduzione di VXLAN in reti che non utilizzano routing multicast per altri servizi (la quasi totalità dei Data Center in realtà, a parte quelli di alcune istituzioni finanziarie, che lo utilizzano per inviare a clienti selezionati dati di mercato). Per questo sono state adottate anche soluzioni alternative tipo ad esempio la Unicast-only VXLAN, adottata da Cisco nel proprio switch virtuale Nexus 1000v, di cui tratterò in un post successivo. Però attenzione a possibili problemi di interlavoro, a volte queste soluzioni alternative sono proprietarie !
MAC LEARNING
Il MAC learning avviene in due fasi. La prima è di tipo classico, ed è un MAC learning locale. Tramite questo processo l’interfaccia VTEP “impara” quali sono gli indirizzi MAC locali, ossia degli host che sono “direttamente connessi” alla macchina (fisica o virtuale) dove è definita l’interfaccia VTEP. Ad esempio, ritornando al caso della figura sopra, quando l’HOST-A invia un messaggio ARP request, la macchina dove è definita la funzione VTEP-1 inserisce nella tabella di forwarding L2 (CAM table) l’associazione <MAC-A ; porta>, come farebbe un qualsiasi classico switch L2. La commutazione del traffico locale tra host dello stesso segmento VXLAN avviene in modo tradizionale, senza “scomodare” la funzione VTEP, poiché non è necessario alcun incapsulamento VXLAN.
La seconda fase è quella più delicata, ma comunque semplice. Sempre ritornando al nostro esempio, quando l’interfaccia VTEP-2 (e anche l’interfaccia VTEP-3) riceve il messaggio ARP request, inserisce nella tabella di forwarding L2 della macchina dove è definita l’interfaccia VTEP-2, l’associazione <MAC-A ; IP-1>. L’associazione indica che per raggiungere l’indirizzo MAC-A dell’HOST-A, la trama Ethernet ricevuta dall’interfaccia VTEP-2 utilizza il tunnel VXLAN VTEP-2↔VTEP-1, ossia in pratica la trama viene incapsulata con VNI = 100, e trasportata in UDP/IP con porte UDP che vedremo, indirizzo IP sorgente IP-2 e indirizzo IP destinazione IP-1 (ossia, gli indirizzi IP rispettivamente delle interfacce VTEP-2 e VTEP-1).
Il tutto è riassunto nella figura seguente.
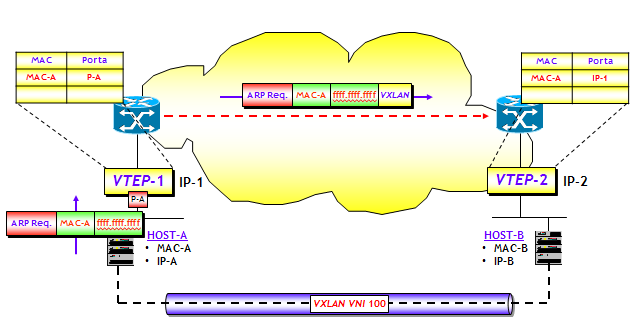
I lettori familiari con il servizio VPLS (Virtual Private LAN Service) avranno prontamente notato che il MAC learning è essenzialmente identico (a parte ovviamente il diverso contesto), ossia avviene interamente sul piano dati (come spesso scritto nella letteratura in inglese, in modalità flood-and-learn).
Recentemente si sta affermando però un’altra strategia, secondo la quale il MAC learning avviene il parte sul piano dati e in parte sul piano di controllo. La parte sul piano dati è quella locale, mentre la propagazione delle associazioni <MAC ; IP-VTEP> avviene sul piano di controllo, utilizzando l’estensione multiprotocollo del caro vecchio BGP (della serie, gallina vecchia fa buon brodo !). Tratterò diffusamente questa modalità in post successivi, ma prima dovrò scrivere qualcosa sul modello E-VPN (Ethernet-VPN, è un modello standard specificato nella RFC 7432 del Febbraio 2015), che può essere pensato come un NG-VPLS (Next Generation-VPLS). Questo modello, molto sofisticato, è già disponibile come piano di controllo per le VXLAN in alcune piattaforme commerciali (es. Cisco Nexus 9k, a partire dalla versione NX-OS 7.0(3)I1(1)). Esiste, ed è ancora in corso, un processo di standardizzazione per l’integrazione VXLAN/E-VPN (draft-ietf-bess-evpn-overlay-02). Tutto questo e altro ancora alle prossime puntate.
FORMATO DEI PACCHETTI VXLAN
I pacchetti VXLAN hanno un incapsulamento del tipo MAC-in-UDP, nel senso che le trame Ethernet originali sono incapsulate in pacchetti UDP/IP. Tra le trame originali e l’incapsulamento UDP/IP vi è il campo VNI. La figura seguente riporta l’intero incapsulamento (NOTA: in realtà è stato omesso l’incapsulamento di Livello 2 esterno, che dipende dal tipo di data-link utilizzato nel trasporto sulla rete IP underlay):
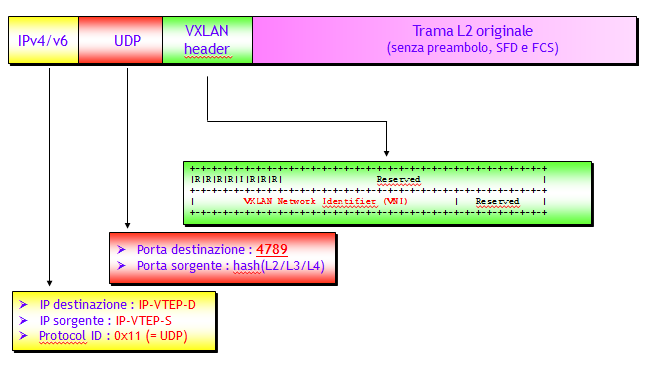
Il campo VXLAN header, in totale di lunghezza 8 byte, è suddiviso in tre parti:
Un aspetto operativo importante, quando si utilizzano le VXLAN, è la MTU delle interfacce (fisiche) attraversate dai pacchetti VXLAN. Infatti, rispetto al payload della trama L2 originale, per il trasporto vengono aggiunti 50 o 54 byte: IP (20 byte) + UDP (8 byte) + VXLAN (8 byte) + L2 (14 o 18 byte in funzione del tipo di trama Ethernet originale, v2 o IEEE802.1Q). Per cui è necessario accertarsi che la MTU sia sufficiente (es. 1.550 byte), anche perché la RFC 7348 (sez. 4.3) dice chiaramente che “VTEPs MUST NOT fragment VXLAN packets”. Si noti che la RFC 7348 è un po' ambigua circa il trattamento delle trame Ethernet originali contenenti un VLAN tag. Secondo la RFC infatti, le trame contenenti un VLAN tag "dovrebbero" essere scartate in ricezione dalla VTEP, mentre dal lato incapsulamento, il VLAN tag "non dovrebbe" essere trasportato (ossia, deve essere tolto !). Però viene lasciato uno spiraglio in quanto viene detto "unless configured otherwise". E come è noto, sono proprio queste ambiguità che spesso e volentieri creano i maggiori grattacapi nel caso di interlavoro di dispositivi di diversi costruttori.
INTERCONNESSIONE VXLAN-VLAN
Uno degli aspetti evidenti sin dall’inizio dell’introduzione delle VXLAN, è quello di come interconnettere mondo “virtuale” e mondo “fisico”. In altre parole, come interconnettere macchine virtuali che risiedono dietro una VXLAN, con macchine fisiche o virtuali che invece risiedono dietro una tradizionale VLAN (NOTA: la nomenclatura mondo fisico/mondo virtuale, anche se spesso utilizzata, è un po’ ambigua; sarebbe più corretto, secondo me, parlare di interconnessione VXLAN-VLAN).
Il problema è fondamentale perché nella transizione da mondo fisico a mondo virtuale, la convivenza di questi due mondi è inevitabile (un po’ come accade per l’introduzione di IPv6, dove la convivenza tra IPv4 e IPv6 sarà per molti anni anche questa inevitabile).
La funzione di interconnessione in se è concettualmente semplice. È però necessario un dispositivo che abbia il ruolo di gateway tra VXLAN e VLAN, spesso chiamato VXLAN gateway, con il compito di commutare il traffico da segmenti VXLAN a segmenti non-VXLAN e viceversa.
La figura seguente illustra il problema. Il ruolo del VXLAN gateway è quello di prendere i pacchetti VXLAN in arrivo dal segmento VXLAN, togliere l’incapsulamento VXLAN e quindi inoltrare la trama Ethernet originale sulla porta fisica corretta, sulla base dell’indirizzo MAC. Nella direzione opposta, le trame Ethernet in arrivo su una porta fisica non-VXLAN vengono mappate a un determinato segmento VXLAN sulla base del VLAN tag presente nella trama (ossia, nel caso di trame tagged) oppure sulla base dell’associazione (via configurazione) della porta di ingresso a una determinata VLAN (nel caso di trame untagged).
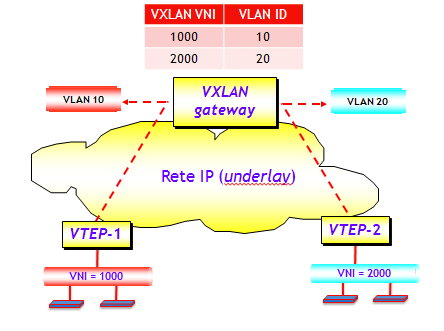
La funzione di VXLAN gateway può essere integrata negli switch ToR (Top of Rack) o in switch più in alto nella gerarchia topologica di un Data Center (core o addirittura WAN edge). Inoltre, la funzione può essere realizzata in Hardware o in Software.
La funzione descritta è in realtà una funzione di Livello 2 poiché mette in comunicazione due segmenti di rete, entrambi di Livello 2, appartenenti allo stesso dominio di broadcast. Vi è anche la possibilità di interconnettere segmenti VXLAN e VLAN appartenenti a diverse subnet IP, e in questo caso si parla di funzione VXLAN gateway di Livello 3. Su questo tornerò in seguito.
La funzione VXLAN gateway è attualmente implementata da vari costruttori, come ad esempio Cisco (Nexus 1000v, Nexus 9k), Juniper (serie MX, EX9200, QFX5100), Arista, Brocade, ecc. . Però, poiché è tutto un mondo dove le cose cambiano dall’oggi al domani, vi consiglio di consultare la documentazione dei costruttori per notizie più “fresche”.
CONCLUSIONI
Con questo post ho iniziato a scrivere su un mondo estremamente dinamico, che è quello dell’overlay virtual networking. Ho iniziato con lo standard VXLAN perché sta godendo dei maggiori favori tra i costruttori e produttori di software. Ma le cose da dire sono infinite e spero in futuro di scrivere molto altro su questi argomenti, cercando di seguire i trend tecnologici giusti. Ad esempio, tra i temi che tratterò presto ci sono quelli relativi al piano di controllo per le VXLAN e all’inter-VXLAN routing.
L’idea di base delle VLAN, come ben noto, è legata al concetto di separazione del traffico di Livello 2 (L2 traffic isolation), ossia della creazione di tante LAN virtualmente separate, definite sulla stessa infrastruttura fisica, con gli host appartenenti a VLAN diverse che non possono comunicare direttamente. L’infrastruttura fisica può essere costituita sia da un singolo switch Ethernet che da vari switch Ethernet interconnessi tra loro. In ogni caso, i dispositivi fisici dove vengono realizzate le VLAN sono dispositivi di Livello 2.
Lo sviluppo dei Data Center e delle tecnologie correlate, come ad esempio la possibilità di creare su un server fisico più “macchine virtuali” (da qui in poi abbreviate con l’acronimo VM, Virtual Machine) hanno messo a nudo le limitazioni del concetto di VLAN, primo fra tutti il fatto che il VLAN tag è di soli 12 bit, sicuramente insufficienti per le moderne applicazioni di tipo cloud pubblico, dove i clienti (detti tenant nella documentazione in inglese) sono in genere dell’ordine delle centinaia di migliaia, con ciascun cliente che potrebbe aver bisogno a sua volta di svariate VLAN.
Un altro limite, non però direttamente legato al concetto di VLAN, è che le VLAN realizzate su reti switched Ethernet utilizzano come protocollo per prevenire i loop L2 e i cosiddetti broadcast storm, il protocollo Spanning Tree (STP), di cui esistono delle varianti che ne hanno migliorato alcuni aspetti (es. velocità di convergenza, distribuzione del traffico, ecc.) ma che hanno lasciato inalterato il difetto fondamentale, che il protocollo funziona sul blocco di alcune porte, che così non possono essere utilizzate, sottraendo di fatto banda alla rete.
Chi mi conosce sa che penso tutto il male possibile dell’STP e in generale delle reti switched Ehternet, anzi, secondo me Ethernet sarebbe dovuto esistere solo come standard di livello fisico, dove ha avuto e ha i suoi indubbi meriti. Per il resto credo sia stata una iattura di proporzioni storiche per il mondo del Networking IP. E l’introduzione di recenti tecnologie, che ne stanno decretando la morte (finalmente !) mi stanno dando ragione (una di queste è proprio il concetto di VXLAN che vedremo in questo post). Ma argomentare su questo mi porterebbe facilmente a “partire per la tangente”, magari lo farò in post futuro.
Ciò premesso, un gruppo di note aziende del settore, tra cui Cisco, WMware, Red Hat, Citrix, e altre nel seguito, ha dato vita a una nuova tecnica di virtual overlay networking che consente di eliminare i due principali difetti delle VLAN così come le conosciamo oggi. Questa nuova tecnica, nota come VXLAN (Virtual eXtensible LAN), è stata standardizzata poco più di un anno fa (Agosto 2014) attraverso una RFC di tipo informational: RFC 7348 - Virtual eXtensible Local Area Network (VXLAN): A Framework for Overlaying Virtualized Layer 2 Networks over Layer 3 Networks, ed è supportata da molte piattaforme, fisiche e virtuali.
Esistono altri tipi di tecniche di overlay networking alternative a VXLAN, come ad esempio NVGRE (Network Virtualization using Generic Routing Encapsulation) e STT (Stateless Transport Tunneling). Ma VXLAN è quella che sta ricevendo più consenso ed è implementata da tutti i principali costruttori di apparati di networking (es. Cisco, Juniper) ed in molti hypervisor (VMware ESX/NSX, KVM, ecc.).
FUNZIONAMENTO DI BASE
L’idea di base delle VXLAN è quella ben nota delle overlay virtual networks, ossia la possibilità di realizzare una rete logica (virtuale) sopra una rete fisica esistente. La rete fisica esistente (la rete underlay !) è in questo caso una banale rete IP (v4 o v6, non fa differenza), ma potrebbe essere anche un altro tipo di rete. La convenienza che la rete underlay sia una rete IP è dovuta alla diffusione pervasiva di questo tipo di reti, ormai diventate a tutti gli effetti vere e proprie reti multiservizio.
La rete logica è in questo caso un semplice segmento LAN, denominato da qui in poi segmento VXLAN. Le trame Ethernet generate dagli host (fisici o virtuali) appartenenti a un particolare segmento VXLAN, vengono trasportate da host a host utilizzando un incapsulamento di tipo MAC-in-UDP, i cui dettagli saranno visti in una prossima sezione. In pratica ciò che avviene è la sostituzione, per il trasporto delle trame Ethernet, della rete switched Ethernet con una semplice rete IP. I vantaggi che ne conseguono sono enormi:
- Non è più necessario il protocollo Spanning Tree.
- Vengono eliminati alla radice i (gravi) problemi causati dai broadcast storm.
- Aumenta la banda disponibile poiché non esistono più porte nello stato blocking.
- È possibile sfruttare meglio tutta la banda a disposizione utilizzando le tecniche di load balancing tipiche dei protocolli di routing IP.
La figura seguente illustra l’idea di base.
Nella figura compaiono due concetti chiave nel funzionamento delle VXLAN:
- VNI (VXLAN Network Identifier): è l’identificativo del segmento VXLAN. Praticamente sostituisce il VLAN tag come identificativo di un segmento LAN. Come si vedrà nel seguito nella sezione dedicata all’incapsulamento VXLAN, il VNI è di 24 bit, il che consente di definire più di 16,7 milioni di segmenti VXLAN (contro i 4096 (teorici) delle VLAN classiche).
- VTEP (VXLAN Tunnel End Point): è una funzione che gestisce l’origine e la terminazione, ossia l’incapsulamento e il decapsulamento, dei pacchetti VXLAN. Inoltre, si occupa di associare ciascun host a un determinato segmento VXLAN. Questa funzione può essere definita sia su una macchina fisica (es. un switch L2), oppure su un Hypervisor (es. VMware ESX/NSX, KVM, ecc.).
Poiché le trame Ethernet generate dagli host vengono incapsulate dalla funzione VTEP in pacchetti UDP/IP e a destinazione, sempre da una funzione VTEP vengono decapsulate, una VXLAN può anche essere pensata come uno schema di tunneling di trame di Livello 2 (trame Ethernet) su una rete di Livello 3 (la rete IP underlay). I tunnel sono di tipo stateless, che significa che ciascuna trama L2 viene incapsulata seguendo certe regole, e i router della rete underlay non hanno bisogno di alcuno stato aggiuntivo per espletare la funzione di trasporto. Inoltre, gli host si comportano come normali host connessi a un normale switch L2, e sono totalmente ignari della modalità di trasporto. La gestione dei VNI e dell’incapsulamento e decapsulamento delle trame L2 è demandata interamente alla funzione VTEP.
TRASPORTO DELLE TRAME L2 UNICAST
Vediamo ora con un esempio, come avviene il trasporto host-to-host (o VM-to-VM) delle trame Ethernet. La figura seguente riporta l’architettura generale di rete e il flusso delle trame e pacchetti IP scambiati.
Nella figura, i due host HOST-A e HOST-B, entrambi parte del segmento VXLAN 100, comunicano tra loro attraverso il tunnel VXLAN realizzato tramite le due interfacce VTEP-1 e VTEP-2. I due host appartengono allo stesso segmento VXLAN identificato da VNI = 100, e alla stessa subnet IP. L’esempio assume che il MAC learning sia già avvenuto e le corrispondenti mappe MAC-to-VTEP esistano già su entrambe le VTEP. Questo è ovviamente un aspetto chiave del funzionamento sul quale nel seguito dovremo necessariamente far luce.
Per semplicità vedremo solo il “viaggio” di una trama Ethernet generata da HOST-A e diretta verso HOST-B. I passi evidenziati nella figura sono i seguenti:
- HOST-A genera una classica trama Ethernet con MAC destinazione MAC-B, ossia l’indirizzo MAC di HOST-B, e MAC sorgente MAC-A, ossia il proprio MAC. All’interno della trama Ethernet viene trasportato un pacchetto IP con indirizzo IP destinazione IP-B, ossia l’indirizzo IP di HOST-B, e indirizzo IP sorgente IP-A, ossia il proprio indirizzo IP (NOTA: vi siete mai chiesti perché un host è identificato da due indirizzi diversi ? Non sarebbe stato sufficiente un solo indirizzo ? Vi lascio con questo dubbio amletico. Io ho una mia opinione al riguardo, che tutto il mondo del networking sarebbe stato molto più semplice e lineare senza questo dualismo di indirizzi, ma argomentare su questo mi porterebbe fuori tema, lo farò in un prossimo post).
- La trama Ethernet generata da HOST-A viene inviata all’interfaccia VTEP-1, che provvedere a incapsularla in un pacchetto UDP/IP. I dettagli dell’incapsulamento saranno visti in una successiva sezione. Qui è sufficiente dire che alla trama originale viene aggiunto il VNI (un po’ allo stesso modo di come a una trama untagged viene aggiunto un VLAN tag, quando questa viene trasportata su un collegamento trunk), e quindi una classica intestazione UDP/IP. La porta destinazione UDP è una porta well-known mentre quella sorgente è determinata attraverso una funzione di hash (ulteriori dettagli nella sezione dedicata all’incapsulamento). Gli indirizzi IP sorgente e destinazione sono rispettivamente gli indirizzi IP delle interfacce VTEP-1 e VTEP-2 (assegnati su base configurazione).
- Il pacchetto IP così costruito viene instradato sulla rete IP underlay seguendo le classiche regole dell’instradamento IP. Il pacchetto IP arriva così all’interfaccia VTEP-2.
- L’interfaccia VTEP-2 esegue l’operazione di decapsulamento, ossia toglie dal pacchetto le intestazioni IP e UDP e il VNI, ottenendo la trama Ethernet originale.
- Sulla base del segmento VXLAN di appartenenza (VNI = 100) e dell’indirizzo MAC destinazione (= MAC-B), la trama Ethernet viene inviata all’host destinazione (HOST-B).
- Come avviene il MAC learning e in particolare l’acquisizione della corrispondenza MAC-to-VTEP ? In altre parole, come fa l’interfaccia VTEP-1 a conoscere verso quale interfaccia VTEP instradare la trama Ethernet con destinazione MAC-B ?
- Come viene trasportato il traffico BUM (Broadcast, Unknown unicast, Multicast) ?
TRASPORTO DEL TRAFFICO BUM
Supponiamo che l’HOST-A della figura sopra non conosca l’indirizzo MAC dell’HOST-B. Come avviene nelle classiche reti switched Ethernet, per scoprirlo, HOST-A utilizza il protocollo ARP. HOST-A invia quindi un classico ARP request all’interfaccia VTEP. Il messaggio ARP request, come noto, ha indirizzo MAC destinazione broadcast (= ffff.ffff.ffff). In uno scenario non-VXLAN, il messaggio ARP verrebbe veicolato dalla rete switched Ethernet a tutti gli host della stessa VLAN. In uno scenario VXLAN, il messaggio ARP request viene incapsulato in un pacchetto VXLAN con VNI = 100, indirizzo IP sorgente quello dell’interfaccia VTEP-1 e indirizzo IP destinazione un indirizzo multicast preconfigurato, associato al segmento VXLAN identificato dal VNI = 100. L’indirizzo multicast consente di inviare il pacchetto VXLAN contenente il messaggio ARP request a tutte le interfacce VTEP dove sono collocati host del segmento VXLAN identificato dal VNI = 100.
Tutto questo presuppone che all’interno della rete IP sia attivo un protocollo di routing multicast, e che le interfacce VTEP siano in grado di generare messaggi IGMP membership report per effettuare il join/leave dell’albero multicast. Anche se in teoria è possibile utilizzare un qualsiasi protocollo di routing multicast, è noto che “de facto” l’unico protocollo utilizzato nella quasi totalità delle applicazioni pratiche è il protocollo PIM. Una nota a latere è poi che, poiché ciascuna VTEP può essere sia sorgente che destinazione dei pacchetti multicast, è conveniente e raccomandato utilizzare il modello PIM-BiDir (vedi post precedente su mLDP).
Si noti che non è necessario avere un albero multicast per VXLAN, aspetto che potrebbe portare a seri problemi di scalabilità, potendo essere le VXLAN dell’ordine delle centinaia di migliaia (in teoria, come detto sopra, fino a più di 16 Milioni). Possono essere utilizzati tranquillamente alberi multicast condivisi da più VXLAN, comunque la segregazione del traffico tra VXLAN non ne viene influenzata poiché questa dipende esclusivamente dal valore del VNI. Il rovescio della medaglia nell’utilizzo di alberi multicast condivisi, è che il traffico BUM può arrivare anche a VTEP che non hanno host di una particolare VNI, con conseguente spreco di banda.
L’utilizzo del routing multicast per il traffico BUM è quanto prescritto nella versione originale della RFC 7348, ma questo ha costituito un forte freno all'introduzione di VXLAN in reti che non utilizzano routing multicast per altri servizi (la quasi totalità dei Data Center in realtà, a parte quelli di alcune istituzioni finanziarie, che lo utilizzano per inviare a clienti selezionati dati di mercato). Per questo sono state adottate anche soluzioni alternative tipo ad esempio la Unicast-only VXLAN, adottata da Cisco nel proprio switch virtuale Nexus 1000v, di cui tratterò in un post successivo. Però attenzione a possibili problemi di interlavoro, a volte queste soluzioni alternative sono proprietarie !
MAC LEARNING
Il MAC learning avviene in due fasi. La prima è di tipo classico, ed è un MAC learning locale. Tramite questo processo l’interfaccia VTEP “impara” quali sono gli indirizzi MAC locali, ossia degli host che sono “direttamente connessi” alla macchina (fisica o virtuale) dove è definita l’interfaccia VTEP. Ad esempio, ritornando al caso della figura sopra, quando l’HOST-A invia un messaggio ARP request, la macchina dove è definita la funzione VTEP-1 inserisce nella tabella di forwarding L2 (CAM table) l’associazione <MAC-A ; porta>, come farebbe un qualsiasi classico switch L2. La commutazione del traffico locale tra host dello stesso segmento VXLAN avviene in modo tradizionale, senza “scomodare” la funzione VTEP, poiché non è necessario alcun incapsulamento VXLAN.
La seconda fase è quella più delicata, ma comunque semplice. Sempre ritornando al nostro esempio, quando l’interfaccia VTEP-2 (e anche l’interfaccia VTEP-3) riceve il messaggio ARP request, inserisce nella tabella di forwarding L2 della macchina dove è definita l’interfaccia VTEP-2, l’associazione <MAC-A ; IP-1>. L’associazione indica che per raggiungere l’indirizzo MAC-A dell’HOST-A, la trama Ethernet ricevuta dall’interfaccia VTEP-2 utilizza il tunnel VXLAN VTEP-2↔VTEP-1, ossia in pratica la trama viene incapsulata con VNI = 100, e trasportata in UDP/IP con porte UDP che vedremo, indirizzo IP sorgente IP-2 e indirizzo IP destinazione IP-1 (ossia, gli indirizzi IP rispettivamente delle interfacce VTEP-2 e VTEP-1).
Il tutto è riassunto nella figura seguente.
I lettori familiari con il servizio VPLS (Virtual Private LAN Service) avranno prontamente notato che il MAC learning è essenzialmente identico (a parte ovviamente il diverso contesto), ossia avviene interamente sul piano dati (come spesso scritto nella letteratura in inglese, in modalità flood-and-learn).
Recentemente si sta affermando però un’altra strategia, secondo la quale il MAC learning avviene il parte sul piano dati e in parte sul piano di controllo. La parte sul piano dati è quella locale, mentre la propagazione delle associazioni <MAC ; IP-VTEP> avviene sul piano di controllo, utilizzando l’estensione multiprotocollo del caro vecchio BGP (della serie, gallina vecchia fa buon brodo !). Tratterò diffusamente questa modalità in post successivi, ma prima dovrò scrivere qualcosa sul modello E-VPN (Ethernet-VPN, è un modello standard specificato nella RFC 7432 del Febbraio 2015), che può essere pensato come un NG-VPLS (Next Generation-VPLS). Questo modello, molto sofisticato, è già disponibile come piano di controllo per le VXLAN in alcune piattaforme commerciali (es. Cisco Nexus 9k, a partire dalla versione NX-OS 7.0(3)I1(1)). Esiste, ed è ancora in corso, un processo di standardizzazione per l’integrazione VXLAN/E-VPN (draft-ietf-bess-evpn-overlay-02). Tutto questo e altro ancora alle prossime puntate.
FORMATO DEI PACCHETTI VXLAN
I pacchetti VXLAN hanno un incapsulamento del tipo MAC-in-UDP, nel senso che le trame Ethernet originali sono incapsulate in pacchetti UDP/IP. Tra le trame originali e l’incapsulamento UDP/IP vi è il campo VNI. La figura seguente riporta l’intero incapsulamento (NOTA: in realtà è stato omesso l’incapsulamento di Livello 2 esterno, che dipende dal tipo di data-link utilizzato nel trasporto sulla rete IP underlay):
Il campo VXLAN header, in totale di lunghezza 8 byte, è suddiviso in tre parti:
- Flag: sono i primi 8 bit più significativi. Di questi bit, solo il quinto (bit I) va posto a 1, che indica che il VNI è valido. Gli altri 7 bit (bit R) sono sempre nulli e sono ignorati in ricezione.
- VNI: è un campo di 24 bit che contiene il valore di VNI più volte citato.
- Reserved: sono tutti i bit rimanenti, al momento non definiti. Nelle implementazioni correnti sono sempre nulli e sono ignorati in ricezione.
- Porta destinazione: valore well-known riservato dallo IANA all’applicazione VXLAN, pari a 4789.
- Porta sorgente: è il risultato di una operazione di hash di campi predefiniti L2/L3/l4 della trama originale. Lo scopo è quello di avere un valore da utilizzare per il Load Balancing sulla rete del traffico host-to-host, essendo gli indirizzi IP delle interfacce VTEP e la porta UDP destinazione fissi. Il valore risultante dovrebbe essere compreso nell’intervallo [49.152-65.535] riservato per usi privati (vedi RFC 6335).
Un aspetto operativo importante, quando si utilizzano le VXLAN, è la MTU delle interfacce (fisiche) attraversate dai pacchetti VXLAN. Infatti, rispetto al payload della trama L2 originale, per il trasporto vengono aggiunti 50 o 54 byte: IP (20 byte) + UDP (8 byte) + VXLAN (8 byte) + L2 (14 o 18 byte in funzione del tipo di trama Ethernet originale, v2 o IEEE802.1Q). Per cui è necessario accertarsi che la MTU sia sufficiente (es. 1.550 byte), anche perché la RFC 7348 (sez. 4.3) dice chiaramente che “VTEPs MUST NOT fragment VXLAN packets”. Si noti che la RFC 7348 è un po' ambigua circa il trattamento delle trame Ethernet originali contenenti un VLAN tag. Secondo la RFC infatti, le trame contenenti un VLAN tag "dovrebbero" essere scartate in ricezione dalla VTEP, mentre dal lato incapsulamento, il VLAN tag "non dovrebbe" essere trasportato (ossia, deve essere tolto !). Però viene lasciato uno spiraglio in quanto viene detto "unless configured otherwise". E come è noto, sono proprio queste ambiguità che spesso e volentieri creano i maggiori grattacapi nel caso di interlavoro di dispositivi di diversi costruttori.
INTERCONNESSIONE VXLAN-VLAN
Uno degli aspetti evidenti sin dall’inizio dell’introduzione delle VXLAN, è quello di come interconnettere mondo “virtuale” e mondo “fisico”. In altre parole, come interconnettere macchine virtuali che risiedono dietro una VXLAN, con macchine fisiche o virtuali che invece risiedono dietro una tradizionale VLAN (NOTA: la nomenclatura mondo fisico/mondo virtuale, anche se spesso utilizzata, è un po’ ambigua; sarebbe più corretto, secondo me, parlare di interconnessione VXLAN-VLAN).
Il problema è fondamentale perché nella transizione da mondo fisico a mondo virtuale, la convivenza di questi due mondi è inevitabile (un po’ come accade per l’introduzione di IPv6, dove la convivenza tra IPv4 e IPv6 sarà per molti anni anche questa inevitabile).
La funzione di interconnessione in se è concettualmente semplice. È però necessario un dispositivo che abbia il ruolo di gateway tra VXLAN e VLAN, spesso chiamato VXLAN gateway, con il compito di commutare il traffico da segmenti VXLAN a segmenti non-VXLAN e viceversa.
La figura seguente illustra il problema. Il ruolo del VXLAN gateway è quello di prendere i pacchetti VXLAN in arrivo dal segmento VXLAN, togliere l’incapsulamento VXLAN e quindi inoltrare la trama Ethernet originale sulla porta fisica corretta, sulla base dell’indirizzo MAC. Nella direzione opposta, le trame Ethernet in arrivo su una porta fisica non-VXLAN vengono mappate a un determinato segmento VXLAN sulla base del VLAN tag presente nella trama (ossia, nel caso di trame tagged) oppure sulla base dell’associazione (via configurazione) della porta di ingresso a una determinata VLAN (nel caso di trame untagged).
La funzione di VXLAN gateway può essere integrata negli switch ToR (Top of Rack) o in switch più in alto nella gerarchia topologica di un Data Center (core o addirittura WAN edge). Inoltre, la funzione può essere realizzata in Hardware o in Software.
La funzione descritta è in realtà una funzione di Livello 2 poiché mette in comunicazione due segmenti di rete, entrambi di Livello 2, appartenenti allo stesso dominio di broadcast. Vi è anche la possibilità di interconnettere segmenti VXLAN e VLAN appartenenti a diverse subnet IP, e in questo caso si parla di funzione VXLAN gateway di Livello 3. Su questo tornerò in seguito.
La funzione VXLAN gateway è attualmente implementata da vari costruttori, come ad esempio Cisco (Nexus 1000v, Nexus 9k), Juniper (serie MX, EX9200, QFX5100), Arista, Brocade, ecc. . Però, poiché è tutto un mondo dove le cose cambiano dall’oggi al domani, vi consiglio di consultare la documentazione dei costruttori per notizie più “fresche”.
CONCLUSIONI
Con questo post ho iniziato a scrivere su un mondo estremamente dinamico, che è quello dell’overlay virtual networking. Ho iniziato con lo standard VXLAN perché sta godendo dei maggiori favori tra i costruttori e produttori di software. Ma le cose da dire sono infinite e spero in futuro di scrivere molto altro su questi argomenti, cercando di seguire i trend tecnologici giusti. Ad esempio, tra i temi che tratterò presto ci sono quelli relativi al piano di controllo per le VXLAN e all’inter-VXLAN routing.
Pubblicato in
ReissBlog
Etichettato sotto
Sabato, 17 Ottobre 2015 06:23
MPLS NEWS : LSP DI TIPO MULTIPOINT – PARTE II (mLDP)
Nel post precedente sulla realizzazione di LSP MPLS di tipo multipoint, ho detto che i LSP MPLS di tipo multipoint possono essere realizzati utilizzando come protocolli di segnalazione sia RSVP-TE che LDP, opportunamente estesi. Nel post precedente ho illustrato la realizzazione di LSP MPLS P2MP utilizzando come protocollo di segnalazione RSVP-TE, in questo post illustrerò invece come realizzare LSP MPLS di tipo multipoint utilizzando una estensione del protocollo LDP.
L’estensione di LDP per la realizzazione di LSP P2MP è specificata nella RFC 6388 - Label Distribution Protocol Extensions for Point-to-Multipoint and Multipoint-to-Multipoint Label Switched Paths, Novembre 2011. Nella letteratura tecnica, questa estensione di LDP viene indicata come multipoint LDP, abbreviato in mLDP (NOTA: nella documentazione di qualche vendor, mLDP viene indicato impropriamente come “multicast LDP”. La RFC 6388 utilizza invece la terminologia “multipoint LDP”).
mLDP, a differenza di RSVP-TE, consente la realizzazione di LSP MPLS sia di tipo P2MP che MP2MP, questi ultimi utilizzati ad esempio in alcuni contesti come il modello PIM-Bidir.
INTRODUZIONE
Per la segnalazione di LSP MPLS di tipo multipoint, mLDP utilizza, nei messaggi LABEL MAPPING, tre nuovi moduli TLV, il cui formato è riportato nel seguito. In realtà i tre moduli hanno identico formato, cambia solo il campo “Type” che identifica il tipo di modulo. I nuovi moduli contengono informazioni su tipo di LSP (P2MP/MP2MP), indirizzo IPv4/IPv6 del nodo radice e un valore “opaco” dipendente dal tipo di servizio.
Il meccanismo di segnalazione è analogo a quello per la realizzazione dei LSP di tipo punto-punto, e verrà descritto nelle sue linee generali nelle prossima sezione.
Nelle applicazioni dei LSP multipoint al modello NG-MVPN, un aspetto importante che differenzia mLDP da RSVP-TE è che mentre la segnalazione dei LSP P2MP realizzati via RSVP-TE, inizia dal nodo sorgente, la segnalazione dei LSP P2MP realizzati via mLDP segue la logica classica del downstream label allocation tipica del protocollo LDP, che inizia dai nodi destinazione. Questo pone il problema della conoscenza della sorgente dell’albero multicast da parte delle destinazioni. Questo problema è disaccoppiato dalla costruzione del LSP P2MP, ed è risolto manualmente attraverso una opportuna configurazione (si noti che, per contro, nel caso di segnalazione via RSVP-TE la sorgente “impara” l’identità delle destinazioni del traffico multicast, attraverso opportuni messaggi BGP della famiglia di indirizzi MCAST-VPN).
IDENTIFICAZIONE DI LSP MULTIPOINT
Assumendo nota l’identità della radice dell’albero, sia esso di tipo P2MP o MP2MP, un problema chiave è come identificare un LSP di tipo multipoint. Questo aspetto è fondamentale per stabilire i corretti stati di forwarding sui rami dell’albero multicast.
Una prima informazione necessaria è certamente l’identità del nodo radice. Ma da sola questa informazione non è sufficiente, poiché da un nodo radice possono originare più LSP P2MP.
Così, è necessario identificare non solo la radice, ma anche il LSP che parte dalla radice. LDP non ha alcun bisogno di essere informato sulla semantica dell’identificativo del LSP; dal suo punto di vista l’identificativo è un valore “opaco”.
La soluzione è analoga a quella già vista nel post precedente, adottata dalla segnalazione RSVP-TE: un LSP di tipo multipoint è identificato dalla coppia <IP-Radice; Valore Opaco>. Il valore effettivo del secondo elemento può essere assegnato in modo arbitrario e può anche essere derivato dal tipo di servizio.
Ricordo che i LSP di tipo P2P realizzati via LDP seguono i percorsi del protocollo IGP. Per una FEC (Forwarding Equivalence Class) costituita da una subnet IP, questo implica che l’etichetta uscente utilizzata da ciascun router è quella annunciata dal Next-Hop IGP nel percorso verso la subnet IP. Per contro, nei LSP di tipo multipoint, l’etichetta annunciata da un router è relativa al percorso IGP verso la radice dell’albero. Quindi per l’allocazione delle etichette viene seguito il percorso a ritroso verso la radice dell’albero, e non il percorso IGP che termina sulla destinazione del LSP P2P.
LSP DI TIPO P2MP
La figura seguente mostra il flusso di messaggi LDP LABEL MAPPING che consentono la realizzazione di un LSP P2MP. Nella figura, il nodo A è la radice mentre i nodi D ed E sono gli Edge-LSR di uscita. In un ambiente NG-MVPN, il nodo radice è il router dove è attestata la sorgente di traffico multicast, mentre gli Edge-LSR di uscita sono i router dove sono attestati i ricevitori del traffico multicast.
I messaggi LDP LABEL MAPPING VENGONO inviati a ritroso dai due Edge-LSR di uscita D ed E. Si noti che come per i LSP P2P, si utilizza una allocazione di etichette di tipo downstream.
Nell’esempio della figura, ecco ciò che avviene:
Un dettaglio interessante è anche come i LSR installano lo stato di forwarding MPLS. Le etichette entranti e uscenti sono determinate come al solito. Ad esempio, il LSR B avrà nella tabella di forwarding MPLS, in corrispondenza dell’etichetta entrante 70, due NHLFE uscenti: <30 ; IP-D> e <70 ; IP-C>, dove IP-D e IP-C rappresentano gli indirizzi IP Next-Hop rispettivamente dei LSR D e C. Questi ultimi sono determinati dagli indirizzi IP sorgente dei messaggi LDP HELLO (un quesito interessante, che vi lascio come esercizio è il seguente: perché gli indirizzi IP Next-Hop dei router D e C non possono essere determinati dagli indirizzi IP sorgente dei messaggi LABEL MAPPING ?).
Per chiudere questa sezione sulla realizzazione di LSP MPLS P2MP, è utile dare uno sguardo al modulo “P2MP FEC TLV”.
Il supporto del modulo “P2MP FEC TLV” viene negoziato tra LDP peer, utilizzando il messaggio LDP INITIALIZATION nella fase di realizzazione della sessione LDP, utilizzando delle LDP Capability (maggiori informazioni nella RFC 6388). Può anche essere negoziato a sessione già operativa utilizzando il nuovo messaggio LDP CAPABILITY, specificato nella RFC 5561 – LDP Capabilities, Luglio 2009.
Il formato del modulo “P2MP FEC TLV” è riportato nella figura seguente.

I vari campi hanno il seguente significato:
Solo per fare un esempio pratico, il comando di tipo “show” seguente, eseguito su un router Cisco che utilizza l’IOS XR, mostra le etichette locali e remote di un LSP MPLS di tipo P2MP realizzato via mLDP, sul LSR di transito B della figura sopra:
RP/0/1/CPU0:LSR-B# show mpls mldp database
Wed Oct 14 10:24:45.204 UTC
mLDP database
LSM-ID: 0x00006 Type: P2MP Uptime: 1w1d
FEC Root : 10.0.0.1
Opaque decoded : [vpnv4 3269:1 192.168.0.1 232.1.2.3]
Upstream neighbor(s) :
10.0.0.1:0 [Active] Uptime: 1w1d
Next Hop : 10.0.1.1
Interface : GigabitEthernet0/2/1/1
Local Label (D) : 70
Downstream client(s):
LDP 10.0.0.3:0 Uptime: 1w1d
Next Hop : 10.0.3.1
Interface : GigabitEthernet0/2/1/2
Remote label (D) : 30
LDP 10.0.0.4:0 Uptime: 1w1d
Next Hop : 10.0.4.1
Interface : GigabitEthernet0/2/1/3
Remote label (D) : 70
La visualizzazione mostra, tra le altre informazioni, le etichette MPLS locale (= 70) e remote (30 ricevuta dal LSR D e 70 ricevuta dal LSR C), che vengono successivamente utilizzate sul piano dati. Questo significa che quando il LSR B riceve un pacchetto MPLS con etichetta 70, il pacchetto verrà replicato sulle due interfacce Gi0/2/1/2 e Gi0/2/1/3 con etichette MPLS rispettivamente 30 e 70.
LSP DI TIPO MP2MP
I LSP di tipo MP2MP sono l’equivalente del servizio PIM-BiDir nel routing multicast. Poiché il PIM-BiDir potrebbe non essere familiare a molti, prima di mostrare come realizzare LSP di MP2MP voglio spendere due parole su questa variante del protocollo PIM.
********* NOTA CULTURALE: DUE PAROLE SUL PIM-BIDIR *********
Il PIM-BiDir è forse la variante meno nota del protocollo PIM. Tutti conosciamo il PIM-DM (PIM – Dense Mode), il PIM-SM (PIM – Sparse Mode) e il PIM-SSM (PIM – Source Specific Multicast). Le ultime due varianti sono quelle più adottate nelle applicazioni pratiche. Tutte queste varianti hanno la loro naturale applicazione in scenari con poche sorgenti e molti ricevitori. PIM-BiDir (PIM – BiDirectional) è stato invece sviluppato per scenari dove ogni host può essere al contempo sorgente e ricevitore di traffico multicast. Un classico esempio è il servizio di videoconferenza, dove ciascun host al tempo stesso invia e riceve il segnale video/audio. Lo svantaggio di utilizzare PIM-SM in un simile scenario è che le tabelle di routing multicast conterrebbero molti stati, sia di tipo (S, G) che di tipo (*, G). Con il PIM BiDir invece, vengono solo costruiti stati di tipo (*, G).
Un’altra differenza fondamentale tra PIM-SM e PIM-BiDir è che mentre con PIM-SM il traffico fluisce dalle sorgenti verso Rendezvous-Point (RP) e da questo verso i ricevitori (solo successivamente il traffico fluisce sull’albero ottimizzato con radice il router che riceve dalla sorgente il traffico multicast), con PIM-BiDir il traffico multicast fluisce su uno spanning-tree (simile a quello costruito nelle reti L2 Switched, ma per fortuna qui non ci sono porte nello stato blocking !) che ha come radice il RP. In altre parole, con PIM-BiDir il traffico multicast fluisce sia nella direzione downstream, ossia dal RP verso i ricevitori, che in direzione upstream, ossia nella direzione opposta. Vi sono altri dettagli importanti che differenziano PIM-SM da PIM-BiDir (es. assenza del Reverse Path Forwarding, assenza della registrazione delle sorgenti, e altro), ma per quanto diremo sui LSP MPLS di tipo MP2MP, è sufficiente quanto ho detto sin qui, in particolare la modalità con cui il traffico viaggia sull’albero multicast (di tipo condiviso).
********* FINE NOTA CULTURALE *********
La realizzazione di un LSP MPLS di tipo MP2MP si basa sulla presenza di un nodo radice, scelto a piacere e identificato da un indirizzo IP (tipicamente un indirizzo di loopback). Oltre al nodo radice, il LSP, al pari di quanto visto per i LSP di tipo P2MP, è identificato anche qui da un valore “opaco”. Un LSP di tipo MP2MP è quindi identificato dalla coppia <IP-radice ; Valore Opaco>.
L’aspetto interessante è la procedura di realizzazione del LSP, ossia l’allocazione delle etichette MPLS e la creazione degli entry della tabella di forwarding MPLS (la LFIB !). Un LSP MPLS di tipo MP2MP può essere pensato come costituito da due sezioni, downstream e upstream. La sezione downstream è identica a quella vista sopra per i LSP di tipo MP2MP, mentre la sezione upstream è costituita da un classico LSP MP2P. Per capire meglio il funzionamento, è bene prima chiarire i concetti di direzione downstream e upstream del traffico che scorre sul LSP. La direzione downstream è quella dal nodo radice verso i nodi foglia, al contrario, la direzione upstream è quella dai nodi foglia verso il nodo radice.
Vediamo con un esempio come avviene la segnalazione. I messaggi LDP Label Mapping utilizzano i due moduli “MP2MP DOWNSTREAM FEC TLV” e “MP2MP UPSTREAM FEC TLV” , che hanno formato identico al modulo “P2MP FEC TLV” visto sopra, cambia solo il campo “Type”, che per il modulo “MP2MP DOWNSTREAM FEC TLV” è pari a 0x08 e per il modulo “MP2MP UPSTREAM FEC TLV” è invece pari a 0x07.
La figura seguente riporta il flusso dei messaggi LDP Label Mapping per la sezione downstream (parte (a) della figura) e per la sezione upstream (parte (b) della figura).
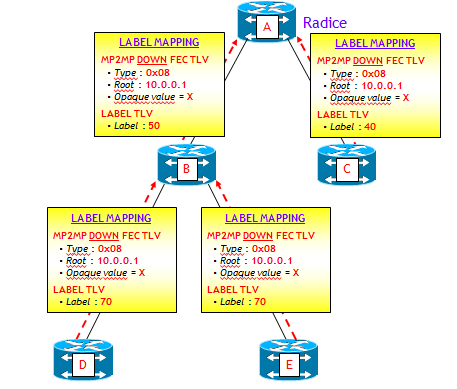
(a)
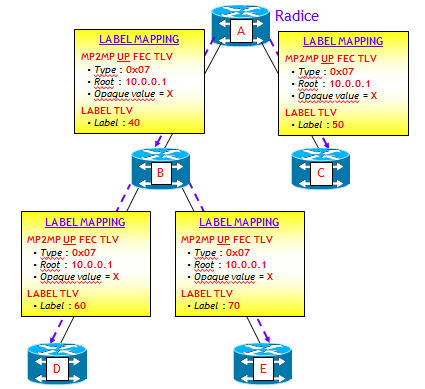
(b)
Si noti che la sezione upstream altro non è che la classica segnalazione di LSP MPLS unicast, tutti convergenti verso lo stesso LSR di uscita (per questo il LSP MPLS risultante viene detto Multipoint-to-Point, MP2P). Per vederlo, il lettore può divertirsi a ruotare la figura nella parte (b) di 90° in senso orario e ritroverà la classica segnalazione di LSP MPLS unicast, con i messaggi LABEL MAPPING che partono da più LSR di ingresso (nella figura D, C ed E) e si propagano fino al nodo radice (nella figura il LSR A).
Il piano dati a questo punto è semplice. Supponendo che da un LSR foglia parta un pacchetto MPLS destinato a tutti gli altri LSR foglia, questo seguirà un percorso nella direzione upstream (ossia, verso il nodo radice) fino a che non incontra un punto di diramazione verso un nodo foglia, dopodiché seguirà il percorso verso il nodo foglia in direzione downstream. Le etichette MPLS utilizzate nella direzione upstream sono quelle annunciate nei messaggi LDP LABEL MAPPING contenenti il modulo “MP2MP UPSTREAM FEC TLV” e analogamente, le etichette MPLS utilizzate nella direzione upstream sono quelle annunciate nei messaggi LDP LABEL MAPPING contenenti il modulo “MP2MP DOWNSTREAM FEC TLV”
La figura seguente riporta un esempio, che fa riferimento alle etichette annunciate nelle figure precedenti.
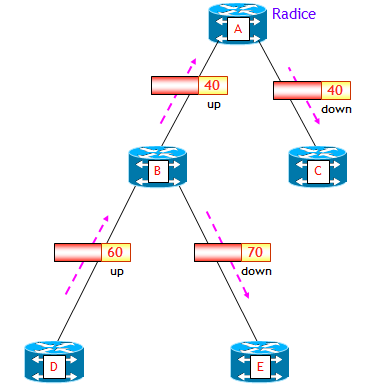
Lascio al lettore la verifica della correttezza delle etichette MPLS utilizzate.
Per chiudere, anche qui per fare un esempio pratico, il comando di tipo “show” seguente, eseguito su un router Cisco che utilizza l’IOS XR, mostra le etichette locali e remote di un LSP MPLS di tipo MP2MP realizzato via mLDP, sul LSR di transito B della figura sopra:
RP/0/1/CPU0:LSR-B# show mpls mldp database
Wed Oct 14 11:32:14.155 UTC
LSM-ID: 0x00001 Type: MP2MP Uptime: 1w2d
FEC Root : 10.0.0.1
Opaque decoded : [mdt 3269:1 0]
Upstream neighbor(s) :
10.0.0.1:0 [Active] Uptime: 1w2d
Next Hop : 10.0.1.1
Interface : GigabitEthernet0/2/1/1
Local Label (D) : 50 Remote Label (U): 40
Downstream client(s):
LDP 10.0.0.3:0 Uptime: 1w2d
Next Hop : 10.0.3.1
Interface : GigabitEthernet0/2/1/2
Remote label (D) : 70 Local label (U) : 70
LDP 10.0.0.4:0 Uptime: 1w2d
Next Hop : 10.0.4.1
Interface : GigabitEthernet0/2/1/3
Remote label (D) : 70 Local label (U) : 60
RSVP-TE o mLDP ?
Vi sono molte differenze tra la segnalazione di LSP MPLS multipoint via RSVP-TE o via mLDP, tra cui le più importanti sono:
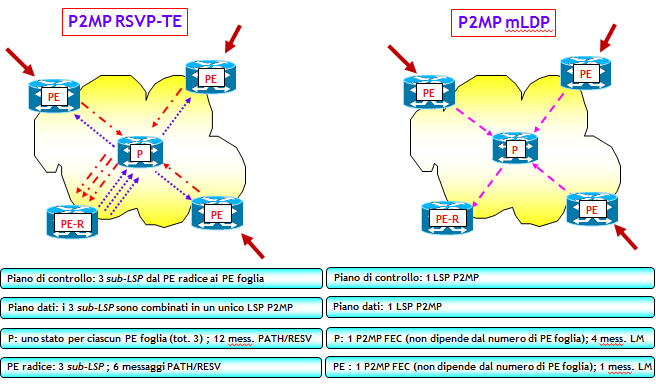
Oltre a quanto mostrato nella figura, vi è anche un ulteriore aspetto da tener presente. Quando un PE foglia non ha più ricevitori interessati al gruppo multicast il cui traffico utilizza un albero Selective, con RSVP-TE deve inviare in direzione upstream fino al PE radice, un messaggio RESVTEAR. Questo messaggio deve quindi attraversare tutta la rete fino al PE radice. Per contro, con mLDP è sufficiente un semplice messaggio LABEL WITHDRAW fino al LDP peer adiacente, per raggiungere lo stesso risultato.
Nelle applicazione alle MVPN ricordo inoltre che con l’utilizzo di mLDP, nella creazione di alberi (P-tunnel) di tipo Selective non è necessario utilizzare annunci MCAST-VPN Leaf A-D. Questo perché con mLDP la segnalazione è iniziata dai PE downstream.
CONCLUSIONI
In questo post ho illustrato l’estensione del protocolo LDP nota come mLDP (multipoint LDP), che consente la realizzazione di LSP MPLS sia di tipo P2MP che di tipo MP2MP. Nel post ho anche fatto un confronto tra i due tipi di segnalazione mLDP e RSVP-TE, mettendo in luce le differenze, vantaggi e svantaggi dell’una e dell’altra.
Io ho la personale opinione che la segnalazione mLDP sia più semplice e meno dispendiosa. E questo mi fa ritornare in mente una cosa vecchia: ma non era forse preferibile il CR-LDP a RSVP-TE ? (NOTA (per i più giovani): CR-LDP era una estensione di LDP per la segnalazione di percorsi MPLS Explicitly Routed, meglio noti come tunnel MPLS-TE. Purtroppo IETF (spinta da Cisco) preferì a suo tempo sviluppare per questo scopo RSVP-TE, congelando lo sviluppo di CR-LDP, che oggi non è più supportato da alcun costruttore).
Ricordo che per chi volesse approfondire queste tematiche, abbiamo nel catalogo corsi della Reiss Romoli, un corso ad hoc di due giorni sul modello NG-MVPN (IPN269, Next Generation Multicast VPN), dove l’argomento dei LSP MPLS multipoint viene trattato con dovizia di particolari e dove sono previste esercitazioni con piattaforme Juniper.
L’estensione di LDP per la realizzazione di LSP P2MP è specificata nella RFC 6388 - Label Distribution Protocol Extensions for Point-to-Multipoint and Multipoint-to-Multipoint Label Switched Paths, Novembre 2011. Nella letteratura tecnica, questa estensione di LDP viene indicata come multipoint LDP, abbreviato in mLDP (NOTA: nella documentazione di qualche vendor, mLDP viene indicato impropriamente come “multicast LDP”. La RFC 6388 utilizza invece la terminologia “multipoint LDP”).
mLDP, a differenza di RSVP-TE, consente la realizzazione di LSP MPLS sia di tipo P2MP che MP2MP, questi ultimi utilizzati ad esempio in alcuni contesti come il modello PIM-Bidir.
INTRODUZIONE
Per la segnalazione di LSP MPLS di tipo multipoint, mLDP utilizza, nei messaggi LABEL MAPPING, tre nuovi moduli TLV, il cui formato è riportato nel seguito. In realtà i tre moduli hanno identico formato, cambia solo il campo “Type” che identifica il tipo di modulo. I nuovi moduli contengono informazioni su tipo di LSP (P2MP/MP2MP), indirizzo IPv4/IPv6 del nodo radice e un valore “opaco” dipendente dal tipo di servizio.
Il meccanismo di segnalazione è analogo a quello per la realizzazione dei LSP di tipo punto-punto, e verrà descritto nelle sue linee generali nelle prossima sezione.
Nelle applicazioni dei LSP multipoint al modello NG-MVPN, un aspetto importante che differenzia mLDP da RSVP-TE è che mentre la segnalazione dei LSP P2MP realizzati via RSVP-TE, inizia dal nodo sorgente, la segnalazione dei LSP P2MP realizzati via mLDP segue la logica classica del downstream label allocation tipica del protocollo LDP, che inizia dai nodi destinazione. Questo pone il problema della conoscenza della sorgente dell’albero multicast da parte delle destinazioni. Questo problema è disaccoppiato dalla costruzione del LSP P2MP, ed è risolto manualmente attraverso una opportuna configurazione (si noti che, per contro, nel caso di segnalazione via RSVP-TE la sorgente “impara” l’identità delle destinazioni del traffico multicast, attraverso opportuni messaggi BGP della famiglia di indirizzi MCAST-VPN).
IDENTIFICAZIONE DI LSP MULTIPOINT
Assumendo nota l’identità della radice dell’albero, sia esso di tipo P2MP o MP2MP, un problema chiave è come identificare un LSP di tipo multipoint. Questo aspetto è fondamentale per stabilire i corretti stati di forwarding sui rami dell’albero multicast.
Una prima informazione necessaria è certamente l’identità del nodo radice. Ma da sola questa informazione non è sufficiente, poiché da un nodo radice possono originare più LSP P2MP.
Così, è necessario identificare non solo la radice, ma anche il LSP che parte dalla radice. LDP non ha alcun bisogno di essere informato sulla semantica dell’identificativo del LSP; dal suo punto di vista l’identificativo è un valore “opaco”.
La soluzione è analoga a quella già vista nel post precedente, adottata dalla segnalazione RSVP-TE: un LSP di tipo multipoint è identificato dalla coppia <IP-Radice; Valore Opaco>. Il valore effettivo del secondo elemento può essere assegnato in modo arbitrario e può anche essere derivato dal tipo di servizio.
Ricordo che i LSP di tipo P2P realizzati via LDP seguono i percorsi del protocollo IGP. Per una FEC (Forwarding Equivalence Class) costituita da una subnet IP, questo implica che l’etichetta uscente utilizzata da ciascun router è quella annunciata dal Next-Hop IGP nel percorso verso la subnet IP. Per contro, nei LSP di tipo multipoint, l’etichetta annunciata da un router è relativa al percorso IGP verso la radice dell’albero. Quindi per l’allocazione delle etichette viene seguito il percorso a ritroso verso la radice dell’albero, e non il percorso IGP che termina sulla destinazione del LSP P2P.
LSP DI TIPO P2MP
La figura seguente mostra il flusso di messaggi LDP LABEL MAPPING che consentono la realizzazione di un LSP P2MP. Nella figura, il nodo A è la radice mentre i nodi D ed E sono gli Edge-LSR di uscita. In un ambiente NG-MVPN, il nodo radice è il router dove è attestata la sorgente di traffico multicast, mentre gli Edge-LSR di uscita sono i router dove sono attestati i ricevitori del traffico multicast.
I messaggi LDP LABEL MAPPING VENGONO inviati a ritroso dai due Edge-LSR di uscita D ed E. Si noti che come per i LSP P2P, si utilizza una allocazione di etichette di tipo downstream.
Nell’esempio della figura, ecco ciò che avviene:
- Gli Edge-LSR di uscita D ed E inviano ai due router Next-Hop nel percorso IGP verso la radice A, due messaggi LDP LABEL MAPPING, ciascuno contenente una etichetta MPLS (inserita nel modulo “Label TLV”), e il modulo TLV comune “P2MP FEC TLV” (NOTA: Il Next-Hop IGP verso la radice, normalmente non coincide con l’indirizzo IP utilizzato per la sessione LDP, che di solito è una interfaccia di Loopback. Il problema viene però risolto poiché tramite il messaggio LDP ADDRESS, ogni LDP speaker conosce tutti gli indirizzi IP configurati sui propri LDP peer). Nelle applicazioni al servizio NG-MVPN non viene utilizzato il PHP, quindi gli Edge-LSR di uscita non associano l’etichetta speciale 3 ai due sub-LSP, ma due etichette arbitrarie. In applicazioni diverse dal servizio NG-MVPN, che richiedono l’applicazione del PHP, i due Edge-LSR di uscita utilizzano entrambi l’etichetta riservata 3.
- Il LSR C riceve il messaggio LABEL MAPPING e a sua volta ne genera un altro allocando la sua etichetta (= 70) associata alla “P2MP FEC TLV”. (NOTA: lo spazio di etichette utilizzato per i LSP P2MP è lo stesso utilizzato per i LSP P2P).
- A questo punto il LSR B riceve due messaggi LABEL MAPPING con identico “P2MP FEC TLV”. E qui sta l’aspetto chiave della segnalazione: il LSR B associa alla FEC <IP-radice ; Valore Opaco>, definita nel modulo “P2MP FEC TLV”, una etichetta MPLS (= 70 nella figura). In conseguenza di ciò, il LSR B invia al LSR di ingresso A un messaggio LABEL MAPPING con “Label TLV” contenente l'etichetta 70 e identico “P2MP FEC TLV”.
Un dettaglio interessante è anche come i LSR installano lo stato di forwarding MPLS. Le etichette entranti e uscenti sono determinate come al solito. Ad esempio, il LSR B avrà nella tabella di forwarding MPLS, in corrispondenza dell’etichetta entrante 70, due NHLFE uscenti: <30 ; IP-D> e <70 ; IP-C>, dove IP-D e IP-C rappresentano gli indirizzi IP Next-Hop rispettivamente dei LSR D e C. Questi ultimi sono determinati dagli indirizzi IP sorgente dei messaggi LDP HELLO (un quesito interessante, che vi lascio come esercizio è il seguente: perché gli indirizzi IP Next-Hop dei router D e C non possono essere determinati dagli indirizzi IP sorgente dei messaggi LABEL MAPPING ?).
Per chiudere questa sezione sulla realizzazione di LSP MPLS P2MP, è utile dare uno sguardo al modulo “P2MP FEC TLV”.
Il supporto del modulo “P2MP FEC TLV” viene negoziato tra LDP peer, utilizzando il messaggio LDP INITIALIZATION nella fase di realizzazione della sessione LDP, utilizzando delle LDP Capability (maggiori informazioni nella RFC 6388). Può anche essere negoziato a sessione già operativa utilizzando il nuovo messaggio LDP CAPABILITY, specificato nella RFC 5561 – LDP Capabilities, Luglio 2009.
Il formato del modulo “P2MP FEC TLV” è riportato nella figura seguente.
I vari campi hanno il seguente significato:
- P2MP Type : indica il tipo di LSP. Per LSP P2MP assume il valore 0x06, mentre per LSP MP2MP vi sono due possibilità, in funzione della direzione dell’annuncio: MP2MP downstream type (0x08) and MP2MP upstream type (0x07).
- Address-family: contiene il valore di address-family così come stabilito dallo IANA (1 per IPv4 e 2 per IPv6).
- Address length : lunghezza (in byte) dell’indirizzo contenuto nel campo Root Node Address. Può assumere i due valori 4 per indirizzi IPv4 e 16 per indirizzi IPv6.
- Root Node Address : indirizzo (IPv4 o IPv6) del nodo radice del LSP P2MP.
- Opaque Length : lunghezza (in byte) del campo Opaque Value.
- Opaque Value : contiene uno o più valori opachi, che insieme al Root Node Address, identificano univocamente il LSP P2MP.
Solo per fare un esempio pratico, il comando di tipo “show” seguente, eseguito su un router Cisco che utilizza l’IOS XR, mostra le etichette locali e remote di un LSP MPLS di tipo P2MP realizzato via mLDP, sul LSR di transito B della figura sopra:
RP/0/1/CPU0:LSR-B# show mpls mldp database
Wed Oct 14 10:24:45.204 UTC
mLDP database
LSM-ID: 0x00006 Type: P2MP Uptime: 1w1d
FEC Root : 10.0.0.1
Opaque decoded : [vpnv4 3269:1 192.168.0.1 232.1.2.3]
Upstream neighbor(s) :
10.0.0.1:0 [Active] Uptime: 1w1d
Next Hop : 10.0.1.1
Interface : GigabitEthernet0/2/1/1
Local Label (D) : 70
Downstream client(s):
LDP 10.0.0.3:0 Uptime: 1w1d
Next Hop : 10.0.3.1
Interface : GigabitEthernet0/2/1/2
Remote label (D) : 30
LDP 10.0.0.4:0 Uptime: 1w1d
Next Hop : 10.0.4.1
Interface : GigabitEthernet0/2/1/3
Remote label (D) : 70
La visualizzazione mostra, tra le altre informazioni, le etichette MPLS locale (= 70) e remote (30 ricevuta dal LSR D e 70 ricevuta dal LSR C), che vengono successivamente utilizzate sul piano dati. Questo significa che quando il LSR B riceve un pacchetto MPLS con etichetta 70, il pacchetto verrà replicato sulle due interfacce Gi0/2/1/2 e Gi0/2/1/3 con etichette MPLS rispettivamente 30 e 70.
LSP DI TIPO MP2MP
I LSP di tipo MP2MP sono l’equivalente del servizio PIM-BiDir nel routing multicast. Poiché il PIM-BiDir potrebbe non essere familiare a molti, prima di mostrare come realizzare LSP di MP2MP voglio spendere due parole su questa variante del protocollo PIM.
********* NOTA CULTURALE: DUE PAROLE SUL PIM-BIDIR *********
Il PIM-BiDir è forse la variante meno nota del protocollo PIM. Tutti conosciamo il PIM-DM (PIM – Dense Mode), il PIM-SM (PIM – Sparse Mode) e il PIM-SSM (PIM – Source Specific Multicast). Le ultime due varianti sono quelle più adottate nelle applicazioni pratiche. Tutte queste varianti hanno la loro naturale applicazione in scenari con poche sorgenti e molti ricevitori. PIM-BiDir (PIM – BiDirectional) è stato invece sviluppato per scenari dove ogni host può essere al contempo sorgente e ricevitore di traffico multicast. Un classico esempio è il servizio di videoconferenza, dove ciascun host al tempo stesso invia e riceve il segnale video/audio. Lo svantaggio di utilizzare PIM-SM in un simile scenario è che le tabelle di routing multicast conterrebbero molti stati, sia di tipo (S, G) che di tipo (*, G). Con il PIM BiDir invece, vengono solo costruiti stati di tipo (*, G).
Un’altra differenza fondamentale tra PIM-SM e PIM-BiDir è che mentre con PIM-SM il traffico fluisce dalle sorgenti verso Rendezvous-Point (RP) e da questo verso i ricevitori (solo successivamente il traffico fluisce sull’albero ottimizzato con radice il router che riceve dalla sorgente il traffico multicast), con PIM-BiDir il traffico multicast fluisce su uno spanning-tree (simile a quello costruito nelle reti L2 Switched, ma per fortuna qui non ci sono porte nello stato blocking !) che ha come radice il RP. In altre parole, con PIM-BiDir il traffico multicast fluisce sia nella direzione downstream, ossia dal RP verso i ricevitori, che in direzione upstream, ossia nella direzione opposta. Vi sono altri dettagli importanti che differenziano PIM-SM da PIM-BiDir (es. assenza del Reverse Path Forwarding, assenza della registrazione delle sorgenti, e altro), ma per quanto diremo sui LSP MPLS di tipo MP2MP, è sufficiente quanto ho detto sin qui, in particolare la modalità con cui il traffico viaggia sull’albero multicast (di tipo condiviso).
********* FINE NOTA CULTURALE *********
La realizzazione di un LSP MPLS di tipo MP2MP si basa sulla presenza di un nodo radice, scelto a piacere e identificato da un indirizzo IP (tipicamente un indirizzo di loopback). Oltre al nodo radice, il LSP, al pari di quanto visto per i LSP di tipo P2MP, è identificato anche qui da un valore “opaco”. Un LSP di tipo MP2MP è quindi identificato dalla coppia <IP-radice ; Valore Opaco>.
L’aspetto interessante è la procedura di realizzazione del LSP, ossia l’allocazione delle etichette MPLS e la creazione degli entry della tabella di forwarding MPLS (la LFIB !). Un LSP MPLS di tipo MP2MP può essere pensato come costituito da due sezioni, downstream e upstream. La sezione downstream è identica a quella vista sopra per i LSP di tipo MP2MP, mentre la sezione upstream è costituita da un classico LSP MP2P. Per capire meglio il funzionamento, è bene prima chiarire i concetti di direzione downstream e upstream del traffico che scorre sul LSP. La direzione downstream è quella dal nodo radice verso i nodi foglia, al contrario, la direzione upstream è quella dai nodi foglia verso il nodo radice.
Vediamo con un esempio come avviene la segnalazione. I messaggi LDP Label Mapping utilizzano i due moduli “MP2MP DOWNSTREAM FEC TLV” e “MP2MP UPSTREAM FEC TLV” , che hanno formato identico al modulo “P2MP FEC TLV” visto sopra, cambia solo il campo “Type”, che per il modulo “MP2MP DOWNSTREAM FEC TLV” è pari a 0x08 e per il modulo “MP2MP UPSTREAM FEC TLV” è invece pari a 0x07.
La figura seguente riporta il flusso dei messaggi LDP Label Mapping per la sezione downstream (parte (a) della figura) e per la sezione upstream (parte (b) della figura).
(a)
(b)
Si noti che la sezione upstream altro non è che la classica segnalazione di LSP MPLS unicast, tutti convergenti verso lo stesso LSR di uscita (per questo il LSP MPLS risultante viene detto Multipoint-to-Point, MP2P). Per vederlo, il lettore può divertirsi a ruotare la figura nella parte (b) di 90° in senso orario e ritroverà la classica segnalazione di LSP MPLS unicast, con i messaggi LABEL MAPPING che partono da più LSR di ingresso (nella figura D, C ed E) e si propagano fino al nodo radice (nella figura il LSR A).
Il piano dati a questo punto è semplice. Supponendo che da un LSR foglia parta un pacchetto MPLS destinato a tutti gli altri LSR foglia, questo seguirà un percorso nella direzione upstream (ossia, verso il nodo radice) fino a che non incontra un punto di diramazione verso un nodo foglia, dopodiché seguirà il percorso verso il nodo foglia in direzione downstream. Le etichette MPLS utilizzate nella direzione upstream sono quelle annunciate nei messaggi LDP LABEL MAPPING contenenti il modulo “MP2MP UPSTREAM FEC TLV” e analogamente, le etichette MPLS utilizzate nella direzione upstream sono quelle annunciate nei messaggi LDP LABEL MAPPING contenenti il modulo “MP2MP DOWNSTREAM FEC TLV”
La figura seguente riporta un esempio, che fa riferimento alle etichette annunciate nelle figure precedenti.
Lascio al lettore la verifica della correttezza delle etichette MPLS utilizzate.
Per chiudere, anche qui per fare un esempio pratico, il comando di tipo “show” seguente, eseguito su un router Cisco che utilizza l’IOS XR, mostra le etichette locali e remote di un LSP MPLS di tipo MP2MP realizzato via mLDP, sul LSR di transito B della figura sopra:
RP/0/1/CPU0:LSR-B# show mpls mldp database
Wed Oct 14 11:32:14.155 UTC
LSM-ID: 0x00001 Type: MP2MP Uptime: 1w2d
FEC Root : 10.0.0.1
Opaque decoded : [mdt 3269:1 0]
Upstream neighbor(s) :
10.0.0.1:0 [Active] Uptime: 1w2d
Next Hop : 10.0.1.1
Interface : GigabitEthernet0/2/1/1
Local Label (D) : 50 Remote Label (U): 40
Downstream client(s):
LDP 10.0.0.3:0 Uptime: 1w2d
Next Hop : 10.0.3.1
Interface : GigabitEthernet0/2/1/2
Remote label (D) : 70 Local label (U) : 70
LDP 10.0.0.4:0 Uptime: 1w2d
Next Hop : 10.0.4.1
Interface : GigabitEthernet0/2/1/3
Remote label (D) : 70 Local label (U) : 60
RSVP-TE o mLDP ?
Vi sono molte differenze tra la segnalazione di LSP MPLS multipoint via RSVP-TE o via mLDP, tra cui le più importanti sono:
- Con RSVP-TE la segnalazione è iniziata dal PE radice attraverso messaggi PATH e i PE downstream rispondono con messaggi RESV. Con mLDP la segnalazione è iniziata dai PE downstream, che inviano verso il PE radice messaggi Label Mapping.
- In RSVP-TE la segnalazione viene ripetuta periodicamente (soft state) mentre con mLDP è “una tantum” (hard state).
- Con RSVP-TE è possibile sfruttare le tecniche MPLS di Fast-ReRouting per proteggere traffico dalla caduta di un link e/o nodo, mentre con mLDP lo stesso risultato si può raggiungere attraverso la funzionalità di LFA (Loop Free Alternate) tipica dei protocolli IGP Link State (OSPF, IS-IS).
- Sul piano di controllo RSVP-TE utilizza dei sub-LSP P2P, mentre mLDP è di tipo P2MP o MP2MP.
- Il piano dati è sempre P2MP per RSVP-TE e P2MP o MP2MP per mLDP.
Oltre a quanto mostrato nella figura, vi è anche un ulteriore aspetto da tener presente. Quando un PE foglia non ha più ricevitori interessati al gruppo multicast il cui traffico utilizza un albero Selective, con RSVP-TE deve inviare in direzione upstream fino al PE radice, un messaggio RESVTEAR. Questo messaggio deve quindi attraversare tutta la rete fino al PE radice. Per contro, con mLDP è sufficiente un semplice messaggio LABEL WITHDRAW fino al LDP peer adiacente, per raggiungere lo stesso risultato.
Nelle applicazione alle MVPN ricordo inoltre che con l’utilizzo di mLDP, nella creazione di alberi (P-tunnel) di tipo Selective non è necessario utilizzare annunci MCAST-VPN Leaf A-D. Questo perché con mLDP la segnalazione è iniziata dai PE downstream.
CONCLUSIONI
In questo post ho illustrato l’estensione del protocolo LDP nota come mLDP (multipoint LDP), che consente la realizzazione di LSP MPLS sia di tipo P2MP che di tipo MP2MP. Nel post ho anche fatto un confronto tra i due tipi di segnalazione mLDP e RSVP-TE, mettendo in luce le differenze, vantaggi e svantaggi dell’una e dell’altra.
Io ho la personale opinione che la segnalazione mLDP sia più semplice e meno dispendiosa. E questo mi fa ritornare in mente una cosa vecchia: ma non era forse preferibile il CR-LDP a RSVP-TE ? (NOTA (per i più giovani): CR-LDP era una estensione di LDP per la segnalazione di percorsi MPLS Explicitly Routed, meglio noti come tunnel MPLS-TE. Purtroppo IETF (spinta da Cisco) preferì a suo tempo sviluppare per questo scopo RSVP-TE, congelando lo sviluppo di CR-LDP, che oggi non è più supportato da alcun costruttore).
Ricordo che per chi volesse approfondire queste tematiche, abbiamo nel catalogo corsi della Reiss Romoli, un corso ad hoc di due giorni sul modello NG-MVPN (IPN269, Next Generation Multicast VPN), dove l’argomento dei LSP MPLS multipoint viene trattato con dovizia di particolari e dove sono previste esercitazioni con piattaforme Juniper.
Pubblicato in
ReissBlog
Etichettato sotto
Il tuo IPv4: 216.73.216.37
Newsletter
